本文介绍: Elasticsearch8 集群配置:节点和集群配置
安装完Elasticsearch后,需要对其进行配置,包括以下几部分:节点和集群配置、系统配置、安全配置。
此篇记录节点和集群配置的内容,后续将更新系统配置和安全配置。
节点和集群配置:
通过编辑/usr/local/elasticsearch-8.10.2/config/elasticsearch.yml文件进行配置,在集群内每个节点上都要进行配置。
1、Cluster部分:
cluster.name: 设置集群名称,保证所有集群内所有节点cluster.name保持一致。

2、Node部分:
(1)主节点

(2)数据节点

(3)协调节点

(4)采集节点

3、Path部分:

4、Network部分:
(1)network.host:

(2)http.port:
(3)transport.port:
(4)http.host

(5)transport.host

(1)discovery.seed_hosts:


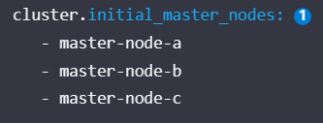
(2)cluster.initial_master_nodes
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






