1 日志管理
1.1 日志管理方案
服务器数量较少时
直接登录到目标服务器捞日志查看 → 通过 rsyslog 或shell/python 等脚本实现日志搜集并集中保存到统一的日志服务器
服务器数量较多时
ELK 大型的日志系统,实现日志收集、日志存储、日志检索和分析
容器环境
EFK Loki+Granfana
1.2 使用ELK的原因
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。 往往单台机器的日志我们使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用 grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。 一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
1.3 完整日志系统的基本特征
收集:能够采集多种来源的日志数据 传输:能够稳定的把日志数据解析过滤并传输到存储系统 存储:存储日志数据 分析:支持 UI 分析 警告:能够提供错误报告,监控机制
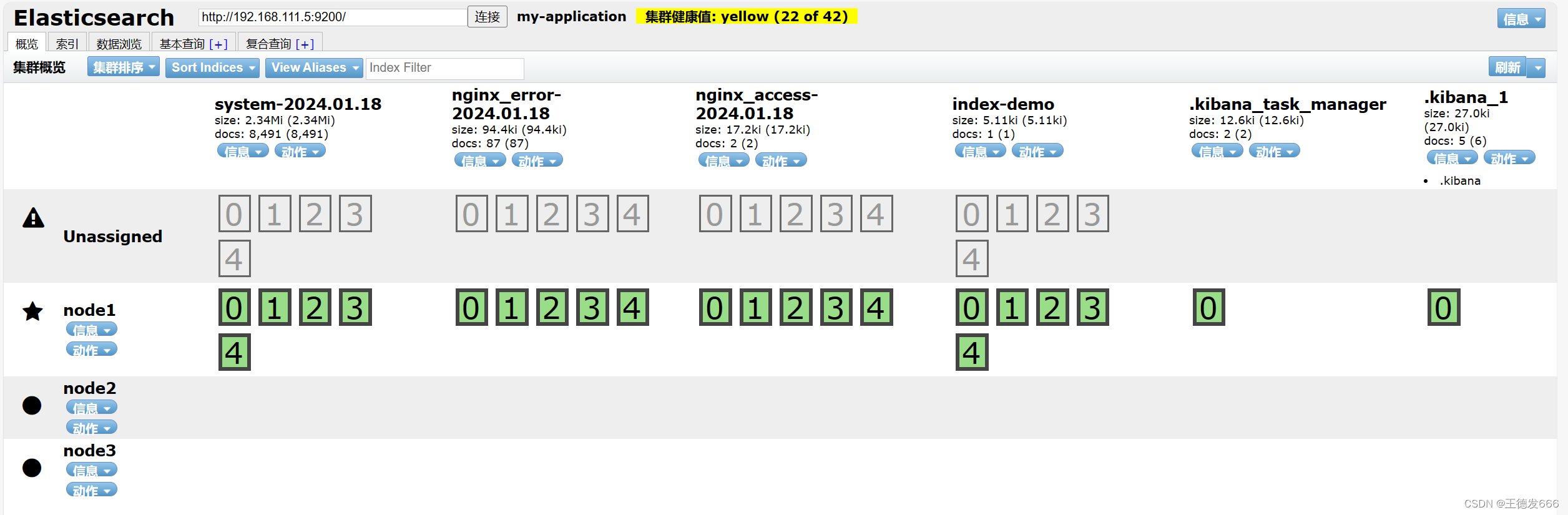
1.4 ELK概述
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。