本文介绍: 介绍完Kafka的核心概念,我们通过图进行总结,并从更高的视角审视整个Kafka集群的架构。
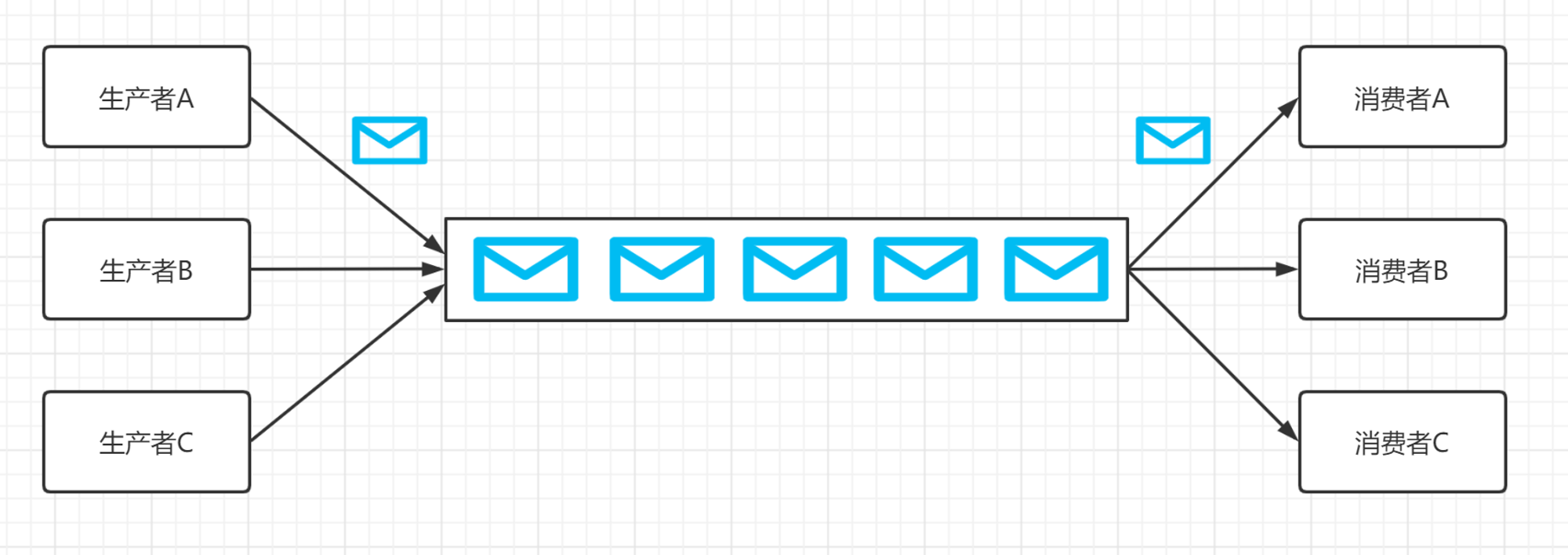
消息
消息是Kafka中最基本的数据单元。
消息由一串字节构成,其中主要由key和value构成,key和value也都是byte数组。
key的主要作用是根据一定的策略,将此消息路由到指定的分区中,这样就可以保证包含同一key的消息全部写入同一分区中,key可以是null。
消息的真正有效负载是value部分的数据。
为了提高网络和存储的利用率,生产者会批量发送消息到Kafka,并在发送之前对消息进行压缩。
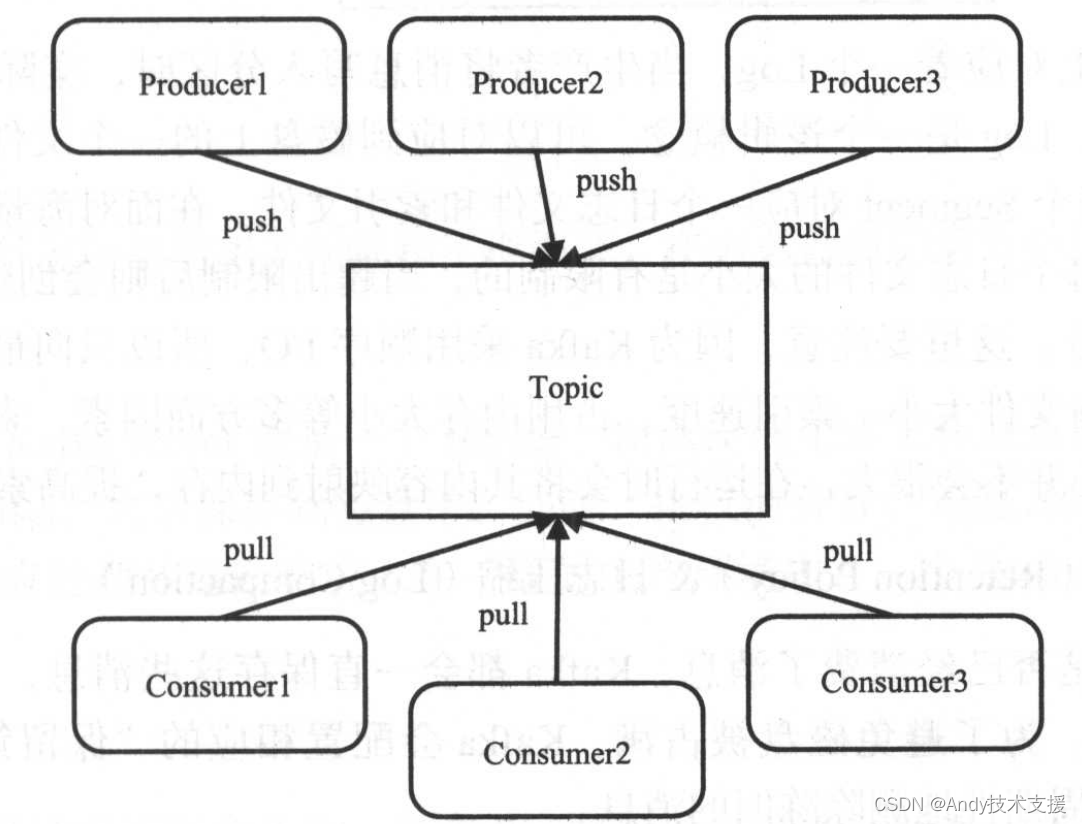
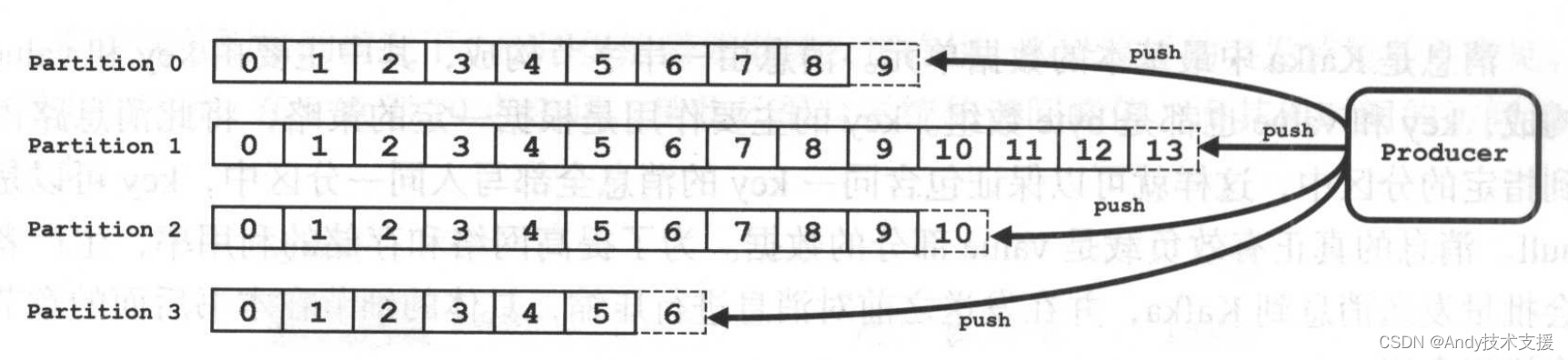
Topic&分区&Log
Topic是用于存储消息的逻辑概念,可以看作一个消息集合。
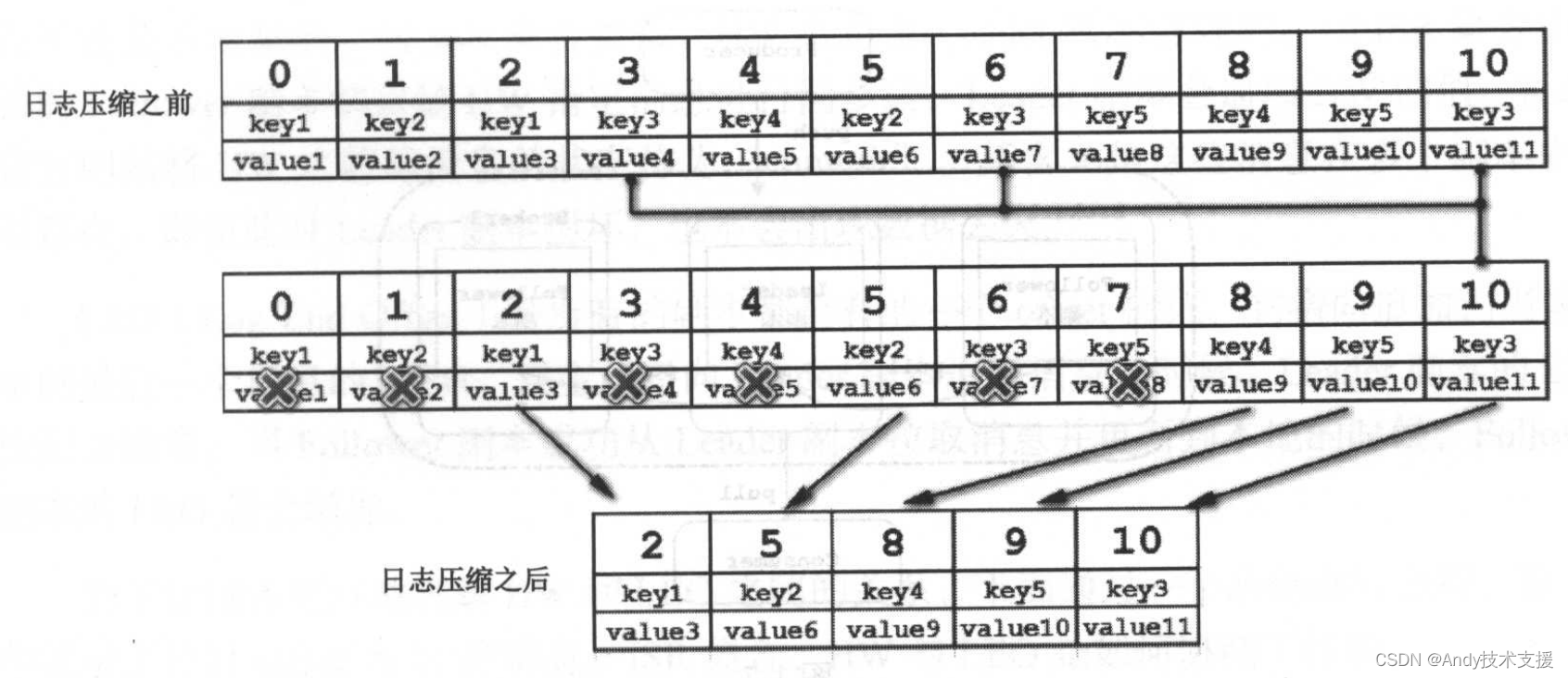
保留策略(Retention Policy)&日志压缩(Log Compaction)
Broker
副本
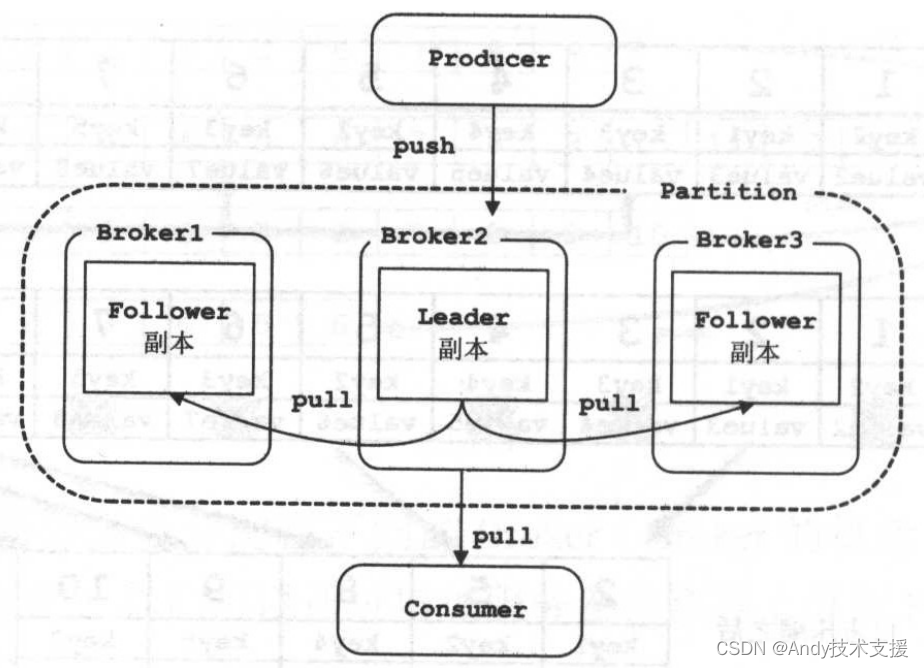
ISR集合
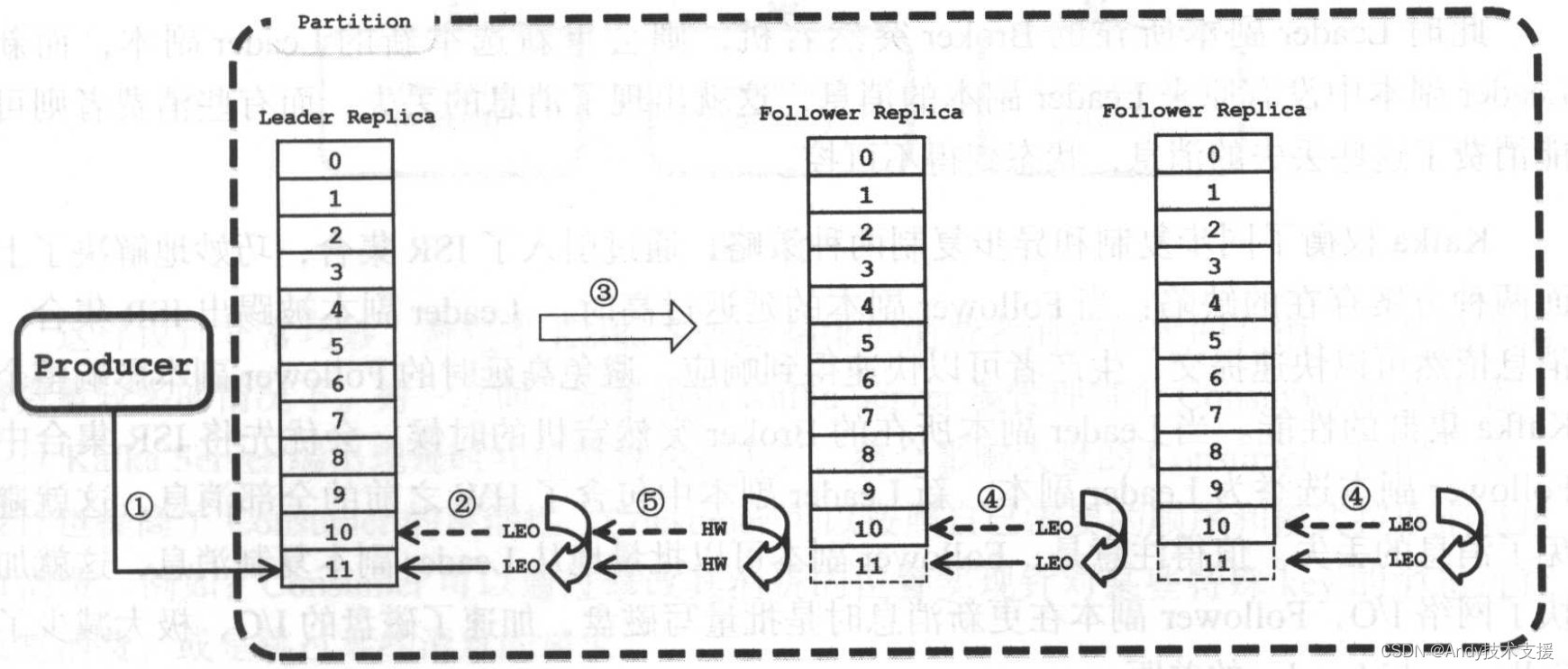
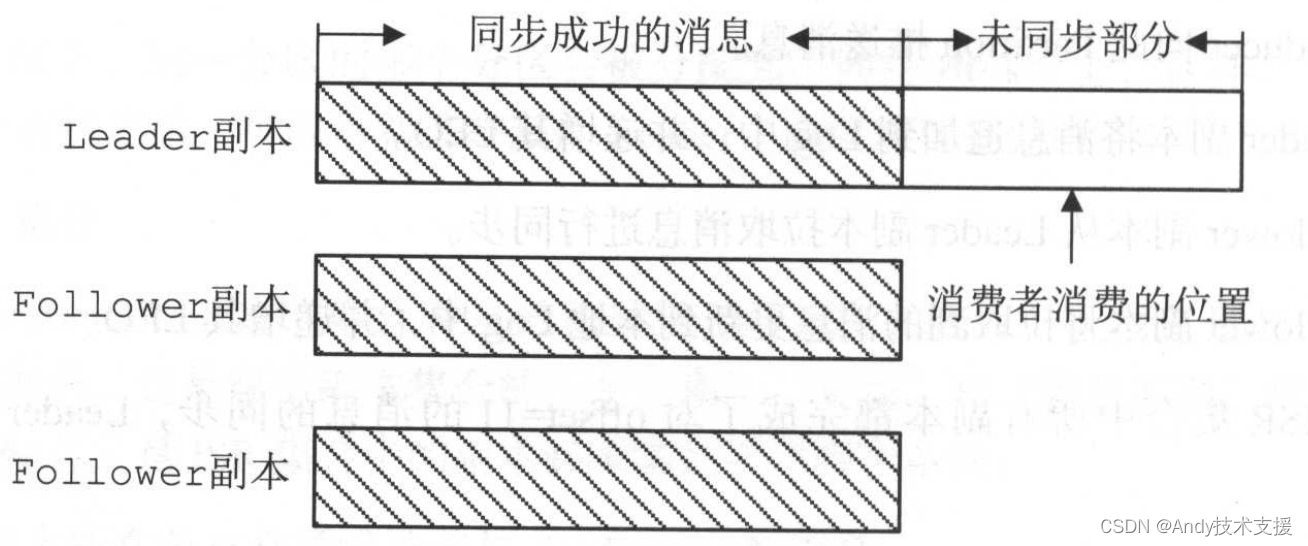
HW&LEO
Cluster&Controller
生产者
消费者
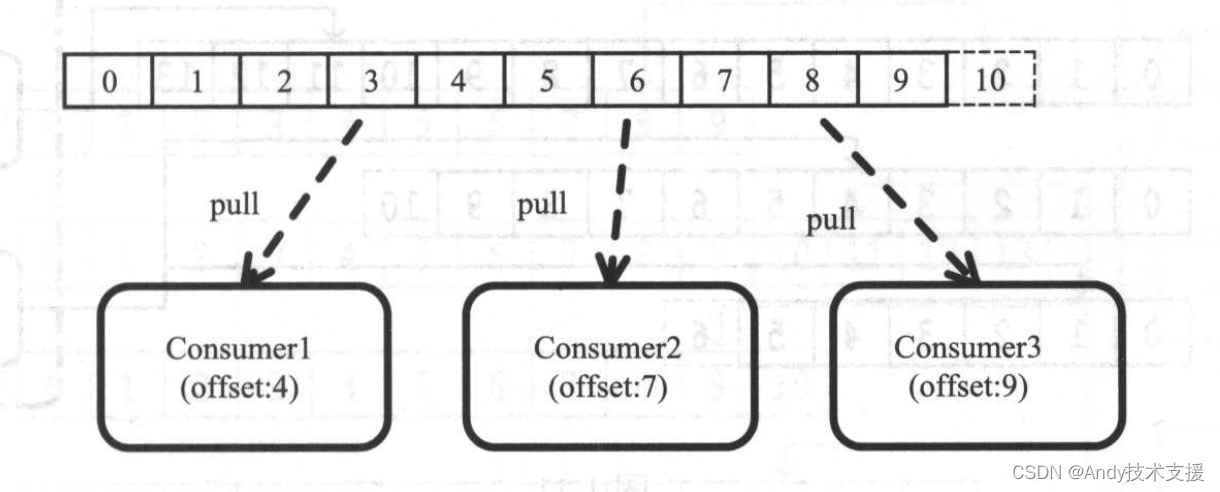
Consumer Group

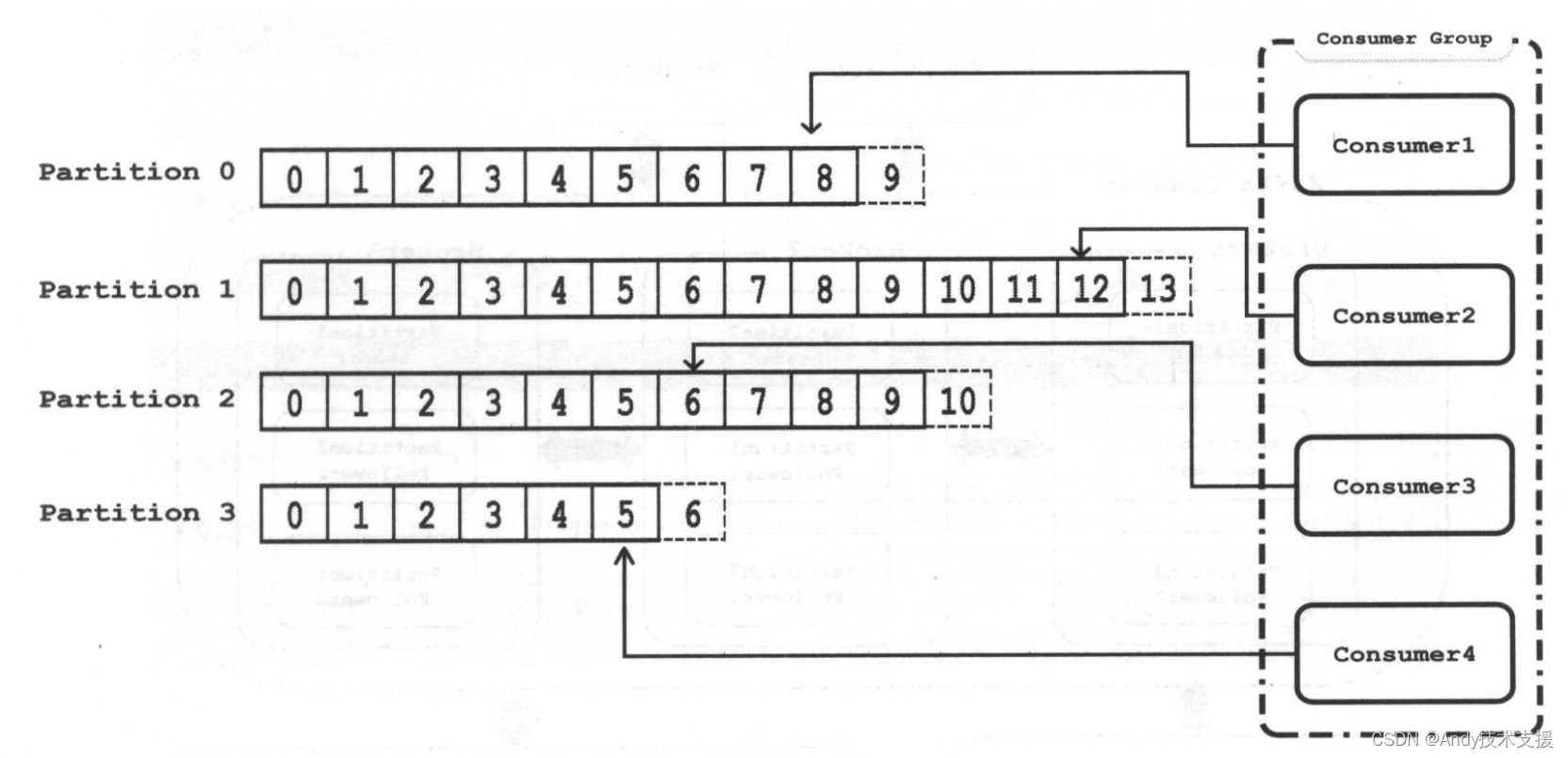
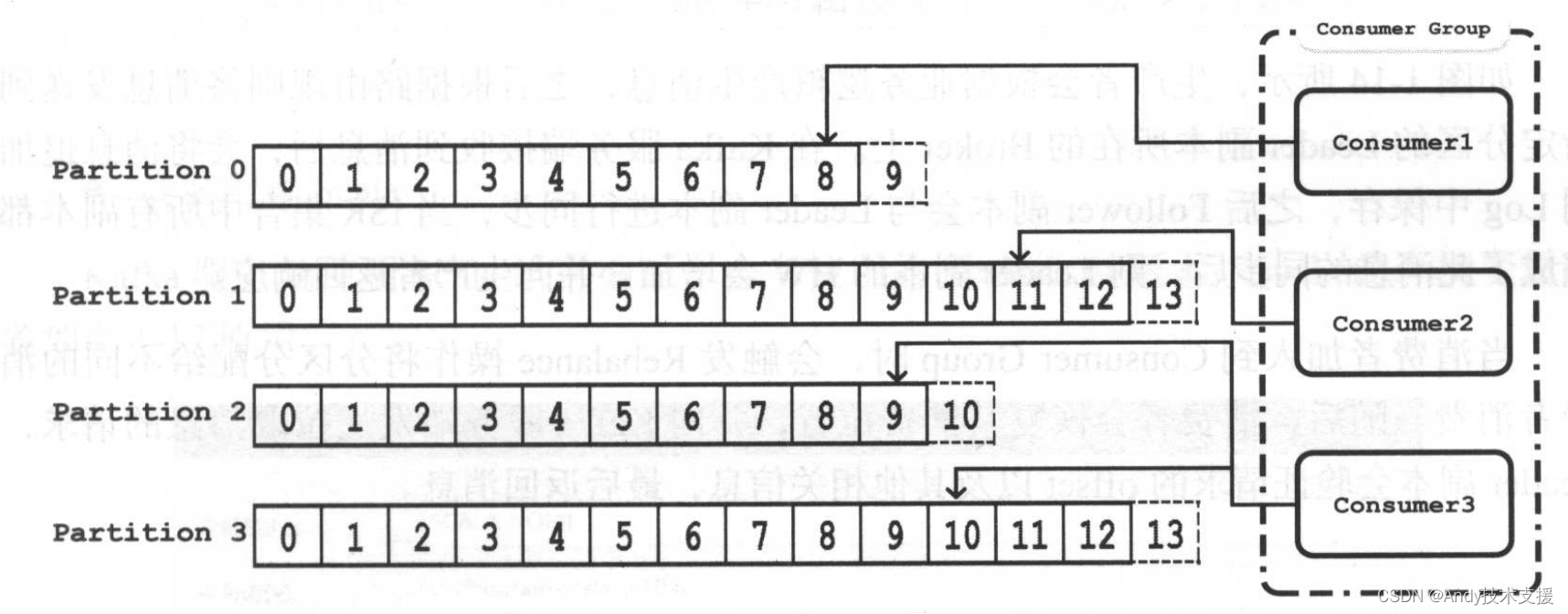
总结
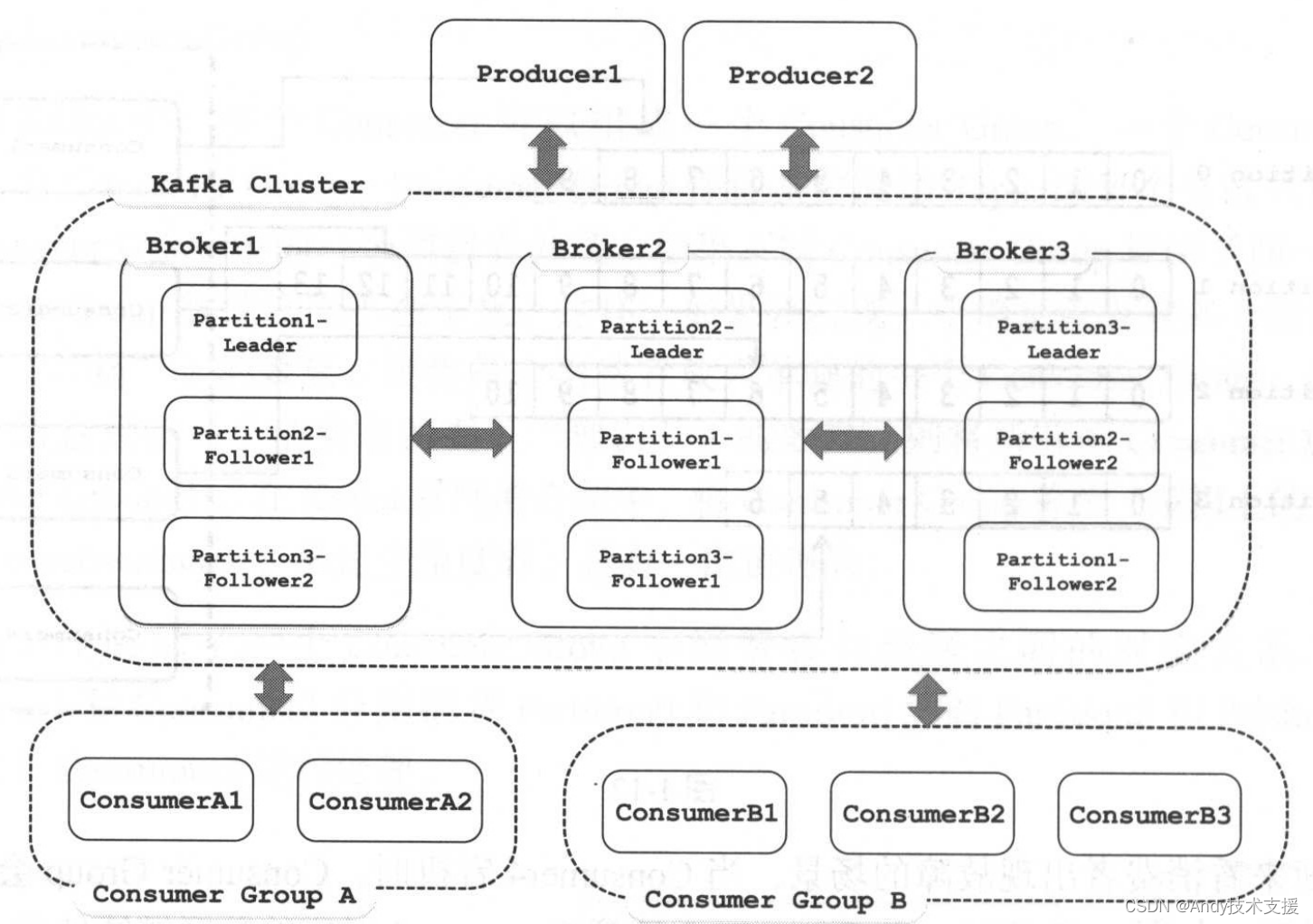
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。