Generative Adversarial Nets由伊恩·古德费洛(Ian J.Goodfellow)等人于2014年发表在Conference on Neural Information Processing Systems (NeurIPS)上。NeurIPS是机器学习和计算神经科学领域的顶级国际学术会议之一。
1. GAN在哪些领域大放异彩
图像生成:
论文地址:styleGAN styleGAN2
图像生成是生成模型的基本问题,GAN相对先前的生成模型能够生成更高图像质量的图像。如生成逼真的人脸图像。https://thispersondoesnotexist.com是一个叫做‘这个人不存在’的网站,它是基于GAN的一个随机人脸生成网站,每次刷新该网站都将生成一个不同的人脸。

图像超分辨率
论文地址:SRGAN
将图像放大时,图片会变得模糊。使用GAN将32*32的图像扩展为64*64的真实图像,放大图像的同时提升图片的分辨率。

图像转化:
论文地址:CycleGAN
CycleGAN,即循环生成对抗网络,出自发表于 ICCV17 的论文《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,和它的兄长Pix2Pix(均为朱大神作品)一样,用于图像风格迁移任务。以前的GAN都是单向生成,CycleGAN为了突破Pix2Pix对数据集图片一一对应的限制,采用了双向循环生成的结构,因此得名CycleGAN。

其他GAN领域
生成对抗网络(GANs)在多个领域都取得了显著的成就,其灵活性和强大的生成能力使其能够应用于各种应用。
-
图像生成与转换:
- pix2pix 和 CycleGAN: 用于图像转换,例如风格迁移、图片翻译等。
- StyleGAN 和 ProGAN: 生成高分辨率逼真的图像,用于人脸合成和自然图像生成。
-
人脸生成和编辑:
- DeepFake 技术: 使用 GANs 进行逼真的人脸合成。
- StarGAN 和 Age-cGAN: 实现多领域的人脸编辑,如年龄、性别、表情等。
-
图像修复和超分辨率:
- Super-Resolution GANs(SRGAN): 用于提高图像的分辨率。
- Deep Image Prior: 利用 GANs 进行图像修复。
-
生成式艺术:
- Artbreeder: 利用 GANs 进行创造性的艺术生成,探索图像合成的艺术应用。
-
医学图像生成与分割:
- 生成医学图像: GANs 用于生成具有各种病例特征的医学图像,用于培训机器学习模型。
- 图像分割: 利用 GANs 进行医学图像的分割和增强。
-
风格迁移和设计:
- Neural Style Transfer: 使用 GANs 进行艺术风格的图像转换。
- FashionGAN: 用于时尚设计和生成。
-
文本生成:
- Text-to-Image Synthesis: GANs 用于将文本描述转换为图像。
- Conditional GANs: 用于生成与给定文本描述相关的图像。
-
无监督学习和数据增强:
- 生成无监督特征: GANs 用于学习无监督的特征表示。
- 数据增强: GANs 用于生成额外的训练数据,提高监督学习模型的性能。
其他GAN论文
-
pix2pix: https://affinelayer.com/pixsrv/
-
pix2pix HD:https://tcwang0509.github.io/pix2pixHD/
-
stackGAN: https://arxiv.org/pdf/1612.03242.pdf
-
AttnGAN:https://arxiv.org/abs/1711.10485
-
Age-cGAN:https://arxiv.org/pdf/1702.01983.pdf
-
StarGAN:https://arxiv.org/abs/1711.09020
-
Image Inpainting:https://arxiv.org/abs/1804.07723
-
MaskGAN:https://arxiv.org/abs/1801.07736
GAN工作原理
生成对抗网络(GAN)由两个主要部分组成:生成器(Generator)和判别器(Discriminator)。这两个部分通过对抗的方式共同学习,使得生成器能够生成逼真的数据,而判别器能够区分真实数据和生成器生成的数据。
生成器
在统计学眼中,整个世界是通过采样各种不同的分布得到的。
生成模型:对整个数据的分布进行建模,使得能够生成各种分布。
生成图片、生成文本、生成各种东西就是去抓住整个数据的一个分布。
生成器(Generator):
- 生成器的目标是生成看起来像真实数据的样本。
- 它接收一个随机噪声向量(通常是从正态分布中采样得到的)作为输入,并通过神经网络生成数据。
- 生成器的目标是欺骗判别器,使其无法区分生成的数据和真实数据。
辨别器
判别器(Discriminator):
- 判别器的目标是区分生成器生成的数据和真实数据。
- 它接收真实数据或生成器生成的数据作为输入,并通过神经网络输出一个概率值,表示输入是真实数据的概率。
- 判别器的目标是正确地将真实数据识别为真实,并将生成的数据识别为伪造。
Generative Adversarial Nets Introduction部分
论文提到深度学习的前景是发现丰富的分层模型,这些模型代表了AI应用中遇到的各种数据的概率分布。即深度学习不仅仅是深度神经网络,更多的是对整个数据分布的一个特征的表示。
深度学习在辨别上做的不错,但在生成上的效果不好,难点在于去最大化似然函数时,我们要对概率函数很多近似,近似带来了很大的计算困难。这篇文章的关键是不用近似似然函数而可以用别的方法来得到一个计算上更好的模型
作者在文中做了一个形象的比喻:将生成器比作一个生产假币的造假者,而判别模型类似于警察,试图检测假币。造假者和警察会不断学习,造假者提升自己造假的手段,警察会提升自己判别真假币的能力。最后希望得到这样一个结果:造假者获胜,造的假钱跟真的一样,使得警察无法区分真币假币。
该框架可以针对多种模型和优化算法给出具体的训练算法。在本文中,我们探究了生成模型通过多层感知机传递随机噪声生成样本时的特殊情况,而判别模型也是多层感知机。我们把这种特殊情况称为adversarial nets。在这种情况下,我们可以只使用非常成功的反向传播和dropout算法来训练这两个模型,也可以只使用前向传播从生成模型中采样。不需要任何近似推断或马尔可夫链。
Generative Adversarial Nets Related work部分
在这一部分,作者提到之前的大多数关于深度生成模型的工作:一个是构造出一个分布函数,然后提供参数供其学习,学习出真实的分布,明白其均值、方差到底是什么。一个是不去构造分布函数,而是学一个模型来近似这个分布,但是不知道最后的分布是怎样的,算起来较容易。
随后提到他们观察到的一个结果:对
f
f
f的期望求导,等价于对
f
f
f自己求导。这也就是为什么他们使用误差反向传播的原因。
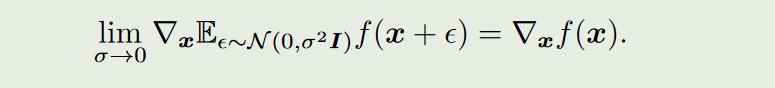
之后作者提到了一些相关的工作,包括VAE、NCE,并解释了与predictability minimization算法的区别
发现这里有总结的较好的,后续可以查看这里:https://blog.csdn.net/qq_45138078/article/details/128366117
Generative Adversarial Nets的缺陷及后续的改进
训练不稳定:外层循环迭代N次直到完成,如何判断是否收敛,这里有两项,一个是往上走(max),一个是往下走(min),有两个模型,所以如何判断收敛并不容易。整体来说,GAN的收敛是非常不稳定的。
判别器训练得太好:在价值函数中,等式右边的第二项存在一定的问题:在早期的时候G比较弱,生成的数据跟真实的数据差得比较远,这就很容易将D训练的特别好(D能够完美地区分开生成的数据和真实的数据),就导致log(1-D(G(z)))会变成0,求梯度再更新G的时候,就会发现求不动了。
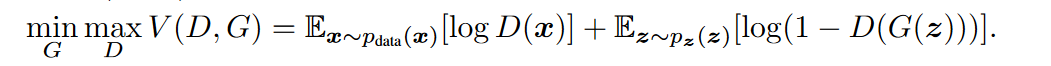
后续论文改进
- Improved Techniques for Training GANs提出了一系列的训练技巧,包括正则化项、生成器和判别器的架构选择等,以提高GAN的训练稳定性和生成样本的质量。
- Wasserstein GAN引入Wasserstein距离(Earth Mover’s Distance)作为GAN的目标函数,通过减小生成分布和真实分布之间的差异,改善了训练的稳定性和生成图像的质量。
- Least Squares Generative Adversarial Networks使用最小二乘损失函数代替原始GAN的二元交叉熵损失,有助于解决训练过程中的模式崩溃问题,提高生成图像的质量。
- Self-Attention Generative Adversarial Networks引入了自注意力机制,使生成器能够更好地捕捉输入数据的长距离依赖关系,提高生成图像的细节和整体质量。
- Training Generative Adversarial Networks with Limited Data针对有限数据情况,提出了一种基于数据增强和迁移学习的方法,以改善生成模型在数据稀缺情况下的性能。
GAN未来及挑战
随着OpenAI发布DALL-E 2,自回归模型和扩散模型一夜之间成为大规模生成模型的新标准,而在此之前,生成对抗网络(GAN)一直都是主流选择,并衍生出StyleGAN等技术。
扩散模型:当前DALL-E, Midjourney, Stable Diffusion图片生成的核心都是Diffusion Model,它就是通过不停去除噪音期望获得好结果的生成模型。
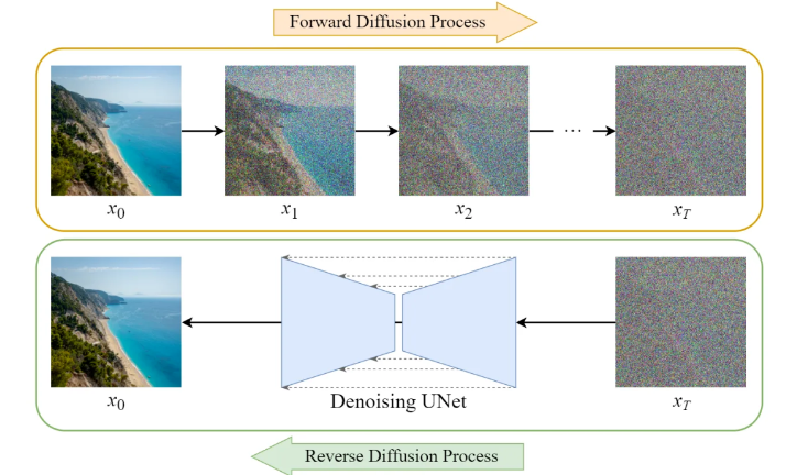
扩散模型只需要训练一个模型,优化过程更加稳定。
扩散模型在条件生成任务上确实要优于GAN,特别是在生成的多样性方面。
扩散模型的训练过程相对简单,优化更为容易。
两阶段扩散模型可以进一步提高生成图片的质量,其效果通常超过了单一的GAN模型
大模型下的GAN-GigaGAN
针对增加StyleGAN架构容量会导致不稳定的问题,来自浦项科技大学(韩国)、卡内基梅隆大学和Adobe研究院的研究人员提出了一种全新的生成对抗网络架构GigaGAN,打破了模型的规模限制,展示了 GAN 仍然可以胜任文本到图像合成模型。(https://arxiv.org/abs/2303.05511)

原文地址:https://blog.csdn.net/qq_45939398/article/details/135502891
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56704.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!



![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)