文档
Learning_Spark/5.Spark Streaming/ReadMe.md at master · LeslieZhoa/Learning_Spark
# 在pyspark下运行
from pyspark.ml.feature import HashingTF,IDF,Tokenizer # 导入相关包
# 创建一个dataframe,toDF为定义列名
sentenceData = spark.createDataFrame([(0, "I heard about Spark and I love Spark"),(0, "I wish Java could use case classes"),(1, "Logistic regression models are neat")]).toDF("label", "sentence")
# Tokenizer作用是分词
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData = tokenizer.transform(sentenceData)
# 显示分词效果
wordsData.show()
# HashingTF是把分词句子映射成index,返回映射index和单词频次
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=2000)
featurizedData = hashingTF.transform(wordsData)
featurizedData.select("words","rawFeatures").show(truncate=False)
# IDF得到单词权重
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
rescaledData = idfModel.transform(featurizedData)
rescaledData.select("features", "label").show(truncate=False)# 依然在pyspark上运行
# 导入各种类
from pyspark.ml.linalg import Vector,Vectors
from pyspark.sql import Row,functions
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml import Pipeline
from pyspark.ml.feature import IndexToString, StringIndexer,VectorIndexer,HashingTF, Tokenizer
from pyspark.ml.classification import LogisticRegression,LogisticRegressionModel,BinaryLogisticRegressionSummary, LogisticRegression
# 定制函数读取特征和label
>>> def f(x):
... rel = {}
... rel['features']=Vectors.
... dense(float(x[0]),float(x[1]),float(x[2]),float(x[3])) #方法构建一个密集型特征向量
... rel['label'] = str(x[4])
... return rel
# 读取 数据
>>> data = spark.sparkContext.
... textFile("file:///usr/local/spark/iris.txt").
... map(lambda line: line.split(',')).
... map(lambda p: Row(**f(p))).
... toDF()
>>> data.show()
# 获取特征
# StringIndexer()-->按频次编码成index
>>> labelIndexer = StringIndexer().
... setInputCol("label").
... setOutputCol("indexedLabel").
... fit(data)
# VectorIndexer()-->有超参maxCategoties,
# 如果vector某一列取值种类超过maxCategoties,则保持原状不转换
>>> featureIndexer = VectorIndexer().
... setInputCol("features").
... setOutputCol("indexedFeatures").
... fit(data)
# 设置LogisticRegression算法的参数
>>> lr = LogisticRegression().
... setLabelCol("indexedLabel").
... setFeaturesCol("indexedFeatures").
... setMaxIter(100).
... setRegParam(0.3).
... setElasticNetParam(0.8)
>>> print("LogisticRegression parameters:n" + lr.explainParams())
#标签列、特征列、最大迭代次数、正则化参数等。
# 把预测结果转回字符
>>> labelConverter = IndexToString().
... setInputCol("prediction").
... setOutputCol("predictedLabel").
... setLabels(labelIndexer.labels)
#最后将预测结果的索引转换回标签字符串
# 练成pipline
>>> lrPipeline = Pipeline().
... setStages([labelIndexer, featureIndexer, lr, labelConverter])
# 拆分数据集,训练
>>> trainingData, testData = data.randomSplit([0.7, 0.3])
>>> lrPipelineModel = lrPipeline.fit(trainingData)
>>> lrPredictions = lrPipelineModel.transform(testData)
# 输出预测结果
>>> preRel = lrPredictions.select(
... "predictedLabel",
... "label",
... "features",
... "probability").
... collect()
#将选定的列从分布式的 DataFrame 收集到本地,形成一个包含行的列表。
>>> for item in preRel:
... print(str(item['label'])+','+
... str(item['features'])+'-->prob='+
... str(item['probability'])+',predictedLabel'+
... str(item['predictedLabel']))
# 评估模型,输出准确率
>>> evaluator = MulticlassClassificationEvaluator().
... setLabelCol("indexedLabel").
... setPredictionCol("prediction")
>>> lrAccuracy = evaluator.evaluate(lrPredictions)
>>> lrAccuracy
# 获取模型参数
>>> lrModel = lrPipelineModel.stages[2]
>>> print ("Coefficients: n " + str(lrModel.coefficientMatrix)+
... "nIntercept: "+str(lrModel.interceptVector)+
... "n numClasses: "+str(lrModel.numClasses)+
... "n numFeatures: "+str(lrModel.numFeatures))
from pyspark import SparkContext
# 创建指挥官
sc = SparkContext.getrOreate()
#创建SparkContext (sc):这是与Spark功能的连接入口,表示与Spark集群的连接。从文件中读取数据 (lines):
# 1.从文件系统中加執数据创建RDD
lines = sc.textFile('file:///home/hadoop/PycharmProjects/BigDataAnalysis/data/word.txt')
lines.foreach(print)#使用foreach方法将print函数应用于RDD中的每个元素,这里是行。将行拆分为单词 (words):
words =lines.flatMap(lambda line:line.split(' '))
words.foreach (print)#使用flatMap变换基于空格将每一行拆分为单词。打印每个单词:
kv = words. map(lambda word: (word, 1)) #使用map变换将每个单词转换为键值对,其中单词是键,值设置为1。打印键值对:
kv.foreach(print)
wf = kv.reduceByKey (lambda a,b:a+b) #使用reduceByKey变换来聚合每个单词的计数关于Jieba的说明:
# ROW封装一行数据
from pyspark.sql import Row
# 返回一个sparkContext对象
people = spark.sparkContext.
... textFile("file:///usr/local/spark/examples/src/main/resources/people.txt").
... map(lambda line: line.split(",")).
... map(lambda p: Row(name=p[0], age=int(p[1])))
# 创建DataFrame
schemaPeople = spark.createDataFrame(people)
#必须注册为临时表才能供下面的查询使用
schemaPeople.createOrReplaceTempView("people")
personsDF = spark.sql("select name,age from people where age > 20")
#DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用p.name和p.age来获取值
personsRDD=personsDF.rdd.map(lambda p:"Name: "+p.name+ ","+"Age: "+str(p.age))
personsRDD.collect()
————————————————————————————————————————————————————————
#在WriteSql.py下写入
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
#下面设置模式信息
schema = StructType([StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("gender", StringType(), True),
StructField("age", IntegerType(), True)])
#下面设置两条数据,表示两个学生的信息
studentRDD = spark
.sparkContext
.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"])
.map(lambda x:x.split(" "))
#下面创建Row对象,每个Row对象都是rowRDD中的一行
rowRDD = studentRDD.map(lambda p:Row(int(p[0].strip()), p[1].strip(), p[2].strip(), int(p[3].strip())))
#并去除前导和尾随空格
#建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
studentDF = spark.createDataFrame(rowRDD, schema)
#写入数据库
prop = {}
prop['user'] = 'root'
prop['password'] = '1234'
prop['driver'] = "com.mysql.jdbc.Driver"
studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)
#pyspark运行下列代码
jdbcDF = spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url", "jdbc:mysql://localhost:3306/spark").option("dbtable", "student").option("user", "root").option("password", "1234").load()
jdbcDF.show()配置环境
- 配置JBDC
-
- 点击此链接进入jbdc下载页面
- Select Operating System选择Platform Independent,下载TAR Archive那个,并解压
- 将解压后里面的.jar文件放入/usr/local/spark/jars/下,我的文件名为mysql-connector-java-8.0.19.jar
难点
如果不上传hdfs怎么用pyspqrk分析
3. 将文件上传至HDFS文件系统中
然后使用如下命令把本地文件系统的“/home/hadoop/us-counties.txt”上传到HDFS文件系统中,具体路径是“/user/hadoop/us-counties.txt”。具体命令如下:
./bin/hdfs dfs -put /home/hadoop/us-counties.txt /user/hadoop
解决办法
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName(“YourAppName”)
sc = SparkContext(conf=conf)
file_path = “file:///home/hadoop/us-counties.txt”#读取本地文件
rdd = sc.textFile(file_path)
#对 rdd 执行各种 PySpark 操作,例如 map、filter、reduce 等,根据你的分析需求。
result = rdd.map(lambda line: line.split(",")).filter(lambda data: int(data[3]) > 1000)
展示结果或保存到本地: 最后,你可以通过 collect 方法收集结果并在本地打印,或者将结果保存到本地文件/
result.collect()
# 或者
result.saveAsTextFile(“output_directory”)
peizhi

(base) hadoop@ubuntu:/usr/local/bin$ whereis python
python: /usr/bin/python /usr/bin/python3.6 /usr/bin/python2.7 /usr/bin/python3.6m /usr/lib/python3.7 /usr/lib/python3.6 /usr/lib/python2.7 /usr/lib/python3.8 /etc/python /etc/python3.6 /etc/python2.7 /usr/local/lib/python3.6 /usr/local/lib/python2.7 /usr/include/python3.6m /usr/share/python /home/hadoop/anaconda3/bin/python /home/hadoop/anaconda3/bin/python3.8-config /home/hadoop/anaconda3/bin/python3.8 /usr/share/man/man1/python.1.gz
./bin/hdfs dfs -put /home/hadoop/us-counties.txt /user/hadoop
常见错误
输出错误与读取
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/home/hadoop/PycharmProjects/pyspqark_TEST/gawz.txt
#文件路径不对
读取
# 1. 从文件系统中读取数据并创建RDD
lines = sc.textFile(‘file:///home/hadoop/PycharmProjects/pyspqark_TEST/gawz.csv’)
# /home/hadoop/PycharmProjects/pyspqark_TES
# 打印RDD中的每一行
lines.foreach(print)
����ѯһ�������Ϻ��ڱ���Ѿ������꣬�ܷ�������سǹ���������ȥ����Ϊ�����˷���
读取格式
【Python笔记】spark.read.csv-CSDN博客
# 定义 spark df 的表结构
schema = StructType(
[
StructField('ip', StringType(), True),
StructField('city', StringType(), True)
]
)
ip_city_path = job+'/abcdefg'
ip_city_df = spark.read.csv(ip_city_path, header=True, schema=schema, encoding='utf-8', sep=',')
你好,看起来你试图在 PySpark DataFrame 上使用 flatMap 函数,但遇到了 AttributeError,因为 DataFrame 没有直接的 flatMap 方法。
如果你想对 DataFrame 的每一行应用一个函数,并生成一个包含结果的新 DataFrame,你可以使用 withColumn 方法和 select 方法。以下是一个使用用户定义函数(UDF)和 select 方法的示例:
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
# 创建一个 Spark 会话
spark = SparkSession.builder.appName("example").getOrCreate()
# 示例 DataFrame
data = [("这是一个句子。",), ("这里有另一个句子。",)]
columns = ["text"]
df = spark.createDataFrame(data, columns)
# 定义一个使用 jieba 切分文本的 UDF
def tokenize_udf(line):
import jieba
return list(jieba.cut(line))
# 注册 UDF
tokenize = udf(tokenize_udf, StringType())
# 应用 UDF 以创建包含标记化单词的新 DataFrame
tokenized_df = df.select("text", tokenize("text").alias("words"))
# 显示结果
tokenized_df.show(truncate=False)
在这个例子中,tokenize_udf 函数使用 jieba 切分每一行,然后使用 select 方法将 tokenize UDF 应用于 DataFrame。结果是一个包含原始文本和一个新列(包含标记化单词)的新 DataFrame。
记得根据你的具体需求和数据调整 UDF 和 DataFrame 的列。
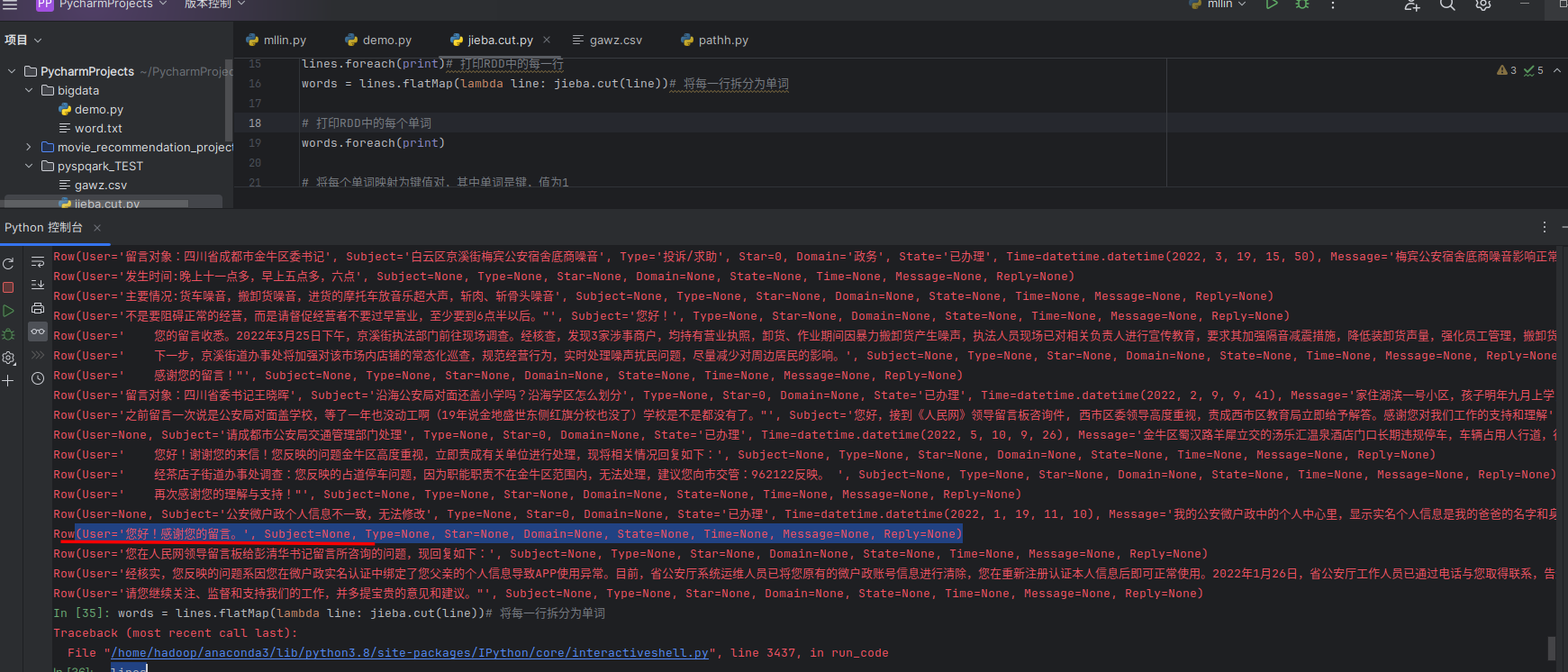
创建表结构
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType
from pyspark.sql import SparkSession
# 创建 Spark 会话
spark = SparkSession.builder.appName(“example”).getOrCreate()
# 定义表结构
schema = StructType([
StructField(‘User’, StringType(), True),
StructField(‘Subject’, StringType(), True),
StructField(‘Type’, StringType(), True),
StructField(‘Star’, IntegerType(), True),
StructField(‘Domain’, StringType(), True),
StructField(‘State’, StringType(), True),
StructField(‘Time’, TimestampType(), True),
StructField(‘Message’, StringType(), True),
StructField(‘Reply’, StringType(), True)
])
# 使用定义的结构创建一个空 DataFrame
df = spark.createDataFrame(lines, schema=schema) #TypeError: data is already a DataFrame
# 显示 DataFrame 结构 empty_df.printSchema()

django代码部分
urls
urls视图函数创建
from django.urls import path
from . import views
urlpatterns = [
path('', views.movie, name='movie'),
path('recommendation/', views.recommendation, name='recommendation'),
path('chart/',views.chart,name='chart')
]
将不同的URL路径映射到相应的视图函数。
1.from django.urls import path: 导入Django框架的path函数,用于定义URL模式。
2.from . import views: 导入当前目录下的views模块(或包)。这里使用了相对导入,.表示当前目录。
3.urlpatterns = […]: 定义一个名为urlpatterns的列表,其中包含了URL模式的配置。
4.path(”, views.movie, name=’movie’): 定义一个URL模式,当用户访问网站的根路径时,将调用views.movie函数处理请求。name=’movie’为这个URL模式指定了一个名称,便于在Django应用程序中引用。
5.path(‘recommendation/’, views.recommendation, name=’recommendation’): 定义了另一个URL模式,当用户访问/recommendation/路径时,将调用views.recommendation函数处理请求。同样,name=’recommendation’为该URL模式指定了一个名称。
6.path(‘chart/’,views.chart,name=’chart’): 定义了第三个URL模式,当用户访问/chart/路径时,将调用views.chart函数处理请求。同样,name=’chart’为该URL模式指定了一个名称。
这些URL模式的定义是Django应用程序中的一部分,它们定义了用户访问不同路径时应该执行的视图函数。这些视图函数通常包含了与请求相关的逻辑,可能涉及从数据库中检索数据、渲染模板等操作。这个URL配置文件通常在Django应用程序中的urls.py中定义,然后通过Django项目的总体配置来包含。
django学习
模板渲染
Django 模板语言基础
Django 模板本质上是一个 HTML 文档,只不过通过一些特殊的语法实现数据的填充。这里我们讲解一下最常用的三个语法:
通过在一对花括号 {{}} 放入一个表达式,就能够在视图中传入表达式中变量的内容,并最终渲染成包含变量具体内容的 HTML 代码
<!-- 单个变量 -->
{{ variable }}
<!-- 获取字典的键或对象的属性 -->
{{ dict.key }}
{{ object.attribute }}
<!-- 获取列表中的某个元素 -->
{{ list.0 }}

from django.shortcuts import render
def index(request):
context = {
'news_list': [
{
"title": "图雀写作工具推出了新的版本",
"content": "随随便便就能写出一篇好教程,真的很神奇",
},
{
"title": "图雀社区正式推出快速入门系列教程",
"content": "一杯茶的功夫,让你快速上手,绝无担忧",
},
]
}
return render(request, 'news/index.html', context=context)这里我们调用 django.shortcuts.render 函数来渲染模板,这个函数通常接受三个参数(有其他参数,但是这里我们不关心):
- request:请求对象,直接把视图的参数 request 传进来就可以
- template_name:模板名称,这里就是我们刚刚创建的 news/index.html
- context:传入模板的上下文对象,必须是一个字典,字典中的每个键对应模板中的变量。这里我们弄了些假数据,假装是从数据库里面取来的。
再访问 localhost:8000,看一下我们的首页是不是有内容了:
我们来看一些简单的 Django ORM 例子:
# 查询所有模型
# 等价于 SELECT * FROM Blog
Blog.objects.all()
# 查询单个模型
# 等价于 SELECT * FROM Blog WHERE ID=1
Blog.objects.get(id=1)
# 添加单个模型
# 等价于 INSERT INTO Blog (title, content) VALUES ('hello', 'world')
blog = Blog(title='hello', content='world')
blog.save()

前后端结合
return render(request, 'chart.html', {'pie_chart': pie_chart.render_embed()})

常用命令
python manage.py makemigrations
python manage.py migrate
python manage.py runserver
python manage.py startapp 应用名称
<imgsrc=”/static/image/pic/time.jpg”alt=”qwe”>


- User (用户) – 留言对象
- Subject (主题) – 留言主题
- Type (类型) – 留言类型
- Star (星级) – 星级评分
- Domain (领域) – 所属领域
- State (状态) – 处理状态
- Time (时间) – 留言时间
- Message (消息) – 留言内容
- Reply (回复) – 回复内容是的,
subject_wordcloud_path在这里代表的是生成的词云图 HTML 文件的路径。在 Django 视图中设置这个路径作为上下文变量,然后在模板中通过 iframe 标签引用这个路径,从而将词云图嵌入到您的网页中。
这个路径应该是相对于您的 Django 项目的静态文件目录的路径。例如,如果您的 Django 项目有一个静态文件目录 static,并且您将词云图的 HTML 文件保存在这个目录下的某个子目录中,那么 subject_wordcloud_path 应该设置为该 HTML 文件相对于 static 目录的路径。
示例
假设您的项目结构如下:
my_django_project/
|-- my_app/
| |-- static/
| | |-- wordclouds/
| | | |-- subject_wordcloud.html
| | | |-- message_wordcloud.html
| |-- templates/
| | |-- chart.html
| |-- views.py
|-- manage.py
在这种情况下,您可以这样设置路径:
def chart_view(request):
context = {
'subject_wordcloud_path': '/static/wordclouds/subject_wordcloud.html',
'message_wordcloud_path': '/static/wordclouds/message_wordcloud.html'
}
return render(request, 'chart.html', context)
然后在模板 chart.html 中使用这些路径:
<!DOCTYPE html>
<html>
<head>
<title>Charts</title>
</head>
<body>
<h1>词云图</h1>
<iframe src="{{ subject_wordcloud_path }}" style="width:600px; height:400px;"></iframe>
<iframe src="{{ message_wordcloud_path }}" style="width:600px; height:400px;"></iframe>
</body>
</html>
确保您的 HTML 文件实际上位于这些路径上,并且这些路径对于您的 Django 服务器是可访问的。您可能需要配置 Django 的静态文件路径,以确保静态文件可以被正确地服务。
原文地址:https://blog.csdn.net/m0_69379600/article/details/135662175
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_57944.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!