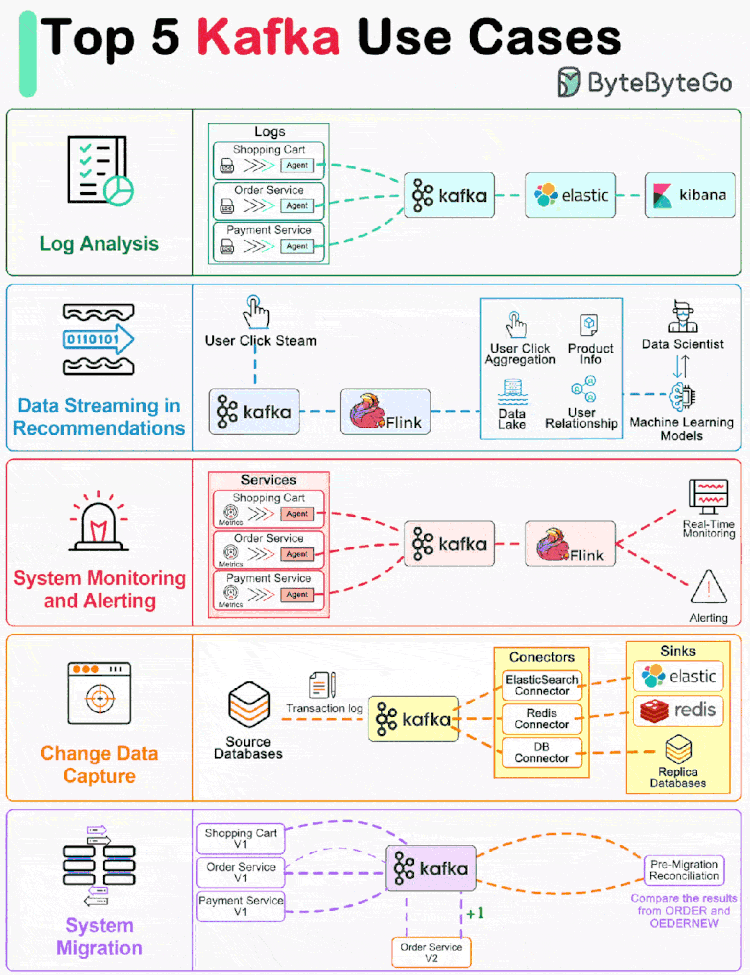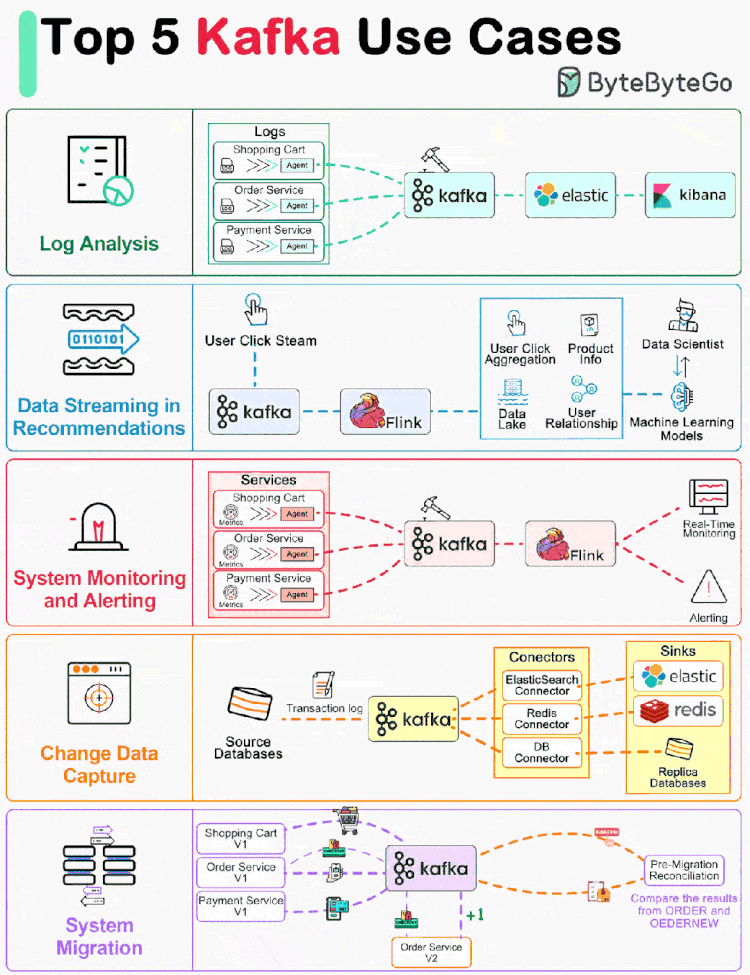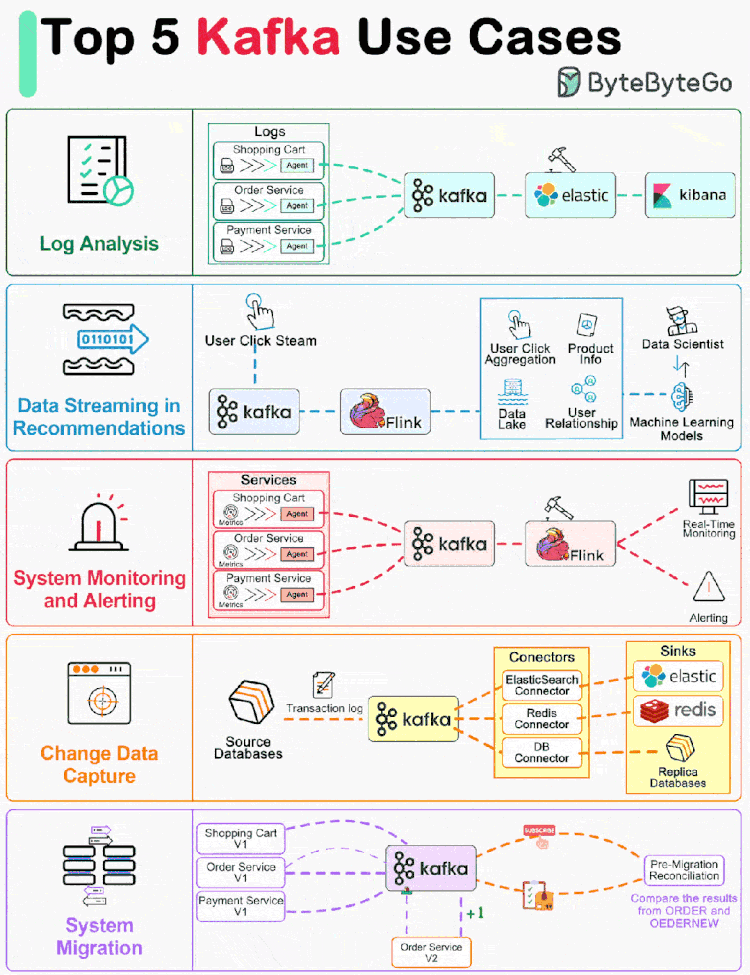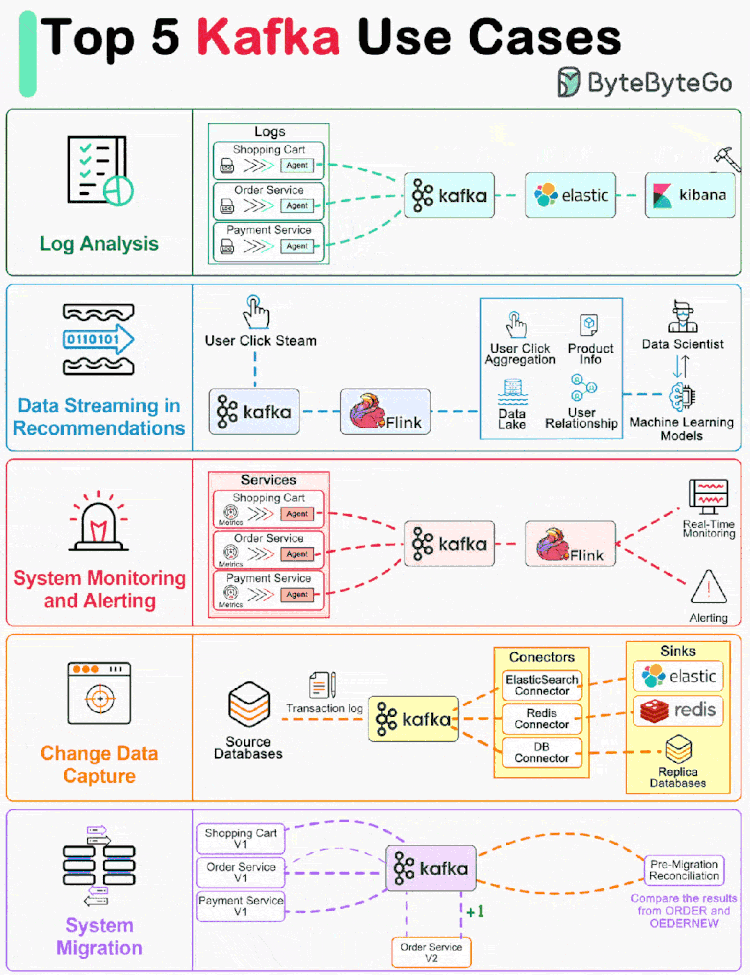
本文介绍: 与其之前的竞品不同,Kafka 不仅仅是一个消息队列,它还是一个适用于各种情况的开源事件流平台。Kafka 传输原始点击流数据,Flink 对其进行处理,而模型训练则消耗数据湖中的汇总数据。不同的是,指标是结构化数据,而日志是非结构化文本。例如,在下图中,事务日志被发送到 Kafka,并被 ElasticSearch、Redis 和二级数据库摄取。如上图所示,为了升级订单服务,我们更新了旧订单服务,以便从 Kafka 中消费输入,并将结果写入 ORDER Topic。如果它们完全相同,新服务就会通过测试。
Kafka 最初是为大规模处理日志而构建的。它可以保留消息直到过期,并让各个消费者按照自己的节奏提取消息。 与其之前的竞品不同,Kafka 不仅仅是一个消息队列,它还是一个适用于各种情况的开源事件流平台。 让我们回顾一下流行的 Kafka 用例。
01 日志处理和分析
上图显示了一个典型的 ELK(Elastic-Logstash-Kibana)栈。Kafka 从每个服务实例高效地收集日志流。ElasticSearch 从 Kafka 中获取日志并编制索引。Kibana 在 ElasticSearch 的基础上提供搜索和可视化用户界面。
02 推荐系统中的数据流
亚马逊等电子商务网站利用用户过去的行为和相似用户分析来计算产品推荐。Kafka 传输原始点击流数据,Flink 对其进行处理,而模型训练则消耗数据湖中的汇总数据。这样就能不断改进针对每个用户的推荐相关性。
03 系统监控和警报
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






