本文介绍: python爬虫小练习——爬取豆瓣电影top250,爬取网页内容,解析网页内容,存入表格。
爬取豆瓣电影top250
需求分析
将爬取的数据导入到表格中,方便人为查看。
实现方法
三大功能
1,下载所有网页内容。
2,处理网页中的内容提取自己想要的数据
3,导入到表格中
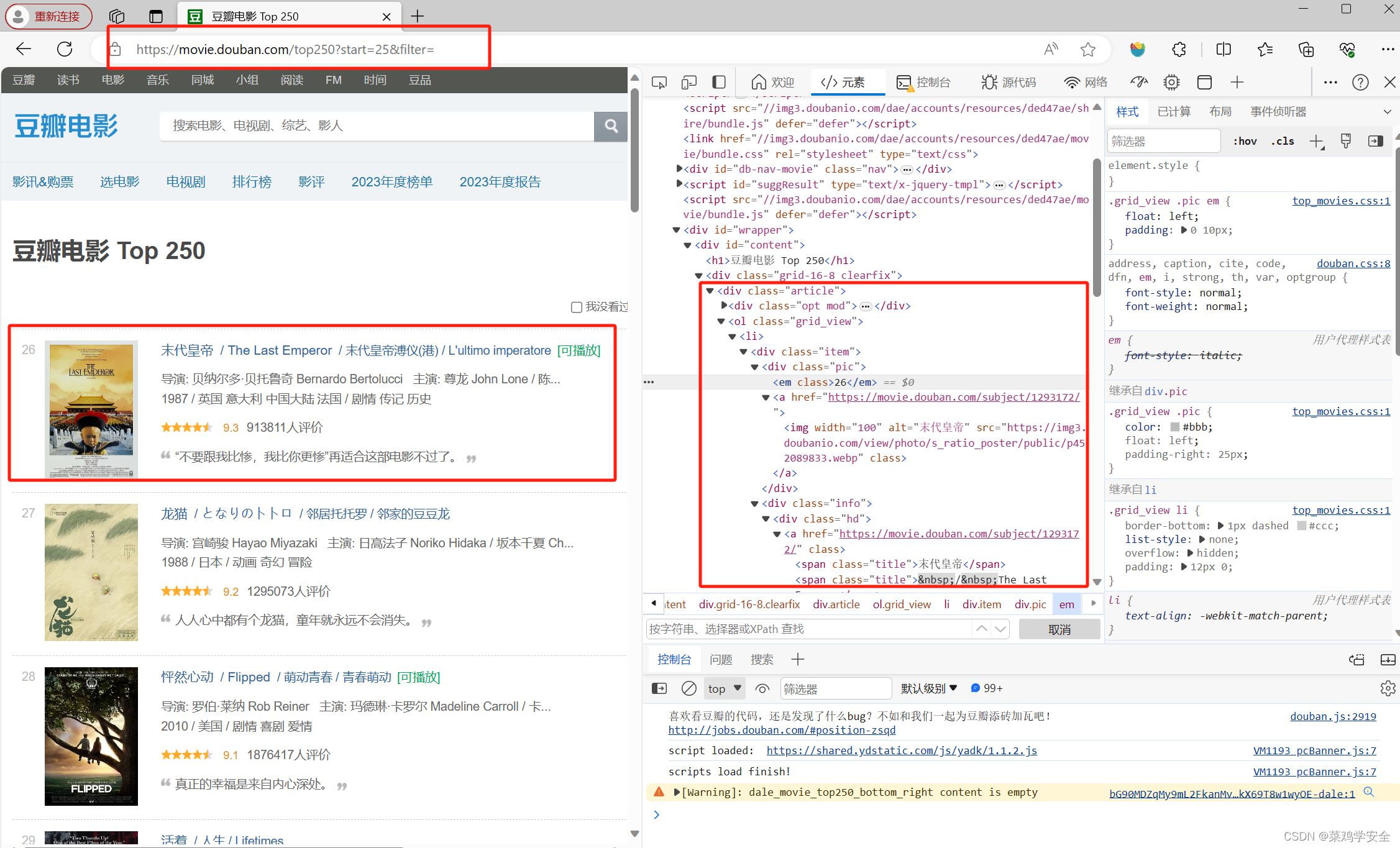
分析网站结构需要提取的内容
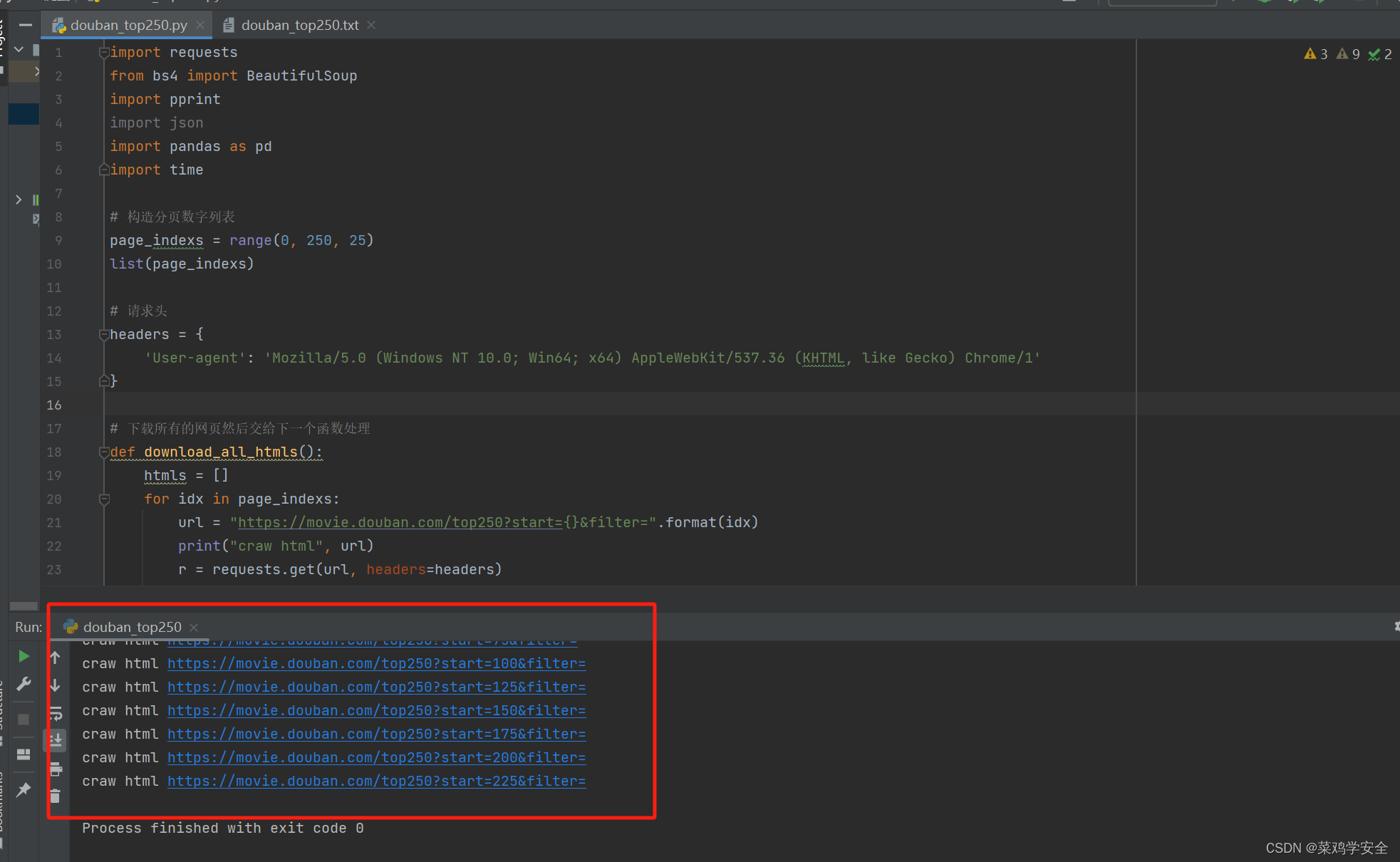
代码
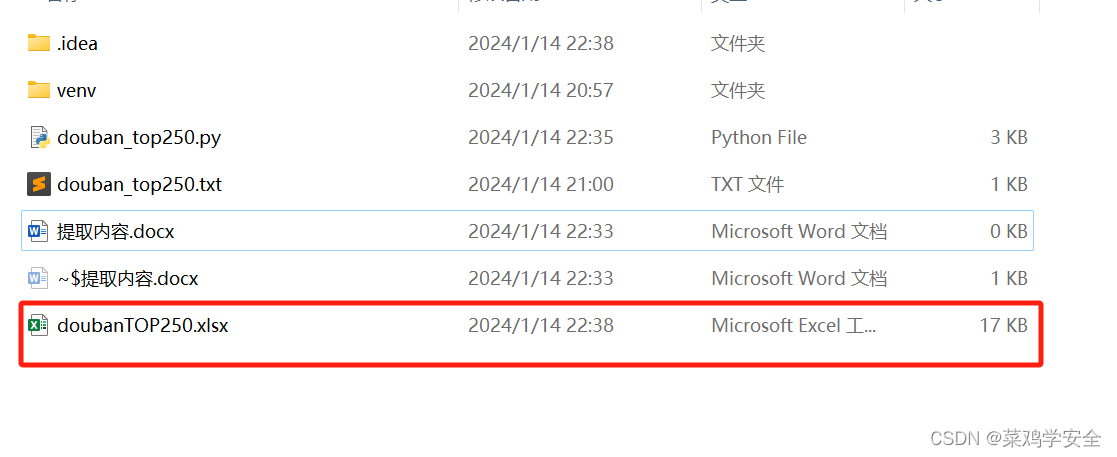
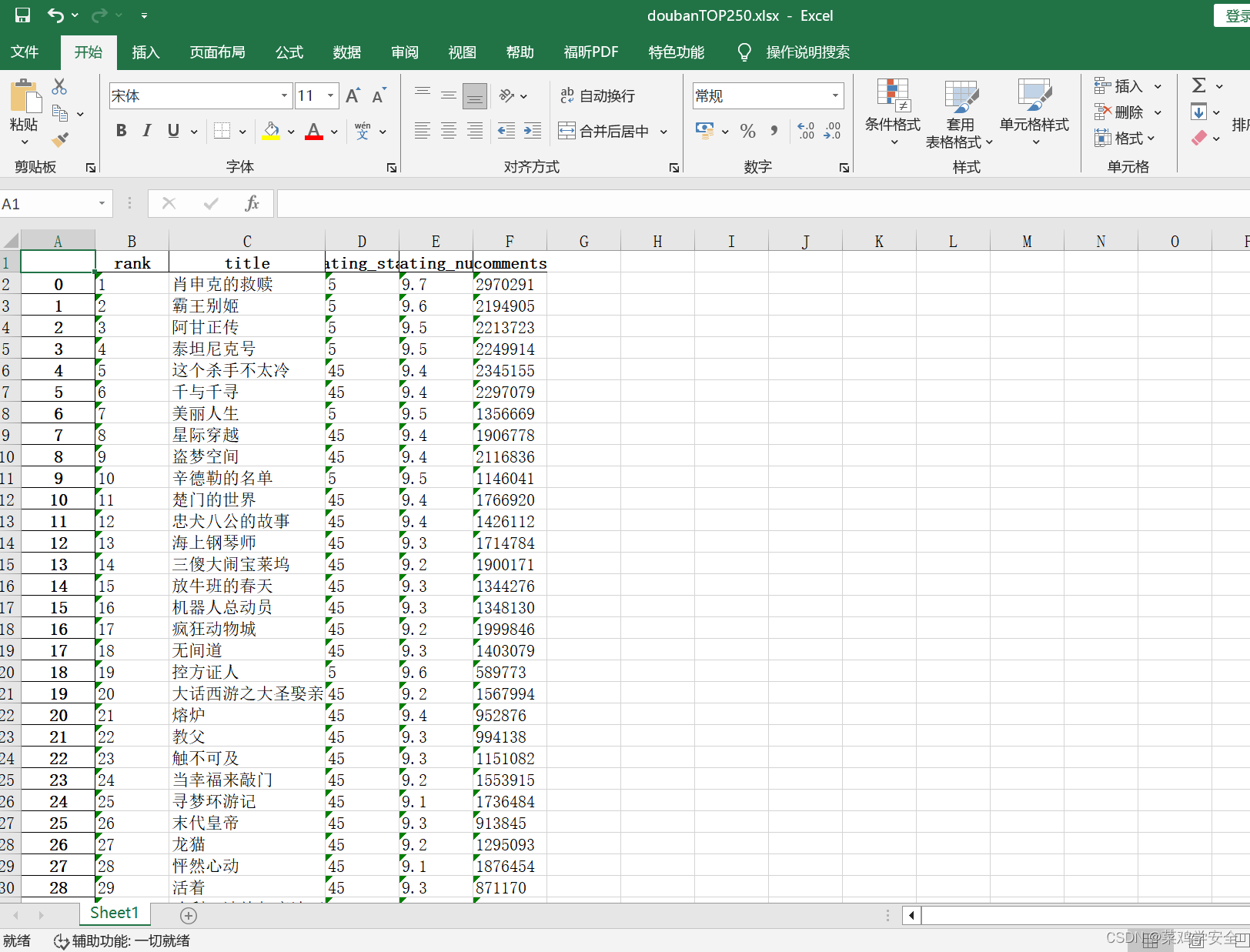
效果图
参考文章
https://www.bilibili.com/video/BV1CY411f7yh/?p=15
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)