本文介绍: 总的来说,在崩溃恢复后,只要redo log不是处于commit阶段,那么就拿着redo log中的XID去binlog中寻找,找得到就提交,否则就回滚。可以看到,InnoDB在写redo log时,并不是一次性写完的,而有两个阶段,Prepare与Commit阶段,这就是”两阶段提交“的含义。如果在写入binlog后立马崩溃,在恢复时,由redo log中的XID可以找到对应的binlog,这个时候直接提交即可。首先比较重要的一点是,在写入redo log时,会顺便记录XID,即当前事务id。
先看执行器与InnoDB引擎是如何更新一条指定的数据的
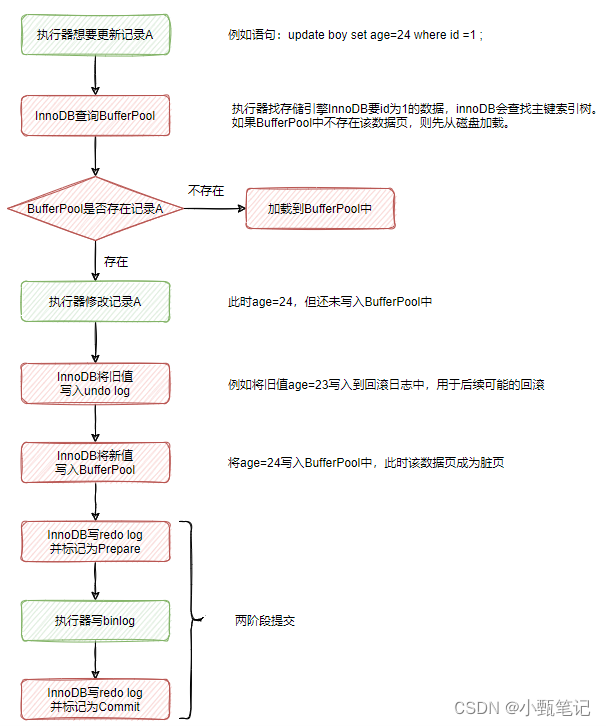
可以看到,InnoDB在写redo log时,并不是一次性写完的,而有两个阶段,Prepare与Commit阶段,这就是”两阶段提交“的含义。
为什么要写redo log,不写redo log的话,根本就不会出现“两阶段提交”的麻烦事啊?
MySQL为了提升性能,引入了BufferPool缓冲池。查询数据时,先从BufferPool中查询,查询不到则从磁盘加载在BufferPool。
每次对数据的更新,也不总是实时刷新到磁盘,而是先同步到BufferPool中,涉及到的数据页就会变成脏页。
为什么要写两次redo log,写一次不行吗?
在两阶段提交的情况下,是怎么实现崩溃恢复的呢?
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。