本文介绍: 如何保证数据库和缓存双写一致性,是面试中经常被问的一个技术问题,程序汪推荐大家有必要好好研究一波数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。我很负责的告诉大家,该问题无论在面试,还是工作中遇到的概率非常大,所以非常有必要跟大家一起探讨一下。今天这篇文章我会从浅入深,跟大家一起聊聊,数据库和缓存双写数据一致性问题常见的解决方案,这些方案中可能存在的坑,以及最优方案是什么。
如何保证数据库和缓存双写一致性,是面试中经常被问的一个技术问题,程序汪推荐大家有必要好好研究一波
数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。
我很负责的告诉大家,该问题无论在面试,还是工作中遇到的概率非常大,所以非常有必要跟大家一起探讨一下。
今天这篇文章我会从浅入深,跟大家一起聊聊,数据库和缓存双写数据一致性问题常见的解决方案,这些方案中可能存在的坑,以及最优方案是什么。
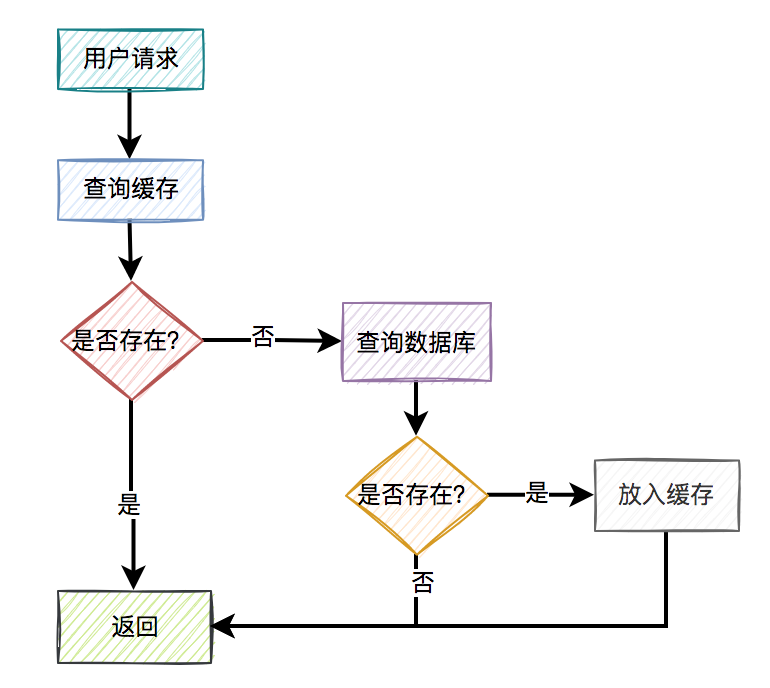
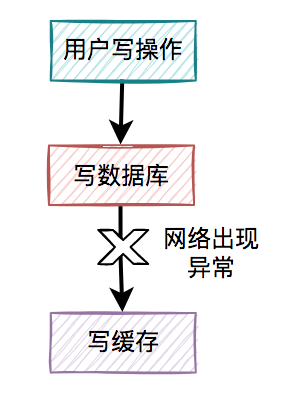
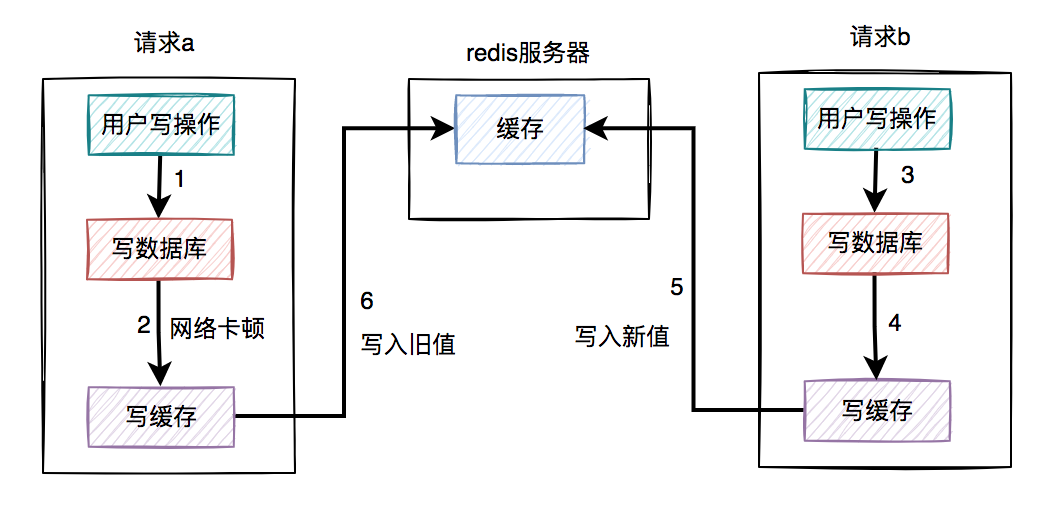
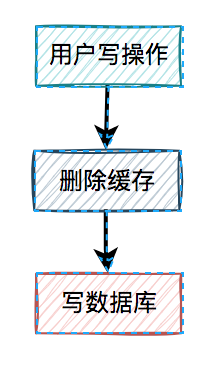
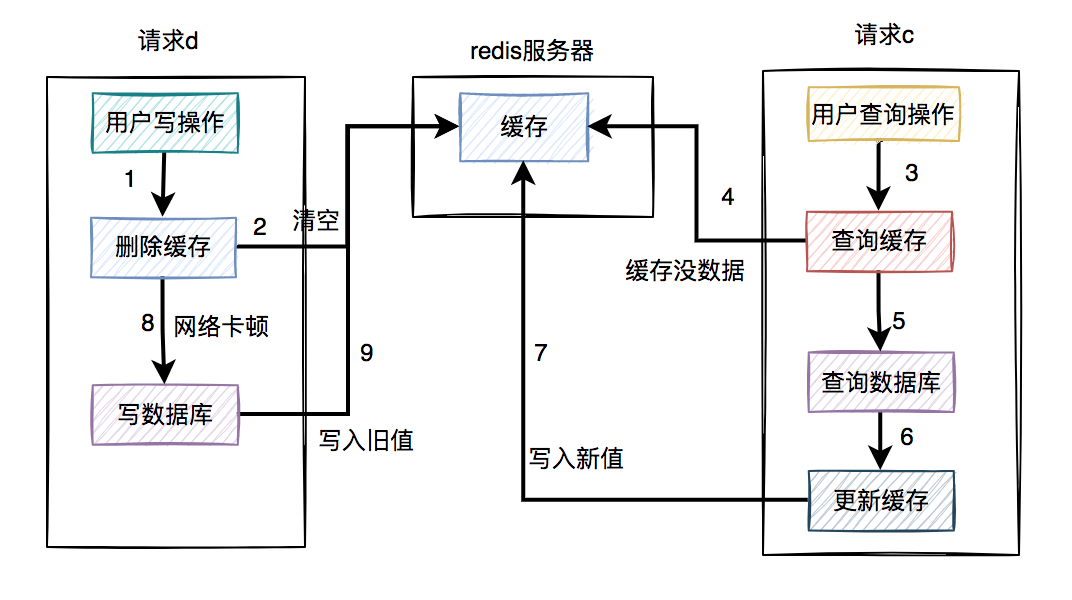
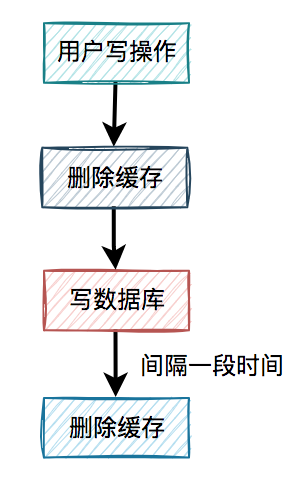
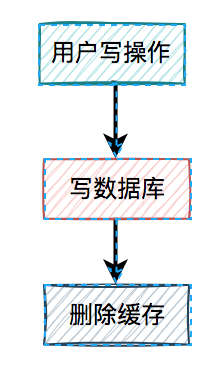
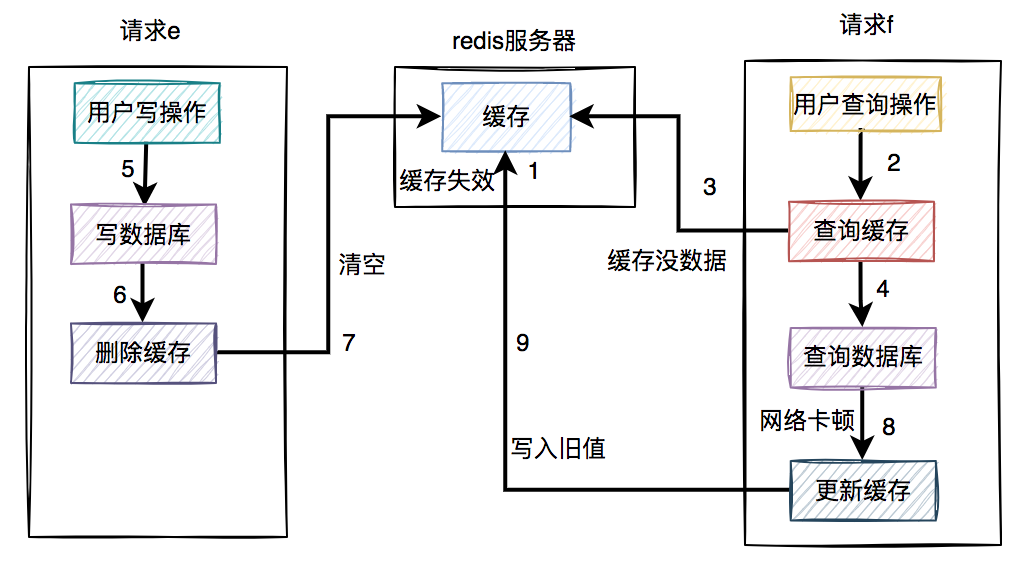
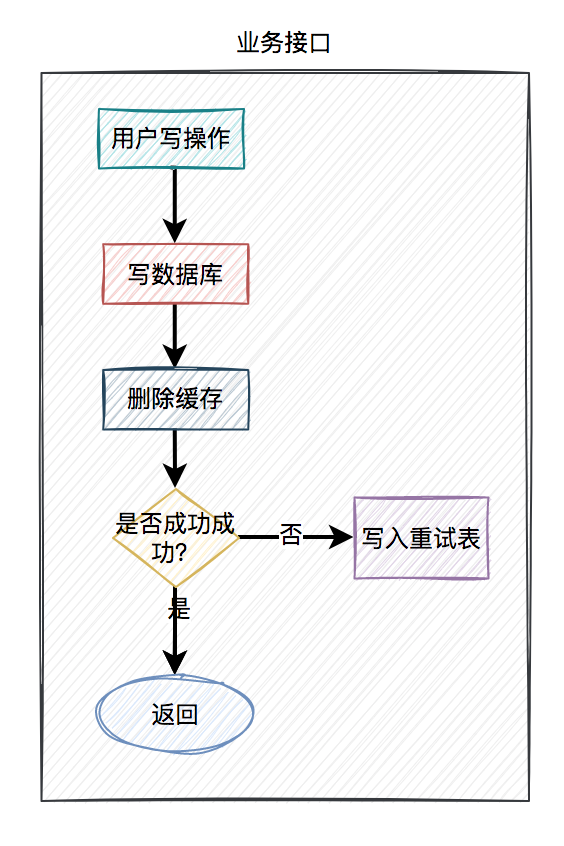
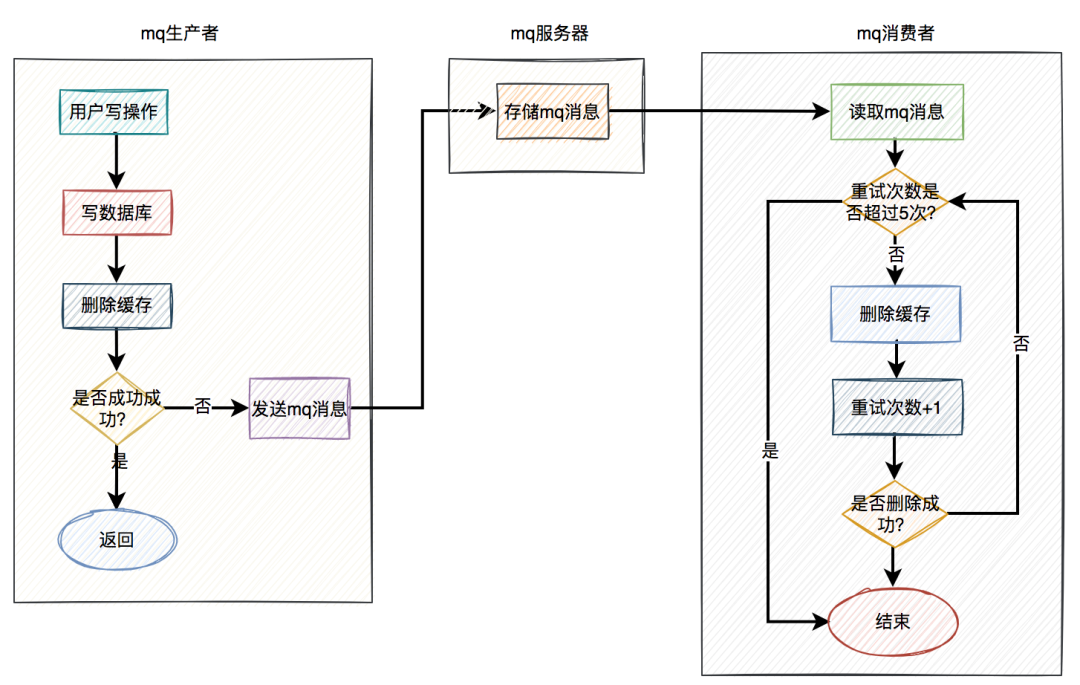
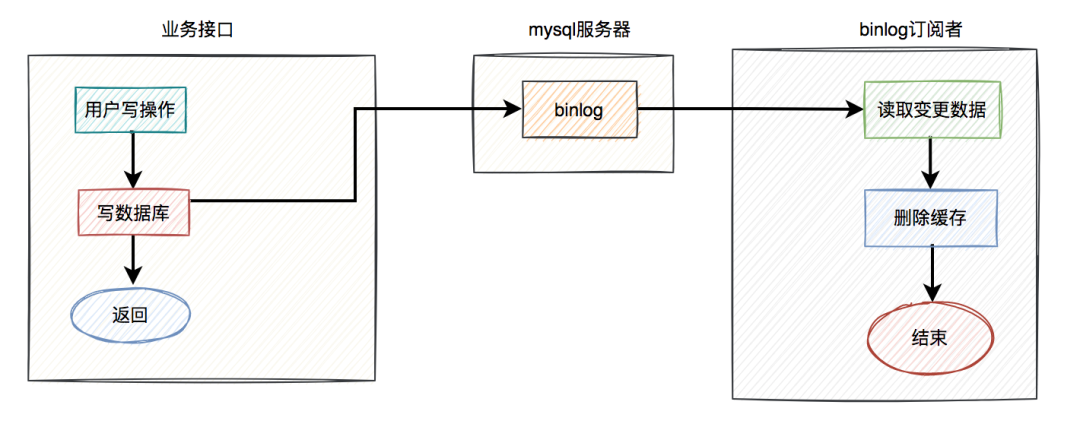
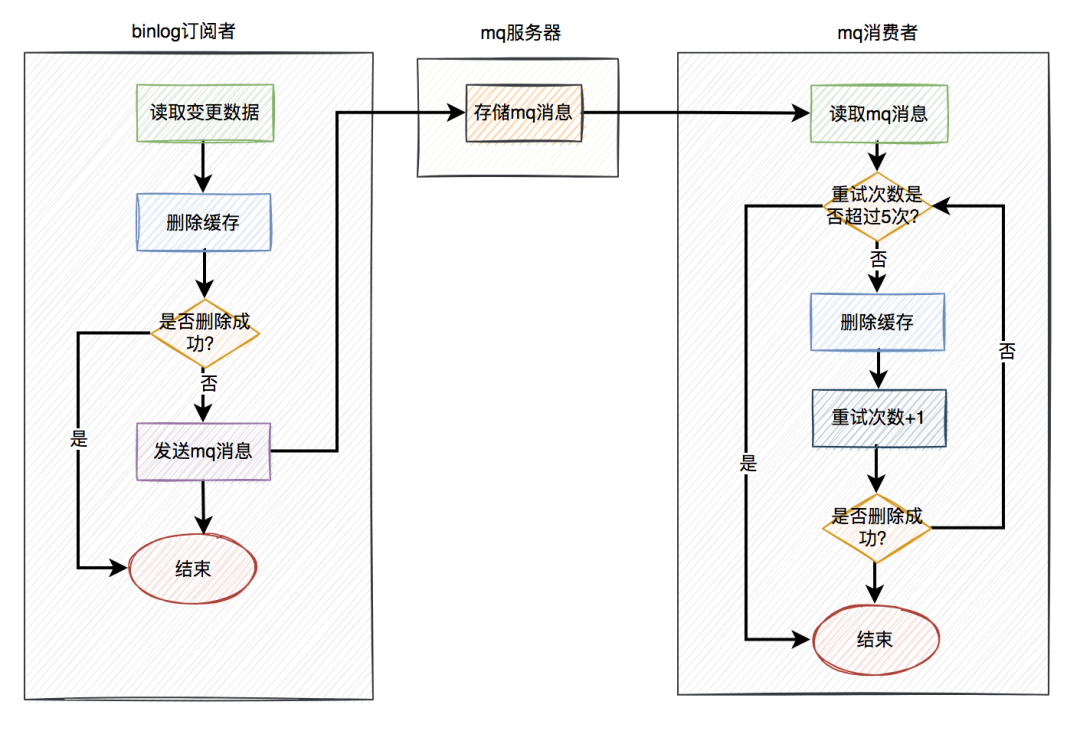
通常情况下,我们使用缓存的主要目的是为了提升查询的性能。大多数情况下,我们是这样使用缓存的:

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



