前言
LaWGPT 是一系列基于中文法律知识的开源大语言模型。该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。LaWGPT是本人尝试使用和微调的第一个法律专业领域的大语言模型,自我感觉该模型很适合作为法律垂直领域大模型的入门级选手,无论是部署配置还是推理微调都十分方便。本文主要介绍如何配置部署LaWGPT和LaWGPT推理基本步骤,希望可以帮助大家使用LaWGPT。
一、下载和部署
1.1 下载
首先执行git clone git@github.com:pengxiao-song/LaWGPT.git下载项目仓库,但是可能会因为网络问题而失败,因此可以直接在Github上下载LawGPT的基本框架。
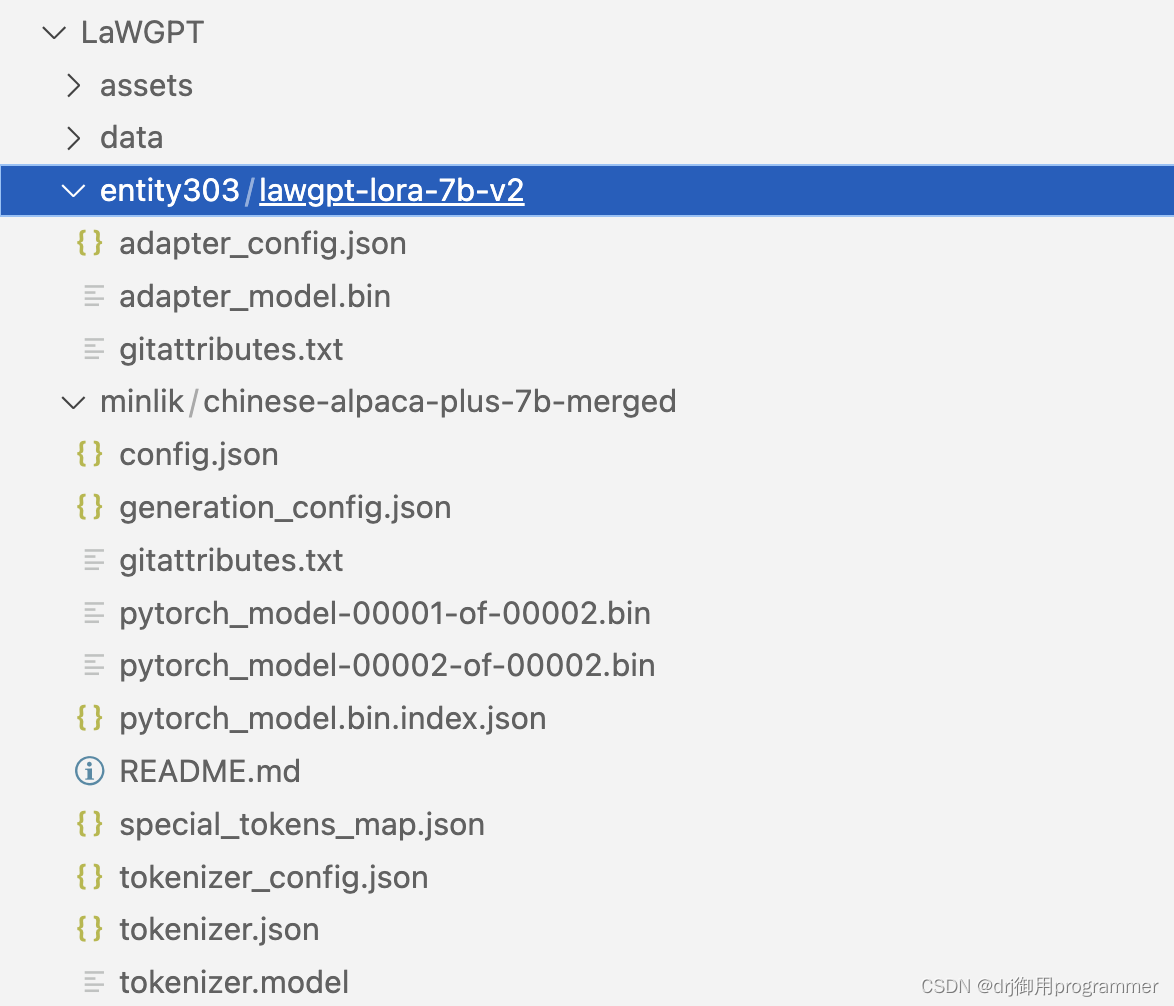
之后需要下载权重文件chinese-alpaca-plus-7b-merged和基础模型lawgpt-lora-7b-v2。下载地址为:chinese-llama-7b-merged和lawgpt-lora-7b-v2。下载好之后将基础模型lawgpt-lora-7b-v2放在entity303文件夹中(需要新建),chinese-alpaca-plus-7b-merged放在minlik文件夹中(需要新建)。
1.2 环境安装
服务器的版本为RTX 3090,内存为24GB。Python版本为3.10,ubuntu的版本为20.04,Cuda的版本为11.6。
其中requirements.txt修改如下,其中peft库我是在官网上下载至LaWGPT目录下再进行pip install peft安装的:
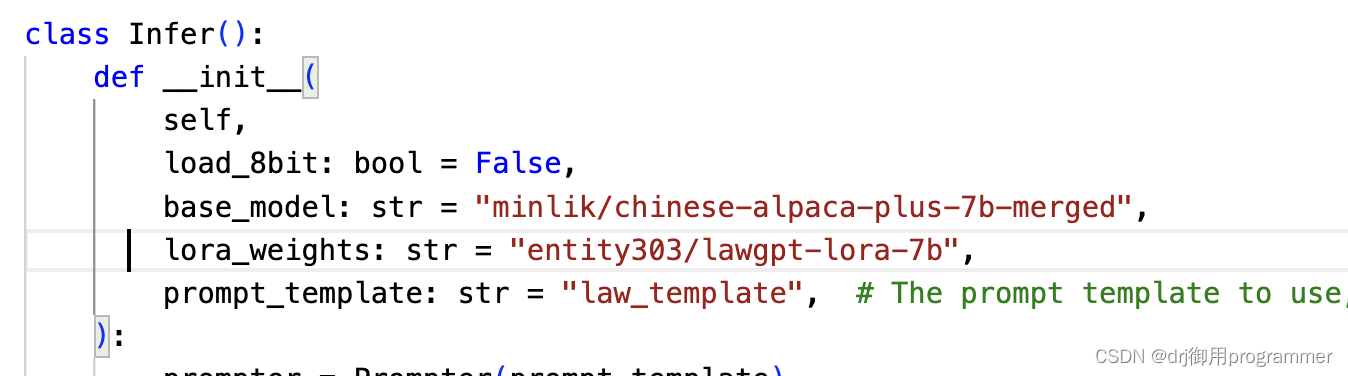
1.3 模型推理
模型推理部分我直接是调用了infer.py而不是infer.sh,需要额外安装fire库。infer.py文件中需要自己添加一下base_model,lora_weight和prompt_template的路径,两个部分别为: