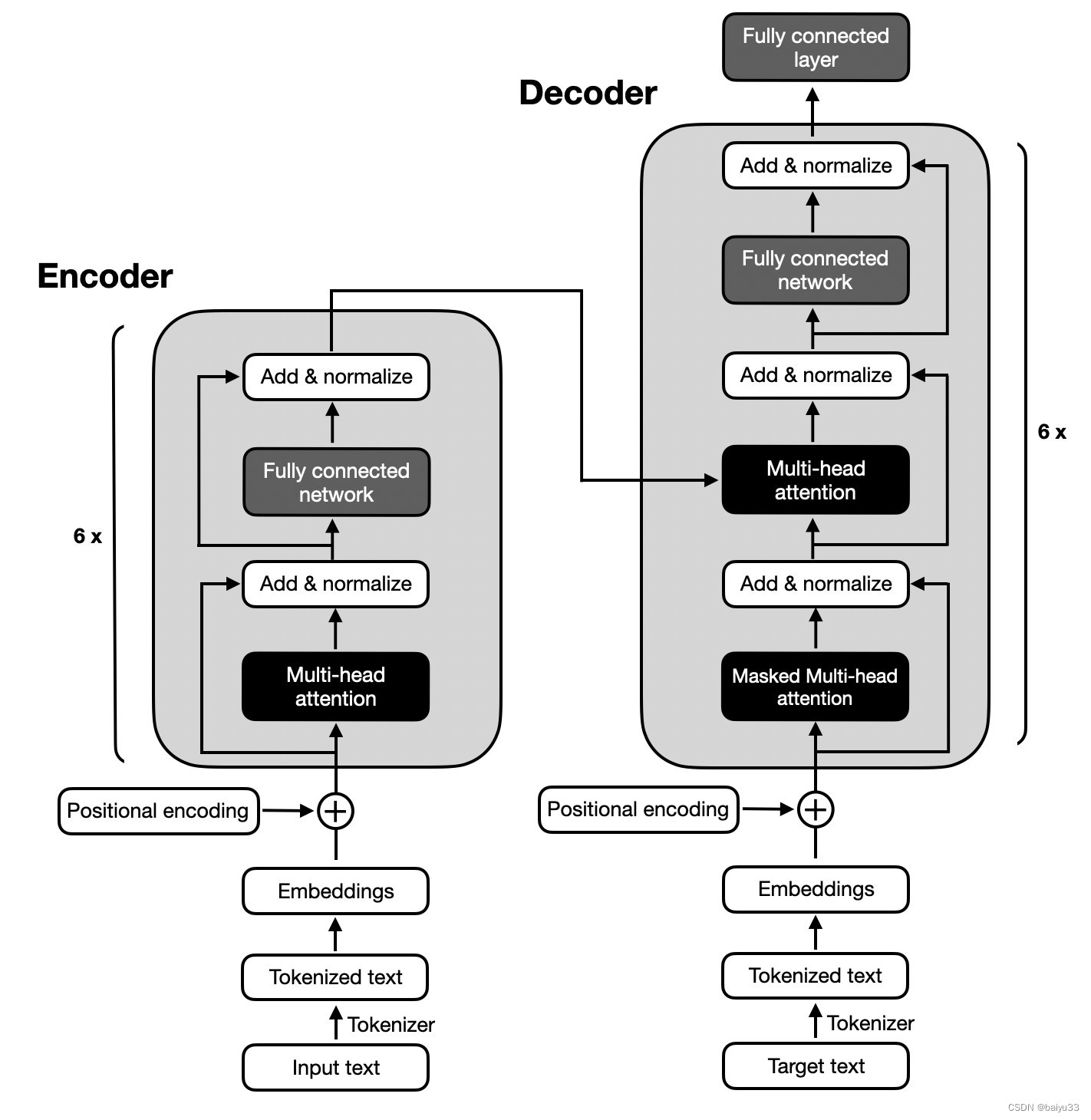
简介
Encoder和Decoder共同组成transfomer,分别对应图中左右浅绿色框内的部分.

Encoder:
目的:将输入的特征图转换为一系列自注意力的输出。
工作原理:首先,通过卷积神经网络(CNN)提取输入图像的特征。然后,这些特征通过一系列自注意力的变换层进行处理,每个变换层都会将特征映射进行编码并产生一个新的特征映射。这个过程旨在捕捉图像中的空间和通道依赖关系。
作用:通过处理输入特征,提取图像特征并进行自注意力操作,为后续的目标检测任务提供必要的特征信息。
Decoder:
目的:接受Encoder的输出,并生成对目标类别和边界框的预测。
工作原理:首先,它接收Encoder的输出,然后使用一系列解码器层对目标对象之间的关系和全局图像上下文进行推理。这些解码器层将最终的目标类别和边界框的预测作为输出。
作用:基于Encoder的输出和全局上下文信息,生成目标类别和边界框的预测结果。
总结:Encoder就是特征提取类似卷积;Decoder用于生成box,类似head
源码实现:
Encoder 通常是6个encoder_layer组成,Decoder 通常是6个decoder_layer组成
我实现了核心的BaseTransformerLayer层,可以用来定义encoder_layer和decoder_layer
具体源码及其注释如下,配好环境可直接运行(运行依赖于上一个博客的代码):
具体流程说明:
Encoder 通常是6个encoder_layer组成,每个encoder_layer[‘self_attn’, ‘norm’, ‘ffn’, ‘norm’]
Decoder 通常是6个decoder_layer组成,每个decoder_layer[‘self_attn’, ‘norm’, ‘cross_attn’, ‘norm’, ‘ffn’, ‘norm’]
按照以上方式搭建网络即可
其中norm为LayerNorm,在样本内部进行归一化。