本文介绍: 4篇应用解耦表示学习的文章,这里只关注如何解耦,更多细节不关注,简单记录一下。
4篇应用解耦表示学习的文章,这里只关注如何解耦,更多细节不关注,简单记录一下。
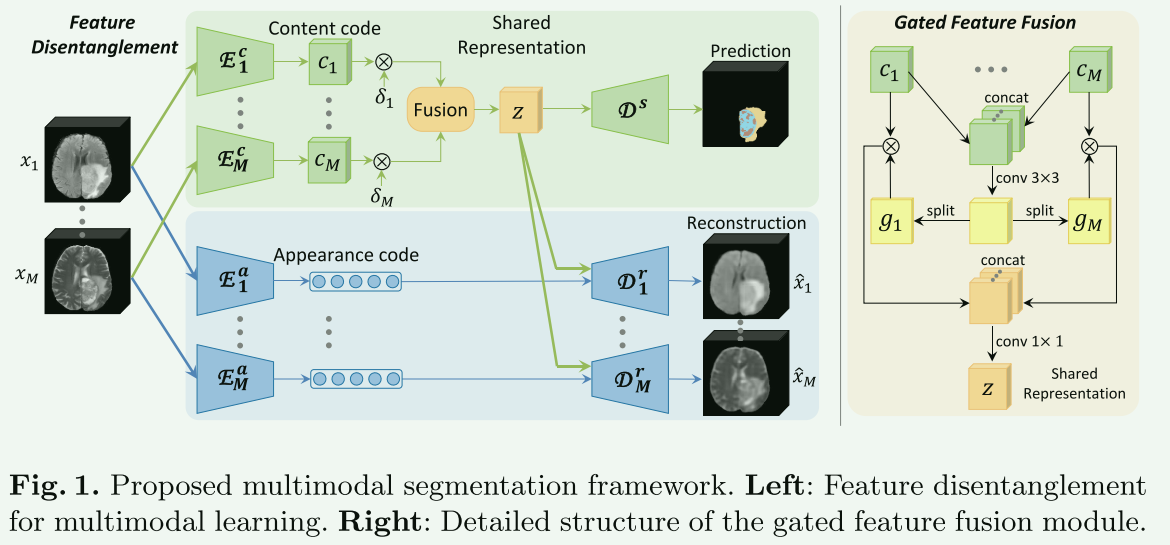
1.Robust Multimodal Brain Tumor Segmentation via Feature Disentanglement and Gated Fusion
Chen C, Dou Q, Jin Y, et al. Robust multimodal brain tumor segmentation via feature disentanglement and gated fusion[C]//Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part III 22. Springer International Publishing, 2019: 447-456.
【核心思想】
通过特征解耦和门控融合技术,提高了在部分成像模态缺失时的分割准确性。方法是将输入的多种成像模态解耦为模态特定的外观代码和模态不变的内容代码,然后将它们融合为一个共享表示。这种方法增强了面对缺失数据时分割过程的鲁棒性,并在多种缺失模态的场景中显示出显著的改进。论文还使用了BRATS挑战数据集来验证方法的有效性,并展示了与当前最先进方法相比的竞争性能。
【网络结构】
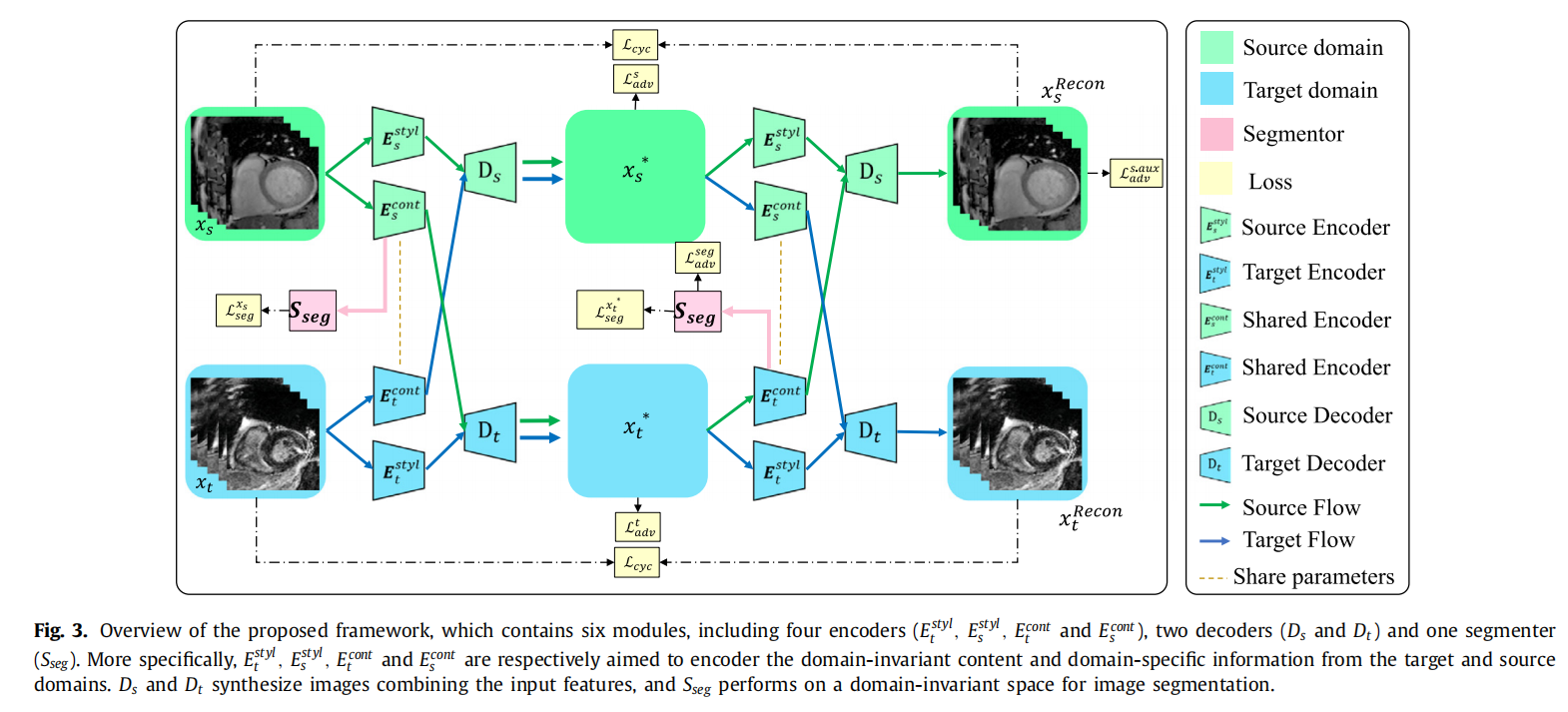
2.Disentangle domain features for cross-modality cardiac image segmentation
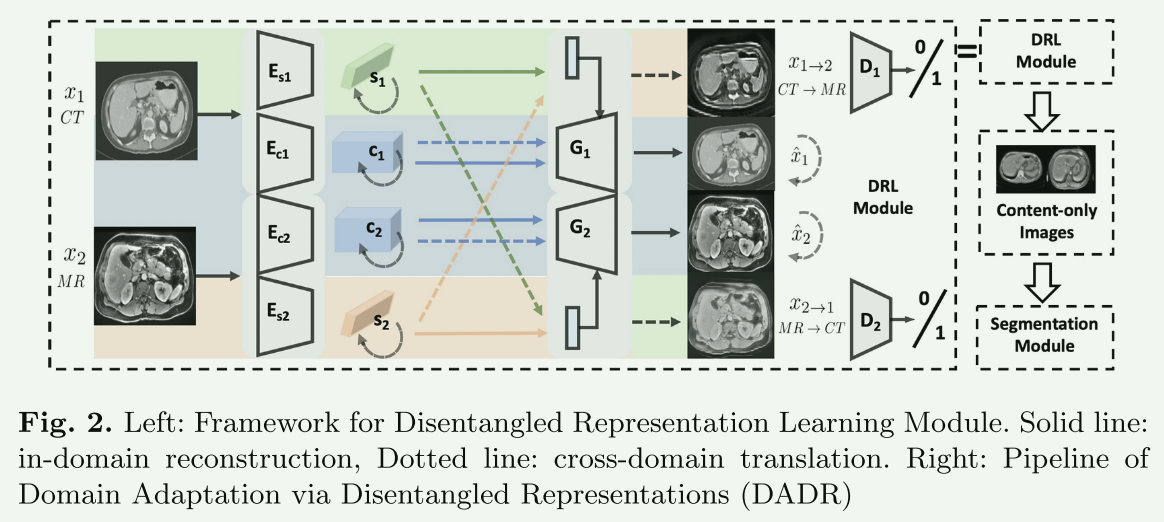
3.Unsupervised domain adaptation via disentangled representations: Application to cross-modality liver segmentation
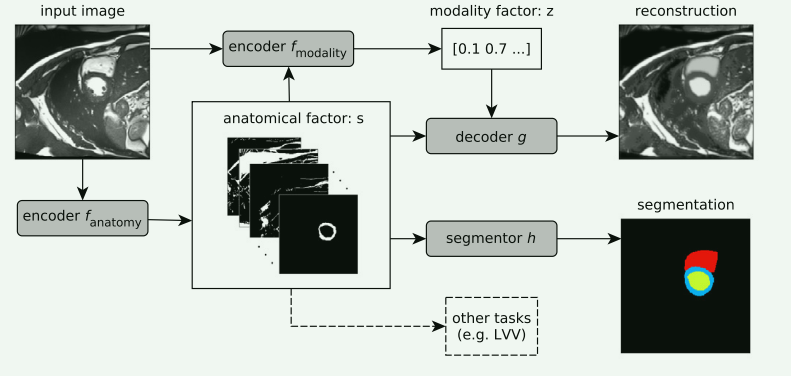
4.Disentangled representation learning in cardiac image analysis
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)