本文介绍: Spring框架不仅仅是一个框架,它更像是一个庞大的生态系统,提供了从核心容器、数据访问/集成、Web应用到云服务等全方位的解决方案。Spring的核心是依赖注入(DI)和面向切面编程(AOP),这两个功能让代码更加模块化,易于管理和维护。来,咱们看个简单的例子,理解一下Spring是怎么工作的。想象咱们有个类,它依赖于另一个类。@Service@Autowired看到没有?这里的@Service和@Autowired就是Spring的用法。它们告诉Spring,

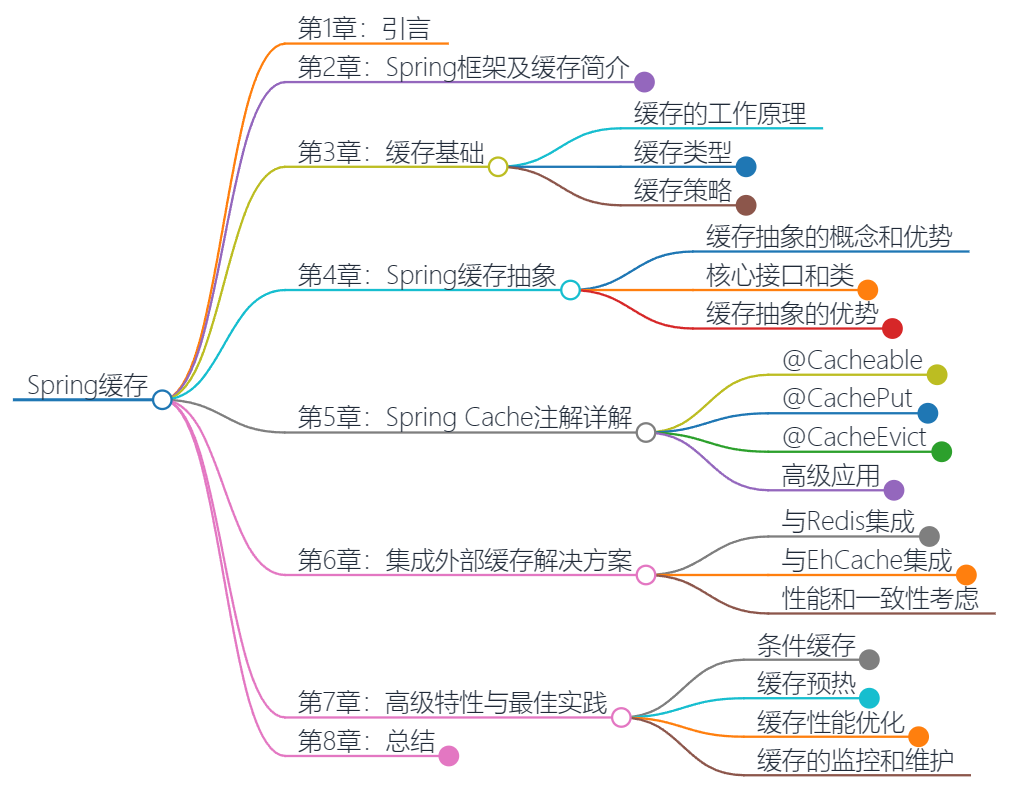
第1章:引言
大家好,我是小黑,咱们今天来聊聊缓存,在Java和Spring里,缓存可是个大角色。咱们在网上购物,每次查看商品详情时,如果服务器都要去数据库里翻箱倒柜,那速度得慢成什么样?这就是缓存发光发热的时刻。缓存就像是服务器的“小抽屉”,把经常用到的数据放在里面,下次需要的时候,直接从“小抽屜”里拿,快得多。
缓存的概念很简单,但深入了解它的工作原理,对提升咱们应用的性能有巨大的帮助。缓存减少了数据库的压力,提高了响应速度,是高性能应用不可或缺的部分。
Spring提供了一套优雅的缓存抽象,让咱们不仅可以轻松地实现缓存,还能方便地切换不同的缓存方案。这意味着,咱们只需要简单的配置,就可以享受到缓存带来的种种好处。
第2章:Spring框架及缓存简介
Spring框架不仅仅是一个框架,它更像是一个庞大的生态系统,提供了从核心容器、数据访问/集成、Web应用到云服务等全方位的解决方案。Spring的核心是依赖注入(DI)和面向切面编程(AOP),这两个功能让代码更加模块化,易于管理和维护。
第3章:缓存基础
缓存的工作原理
缓存类型
缓存策略
第4章:Spring缓存抽象
缓存抽象的概念和优势
核心接口和类
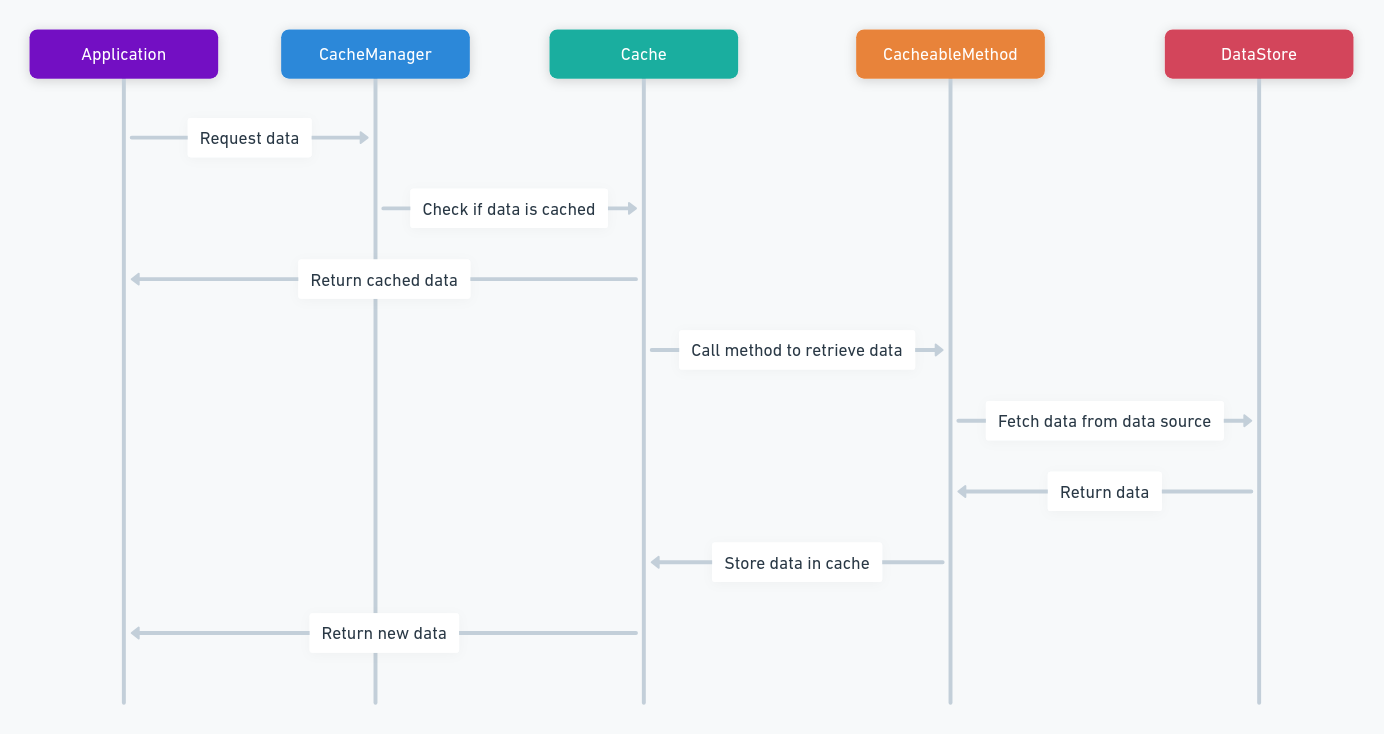
缓存抽象的优势
第5章:Spring Cache注解详解
@Cacheable
@CachePut
@CacheEvict
高级应用
第6章:集成外部缓存解决方案
与Redis集成
与EhCache集成
性能和一致性考虑
第7章:高级特性与最佳实践
条件缓存
缓存预热
缓存性能优化
缓存的监控和维护
第8章:总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。