本文介绍: 积压,到一定程度,会被强制断开,导致消息意外丢失。真正要在生产中应用,要做的事情还很多,比如消息队列的管理和监控就需要花。每个人所感兴趣的事件是不一样的,前台的接待小姐会根据每个人感兴趣的事件。它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系。出异常,所以在编写客户端消费者的时候要小心,如果捕获到异常需要重试。消息一旦发布,不能接收。但是如果并发量很高,资源足够支持下,还是以专业的消息中间件,比如。向反应器注册一个事件处理器,表示自己对某些事件感兴趣,有时间来了,具体。
Redis 队列与 Stream、Redis 6 多线程
详解
Redis 队列与 Stream

每个 Stream
都可以挂多个消费组,每个消费组会有个游标
last_delivered_id
在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费 组都有一个 Stream
内唯一的名称,消费组不会自动创建,它需要单独的指令 xgroup create进行创建,需要指定从
Stream
的某个消息
ID
开始消费,这个ID 用来初始化
last_delivered_id
变量。
都可以挂多个消费组,每个消费组会有个游标
last_delivered_id
在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费 组都有一个 Stream
内唯一的名称,消费组不会自动创建,它需要单独的指令 xgroup create进行创建,需要指定从
Stream
的某个消息
ID
开始消费,这个ID 用来初始化
last_delivered_id
变量。
同一个消费组
(Consumer Group)
可以挂接多个消费者
(Consumer)
,这些消费 者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id
往 前移动。每个消费者有一个组内唯一名称。
(Consumer Group)
可以挂接多个消费者
(Consumer)
,这些消费 者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id
往 前移动。每个消费者有一个组内唯一名称。
消费者 (Consumer)
内部会有个状态变量
pending_ids
,它记录了当前已经被 客户端读取,但是还没有 ack
的消息。如果客户端没有
ack
,这个变量里面的消 息 ID
会越来越多,一旦某个消息被
ack
,它就开始减少。这个
pending_ids
变 量在 Redis
官方被称之为
PEL
,也就是
Pending Entries List
,这是一个很核心的 数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢 失了没处理。
内部会有个状态变量
pending_ids
,它记录了当前已经被 客户端读取,但是还没有 ack
的消息。如果客户端没有
ack
,这个变量里面的消 息 ID
会越来越多,一旦某个消息被
ack
,它就开始减少。这个
pending_ids
变 量在 Redis
官方被称之为
PEL
,也就是
Pending Entries List
,这是一个很核心的 数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢 失了没处理。
消息 ID
的形式是
timestampInMillis-sequence
,例如
1527846880572-5
,它 表示当前的消息在毫米时间戳 1527846880572
时产生,并且是该毫秒内产生的第
5
条消息。消息
ID
可以由服器自动生成,也可以由客户端自己指定,但是形 式必须是整数–
整数,而且必须是后面加入的消息的
ID
要大于前面的消息
ID
。
的形式是
timestampInMillis-sequence
,例如
1527846880572-5
,它 表示当前的消息在毫米时间戳 1527846880572
时产生,并且是该毫秒内产生的第
5
条消息。消息
ID
可以由服器自动生成,也可以由客户端自己指定,但是形 式必须是整数–
整数,而且必须是后面加入的消息的
ID
要大于前面的消息
ID
。
常用操作命令
生产端

streamtest 表示当前这个队列的名字,也就是我们一般意义上
Redis
中的
key
, * 号表示服务器自动生成 ID
,后面顺序跟着“
name mark age 18
”,是我们存入 当前 streamtest
这个队列的消息,采用的也是
key/value
的存储形式
Redis
中的
key
, * 号表示服务器自动生成 ID
,后面顺序跟着“
name mark age 18
”,是我们存入 当前 streamtest
这个队列的消息,采用的也是
key/value
的存储形式
返回值 1626705954593-0
则是生成的消息
ID
,由两部分组成:时间戳
–
序号。 时间戳时毫秒级单位,是生成消息的 Redis
服务器时间,它是个
64
位整型。序 号是在这个毫秒时间点内的消息序号。它也是个 64
位整型。
则是生成的消息
ID
,由两部分组成:时间戳
–
序号。 时间戳时毫秒级单位,是生成消息的 Redis
服务器时间,它是个
64
位整型。序 号是在这个毫秒时间点内的消息序号。它也是个 64
位整型。
为了保证消息是有序的,因此 Redis
生成的
ID
是单调递增有序的。由于
ID 中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延 后了),Redis
的每个
Stream
类型数据都维护一个
latest_generated_id
属性,用 于记录最后一个消息的 ID
。若发现当前时间戳退后(小于
latest_generated_id
所 记录的),则采用时间戳不变而序号递增的方案来作为新消息 ID
(这也是序号 为什么使用 int64
的原因,保证有足够多的的序号),从而保证
ID
的单调递增性
生成的
ID
是单调递增有序的。由于
ID 中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延 后了),Redis
的每个
Stream
类型数据都维护一个
latest_generated_id
属性,用 于记录最后一个消息的 ID
。若发现当前时间戳退后(小于
latest_generated_id
所 记录的),则采用时间戳不变而序号递增的方案来作为新消息 ID
(这也是序号 为什么使用 int64
的原因,保证有足够多的的序号),从而保证
ID
的单调递增性
质。





消费端
单消费者
虽然 Stream
中有消费者组的概念,但是可以在不定义消费组的情况下进行 Stream 消息的独立消费,当
Stream
没有新消息时,甚至可以阻塞等待。
Redis
设 计了一个单独的消费指令 xread
,可以将
Stream
当成普通的消息队列
(list)
来 使用。使用 xread
时,我们可以完全忽略消费组
(Consumer Group)
的存在,就 好比 Stream
就是一个普通的列表
(list)
。
中有消费者组的概念,但是可以在不定义消费组的情况下进行 Stream 消息的独立消费,当
Stream
没有新消息时,甚至可以阻塞等待。
Redis
设 计了一个单独的消费指令 xread
,可以将
Stream
当成普通的消息队列
(list)
来 使用。使用 xread
时,我们可以完全忽略消费组
(Consumer Group)
的存在,就 好比 Stream
就是一个普通的列表
(list)
。
“count 1
”表示从
Stream
读取
1
条消息,缺省当然是头部,“
streams
” 可以理解为 Redis
关键字,“
stream2
”指明了要读取的队列名称,“
0-0
”指从 头开始
”表示从
Stream
读取
1
条消息,缺省当然是头部,“
streams
” 可以理解为 Redis
关键字,“
stream2
”指明了要读取的队列名称,“
0-0
”指从 头开始

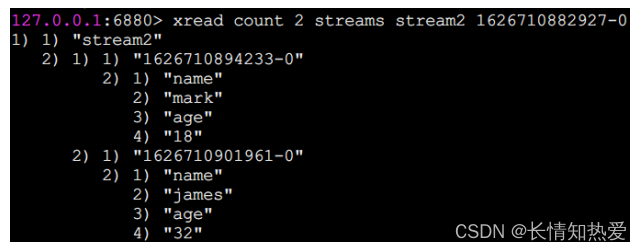




消费组
创建消费组
表示从头开始消费

$
表示从尾部开始消费,只接受新消息,当前
Stream
消息会全部忽略
表示从尾部开始消费,只接受新消息,当前
Stream
消息会全部忽略

xinfo stream stream2


消息消费
它同 xread
一样,也可以阻塞等待新消息。读到新消息后,对应的消息
ID 就会进入消费者的 PEL(
正在处理的消息
)
结构里,客户端处理完毕后使用
xack 指令通知服务器,本条消息已经处理完毕,该消息 ID
就会从
PEL
中移除。
一样,也可以阻塞等待新消息。读到新消息后,对应的消息
ID 就会进入消费者的 PEL(
正在处理的消息
)
结构里,客户端处理完毕后使用
xack 指令通知服务器,本条消息已经处理完毕,该消息 ID
就会从
PEL
中移除。


自然就读取到了下条消息。
我们将
Stream2
中的消息读取完
Stream2
中的消息读取完
xreadgroup GROUP cg1 c1 count 2 streams stream2 >
很自然就没有消息可读了
,
xreadgroup GROUP cg1 c1 count 1 streams
,
xreadgroup GROUP cg1 c1 count 1 streams
stream2 >

xreadgroup GROUP cg1 c1 block 0 count 1 streams stream2 >



我们来观察一下观察消费组状态
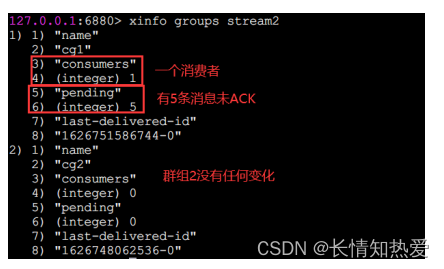
察每个消费者的状态
xinfo consumers stream2 cg1

如果我们确认一条消息
xack stream2 cg1 1626751586744-0
就可以看到待确认消息变成了
4
条
4
条


消息 ID
所属消费者
IDLE,已读取时长
delivery counter,消息被读取次数
读取时长),只有超过这个时长,才能被转移。
Redis 队列几种实现的总结
基于 List 的 LPUSH+BRPOP 的实现
其他缺点包括:
会被删除;不支持分组消费。
基于 Sorted-Set 的实现
无法阻塞的获取消息,只能轮询,不允许重复消息。
PUB/SUB,订阅/发布模式
缺点:
不能寻回;不能保证每个消费者接收的时间是一致的;若消费者客户端出现消息
基于 Stream 类型的实现
与 Java 的集成
消息队列问题
Stream 消息太多怎么办?
又不会删除消息,它只是给消息做了个标志位。
定长度。
消息如果忘记 ACK 会怎样?
能的快速消费并确认。
PEL 如何避免消息丢失?
后的新消息。
死信问题
如果某个消息,不能被消费者处理,也就是不能被 XACK
,这是要长时间处
,这是要长时间处
于
Pending
列表中,即使被反复的转移给各个消费者也是如此。此时该消息的
Pending
列表中,即使被反复的转移给各个消费者也是如此。此时该消息的
设的临界值时,我们就认为是坏消息(也叫死信,
DeadLetter
,无法投递的消息),
DeadLetter
,无法投递的消息),
Stream 的高可用
分区 Partition
Stream 小结
Redis 中的线程和 IO 模型
什么是 Reactor 模式 ?
“反应”器名字中”反应“的由来:
例如,路人甲去做男士 SPA
,前台的接待小姐接待了路人甲,路人甲现在只
,前台的接待小姐接待了路人甲,路人甲现在只
上班了或者是空闲了,通知我。等路人甲接到接待小姐通知,做出了反应,把
10000
技师占住了。
技师占住了。
我现在先和
10000
这个小姐聊下人生,
10000
号房间空出来了,路人甲再次接到
10000
这个小姐聊下人生,
10000
号房间空出来了,路人甲再次接到
接待小姐通知,路人甲再次做出了反应。
趣,其他,比如
10001
号技师或者
10002
号房间空闲了也是事件,但是路人甲不
10001
号技师或者
10002
号房间空闲了也是事件,但是路人甲不
感兴趣。
通知对应的每个人。
单线程 Reactor 模式流程
数据,而不会堵塞与等待可读的数据到来。

单线程 Reactor,工作者线程池

多 Reactor 线程模式
Reactor 线程池中的每一
Reactor
线程都会有自己的
Selector
、线程和分发的
Reactor
线程都会有自己的
Selector
、线程和分发的

Redis 中的线程和 IO 概述
设计为单线程模型。
器来处理对应事件。
下面来看文件事件处理器的几个组成部分。

socket
文件事件。
I/O 多路复用程序
件分派器传送
socket
。
socket
。
序才会向文件事件分派器传送下个
socket
, 如下:
socket
, 如下:
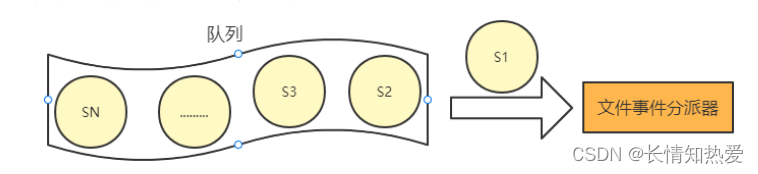
I/O 多路复用程序的实现
列。

注:
epoll = Linux
文件事件分派器
文件事件分派器接收 I/O
多路复用程序传来的
socket
, 并根据
socket
产生
多路复用程序传来的
socket
, 并根据
socket
产生
文件事件处理器
的复制处理器。
文件事件的类型
个
AE_READABLE
事件。
AE_READABLE
事件。
当 socket
可写时(比如客户端对
Redis
执行
read
操作),
socket
会产生一个
可写时(比如客户端对
Redis
执行
read
操作),
socket
会产生一个
AE_WRITABLE
事件。
事件。
I/O 多路复用程序可以同时监听
AE_REABLE
和
AE_WRITABLE
两种事件,要是
AE_REABLE
和
AE_WRITABLE
两种事件,要是
件。即一个
socket
又可读又可写时,
Redis
服务器先读后写
socket
。
socket
又可读又可写时,
Redis
服务器先读后写
socket
。
总结
处理器负责和客户端建立连接,创建客户端对应的
socket
,同时将这个
socket
socket
,同时将这个
socket
命令请求。
当客户端向 Redis
发请求时(不管读还是写请求),客户端
socket
都会产生
发请求时(不管读还是写请求),客户端
socket
都会产生
命令回复处理器全部写完到 socket
后,就会删除该
socket
的
AE_WRITABLE
后,就会删除该
socket
的
AE_WRITABLE
事件和命令回复处理器的映射。
Redis6 中的多线程
1. Redis6.0 之前的版本真的是单线程吗?
除等等。
2. Redis6.0 之前为什么一直不使用多线程?
使用了单线程后,可维护性高。多线程模型虽然在某些方面表现优异,但是
3. Redis6.0 为什么要引入多线程呢?
据包,
Redis
服务器可以处理
80,000
到
100,000 QPS
,这也是
Redis
处理的极限了,
Redis
服务器可以处理
80,000
到
100,000 QPS
,这也是
Redis
处理的极限了,
读
/
写问题;数据偏斜,重新分配和放大
/
缩小变得更加复杂等等。
/
写问题;数据偏斜,重新分配和放大
/
缩小变得更加复杂等等。
式
• 可以充分利用服务器 CPU
资源,目前主线程只能利用一个核
资源,目前主线程只能利用一个核
4.Redis6.0 默认是否开启了多线程?
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改

开启多线程后,还需要设置线程数,否则是不生效的。
5.Redis6.0 采用多线程后,性能的提升效果如何?
耗时的时候才建议采用,否则使用多线程没有意义。
6.Redis6.0 多线程的实现机制?
流程简述如下:
些
IO
线程
IO
线程
3、主线程阻塞等待
IO
线程读取
socket
完毕
IO
线程读取
socket
完毕
并不执行回写
socket
socket
5、主线程阻塞等待
IO
线程将数据回写
socket
完毕
IO
线程将数据回写
socket
完毕
该设计有如下特点:
1、
IO
线程要么同时在读
socket
,要么同时在写,不会同时读或写
IO
线程要么同时在读
socket
,要么同时在写,不会同时读或写
7.开启多线程后,是否会存在线程并发安全问题?
8.Redis6.0 的多线程和 Memcached 多线程模型进行 对比
用连接描述符建立与客户端的
socket
连接 并进行后续的存取数据操作。
socket
连接 并进行后续的存取数据操作。
实现了真正的线程隔离,符合我们对线程隔离的常规理解。而
Redis
把处理逻
Redis
把处理逻
发安全等问题
原文地址:https://blog.csdn.net/weixin_43874650/article/details/134679628
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_5727.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






