本文介绍: :对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是。虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
elasticsearch的作用
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容 。
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
elasticsearch和lucene
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:Apache Lucene – Welcome to Apache Lucene 。

倒排索引

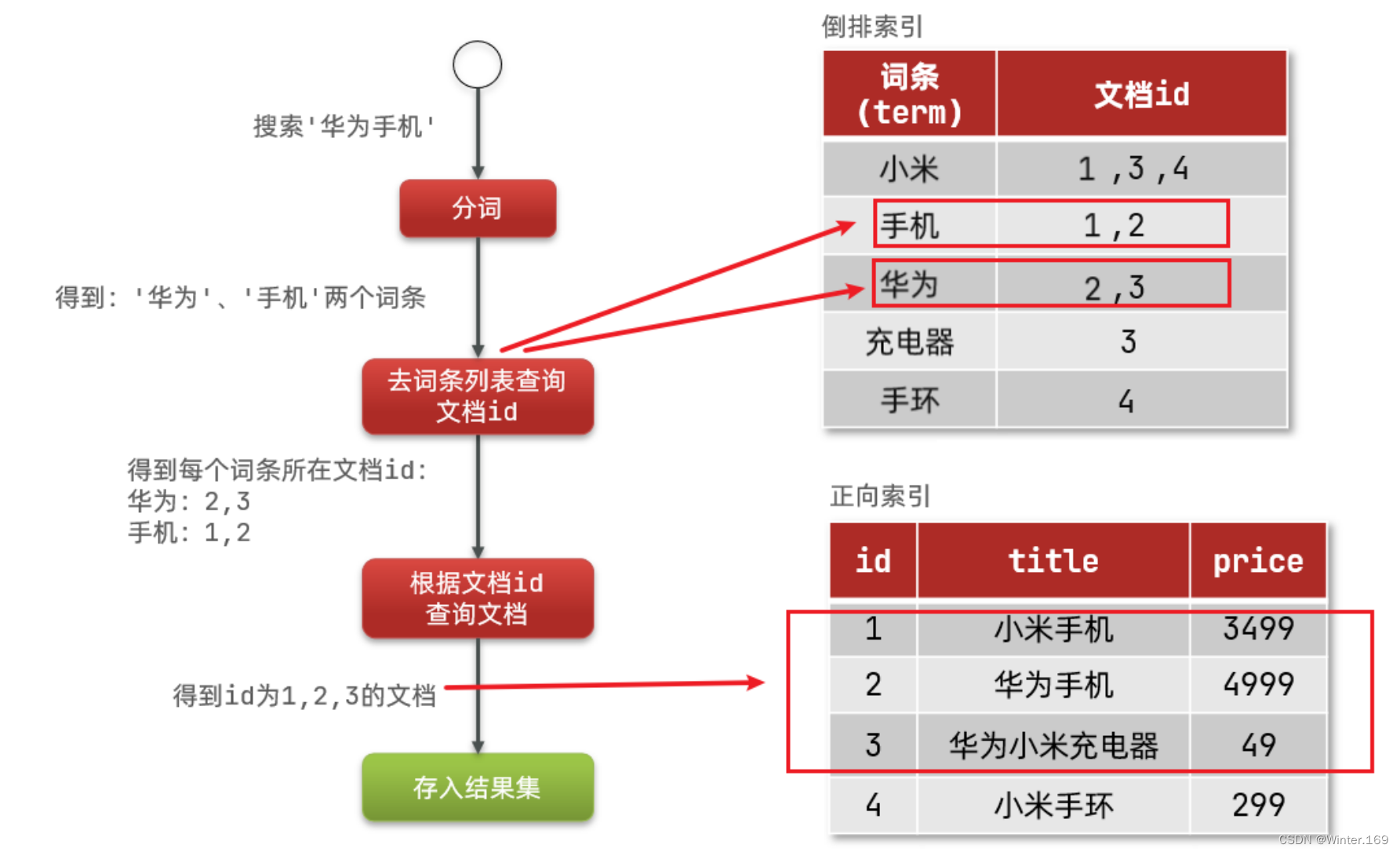
正向和倒排
es的一些概念


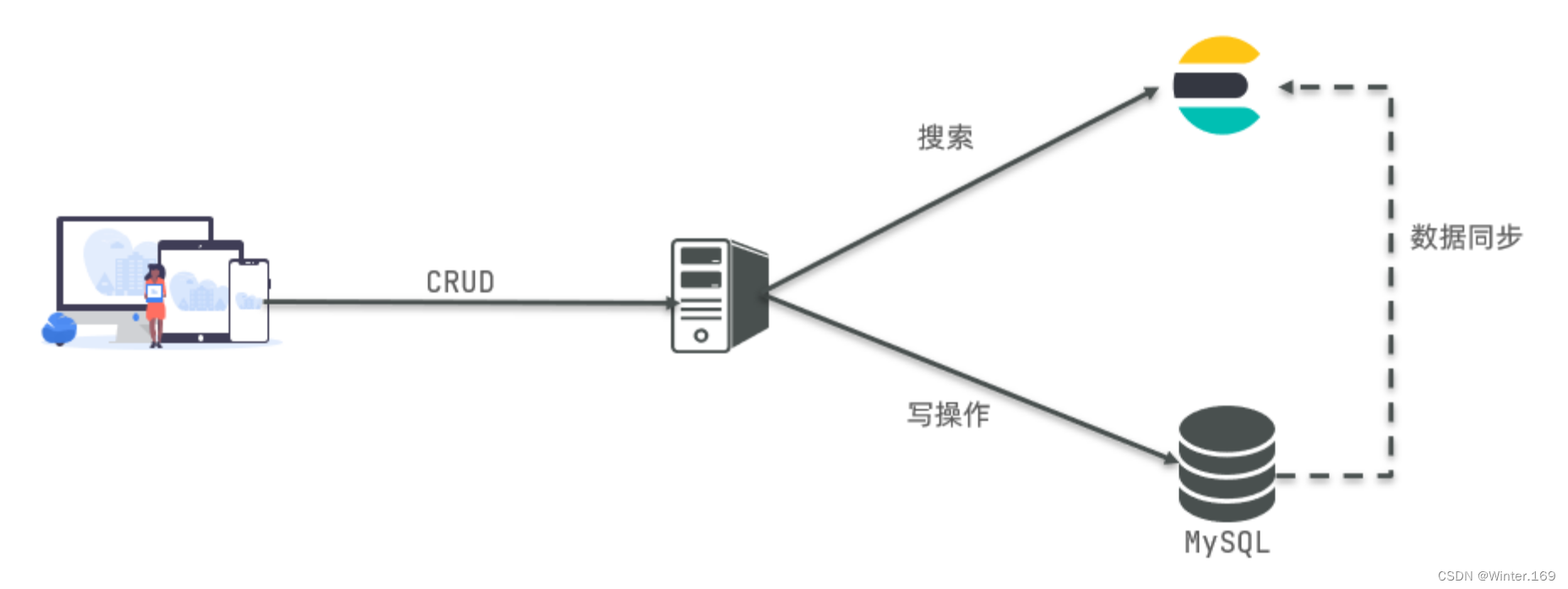
mysql与elasticsearch
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)

![[word] word中怎么插入另外一个word文档 #媒体#职场发展](https://img-blog.csdnimg.cn/img_convert/36ffef6b3060628ccf540a56f6069cb0.png)

