目录
练习1:
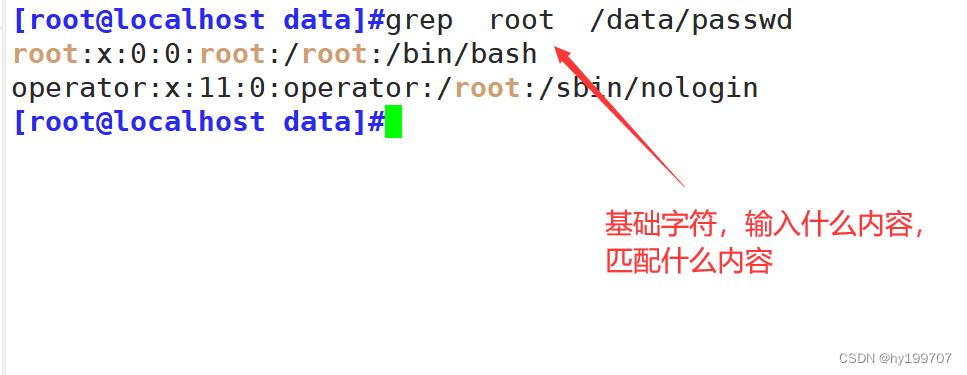
正则表达式可以校验字符串是否满足一定的规则,并用来校验数据格式的合法性
需求:假如现在要求校验一个qq号码是否
正确规则:6位及20位之内,0不能在开头,必须全部是数字
先使用目前所学知识完成校验需求然后体验一下正则表达式检验。
public static void main(String[] args) {
/*练习:
正则表达式可以校验字符串是否满足一定的规则,并用来校验数据格式的合法性
需求:假如现在要求校验一个qq号码是否
正确规则:6位及20位之内,0不能在开头,必须全部是数字
先使用目前所学知识完成校验需求然后体验一下正则表达式检验。*/
String qq = "1234567890";
boolean flag = CheckQQ(qq);
System.out.println(flag);
}
private static boolean CheckQQ(String qq) {
/*规则:6位及20位之内,0不能在开头,必须全部是数字*/
/*
* 核心思想:
* 先把异常数据进行过滤。
* 下面的就是满足要求的数据了
* */
//0. 6位及20位之内
int len = qq.length();
if (len < 6 || len > 20) {
return false;
}
//1. 0不能在开头
// qq.charAt(0);
if (qq.startsWith("0")) {
return false;
}
//2. 必须全部是数字
for (int i = 0; i < qq.length(); i++) {
char c = qq.charAt(i);
if (c < '0' || c > '9'){
return false;
}
}
return true;
}使用正则表达式仅需一行代码皆可
/*使用正则表达式*/
boolean matches = qq.matches("[1-9]\d{5,19}");
System.out.println(matches);正则表达式的作用
作用 0:检验字符串是否满足规则
作用 1:在一段文本中查找满足要求的内容
正则表达式

字符类(只匹配一个字符)
public static void main(String[] args) {
//只能是 a b c
System.out.println("-------------1-------------");
System.out.println("a".matches("[abc]")); // true
System.out.println("z".matches("[abc]")); // false
System.out.println("ab".matches("[abc]")); // false
System.out.println("ab".matches("[abc][abc]")); // true
//不能出现 a b c
System.out.println("-------------2-------------");
System.out.println("a".matches("[^abc]")); // false
System.out.println("z".matches("[^abc]")); // true
System.out.println("zz".matches("[^abc]")); // false
System.out.println("zz".matches("[^abc][^abc]")); // true
// a到z,A到Z
System.out.println("-------------3-------------");
System.out.println("a".matches("[a-zA-Z]")); // true
System.out.println("z".matches("[a-zA-Z]")); // true
System.out.println("aa".matches("[a-zA-Z]")); // false
System.out.println("aa".matches("[a-zA-Z][a-zA-Z]")); // true
System.out.println("0".matches("[a-zA-Z]")); // false
// [a-d[m-p]] a到d 或m到p
System.out.println("-------------4-------------");
System.out.println("a".matches("[a-d[m-p]]")); //true
System.out.println("d".matches("[a-d[m-p]]")); //true
System.out.println("m".matches("[a-d[m-p]]")); //true
System.out.println("p".matches("[a-d[m-p]]")); //true
System.out.println("e".matches("[a-d[m-p]]")); //false
System.out.println("0".matches("[a-d[m-p]]")); //false
// [a-z&&[def]] a-z和def的交集。为:d,e,f
System.out.println("-------------5-------------");
System.out.println("a".matches("[a-z&&[def]]")); //false
System.out.println("d".matches("[a-z&&[def]]")); //true
System.out.println("0".matches("[a-z&&[def]]")); //false
// [a-z&&[^bc]] a-z和非bc的交集(等同于[ad-z]
System.out.println("-------------6-------------");
System.out.println("a".matches("[a-z&&[^bc]]")); //true
System.out.println("b".matches("[a-z&&[^bc]]")); //false
System.out.println("0".matches("[a-z&&[^bc]]")); //false
// [a-z&&[^m-p]] a到z除了m到p的交集(等同于[a-lq-z]
System.out.println("-------------7-------------");
System.out.println("a".matches("[a-z&&[^m-p]]"));//true
System.out.println("m".matches("[a-z&&[^m-p]]"));//false
System.out.println("0".matches("[a-z&&[^m-p]]"));//false
}预定义字符(只匹配一个字符)
public static void main(String[] args) {
// 转义字符 改变后面那个字符原本的含义
// . 表示任意一个字符
System.out.println("----------------1-----------------");
System.out.println("你".matches(".")); // true
System.out.println("你".matches("..")); // false
System.out.println("你a".matches("..")); // true
// \d只能是任意的一位数字
System.out.println("----------------2-----------------");
System.out.println("a".matches("\d")); // false
System.out.println("3".matches("\d")); // true
System.out.println("333".matches("\d")); // false
// \w只能是一位单词字符 [a-zA-Z_0-9]
System.out.println("----------------3-----------------");
System.out.println("z".matches("\w")); // true
System.out.println("2".matches("\w")); // true
System.out.println("21".matches("\w")); // false
System.out.println("你".matches("\w")); // false
// 非单词字符
System.out.println("----------------4-----------------");
System.out.println("你".matches("\W")); // true
//以上正则匹配只能校验单个字符
}数量词

public static void main(String[] args) {
// 必须是数字 字母 下划线 至少 6 位
System.out.println("2442fsfsfsf".matches("\w{6,}")); // true
System.out.println("2442".matches("\w{6,}")); // false
// 必须是数字和字符 必须是4位
System.out.println("23df".matches("[a-zA-Z0-9]{4}"));//true
System.out.println("23_f".matches("[a-zA-Z0-9]{4}"));//false
System.out.println("23df".matches("[\w&&[^_]]{4}"));//true
System.out.println("23_f".matches("[\w&&[^_]]{4}"));//false
}类 Pattern
正则表达式的编译表示形式。
指定为字符串的正则表达式必须首先被编译为此类的实例。然后,可将得到的模式用于创建 Matcher 对象,依照正则表达式,该对象可以与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一模式。
因此,典型的调用顺序是
Pattern p = Pattern.compile("a*b"); Matcher m = p.matcher("aaaaab"); boolean b = m.matches();
在仅使用一次正则表达式时,可以方便地通过此类定义 matches 方法。此方法编译表达式并在单个调用中将输入序列与其匹配。语句
boolean b = Pattern.matches("a*b", "aaaaab");
等效于上面的三个语句,尽管对于重复的匹配而言它效率不高,因为它不允许重用已编译的模式。
此类的实例是不可变的,可供多个并发线程安全使用。Matcher 类的实例用于此目的则不安全。
正则表达式的构造摘要
| 构造 | 匹配 |
|---|---|
| 字符 | |
| x | 字符 x |
| \ | 反斜线字符 |
| n | 带有八进制值 0 的字符 n (0 <= n <= 7) |
| nn | 带有八进制值 0 的字符 nn (0 <= n <= 7) |
| mnn | 带有八进制值 0 的字符 mnn(0 <= m <= 3、0 <= n <= 7) |
| xhh | 带有十六进制值 0x 的字符 hh |
| uhhhh | 带有十六进制值 0x 的字符 hhhh |
| t | 制表符 (‘u0009’) |
| n | 新行(换行)符 (‘u000A’) |
| r | 回车符 (‘u000D’) |
| f | 换页符 (‘u000C’) |
| a | 报警 (bell) 符 (‘u0007’) |
| e | 转义符 (‘u001B’) |
| cx | 对应于 x 的控制符 |
| 字符类 | |
| [abc] | a、b 或 c(简单类) |
| [^abc] | 任何字符,除了 a、b 或 c(否定) |
| [a-zA-Z] | a 到 z 或 A 到 Z,两头的字母包括在内(范围) |
| [a-d[m-p]] | a 到 d 或 m 到 p:[a-dm-p](并集) |
| [a-z&&[def]] | d、e 或 f(交集) |
| [a-z&&[^bc]] | a 到 z,除了 b 和 c:[ad-z](减去) |
| [a-z&&[^m-p]] | a 到 z,而非 m 到 p:[a-lq-z](减去) |
| 预定义字符类 | |
| . | 任何字符(与行结束符可能匹配也可能不匹配) |
| d | 数字:[0-9] |
| D | 非数字: [^0-9] |
| s | 空白字符:[ tnx0Bfr] |
| S | 非空白字符:[^s] |
| w | 单词字符:[a-zA-Z_0-9] |
| W | 非单词字符:[^w] |
| POSIX 字符类(仅 US-ASCII) | |
| p{Lower} | 小写字母字符:[a-z] |
| p{Upper} | 大写字母字符:[A-Z] |
| p{ASCII} | 所有 ASCII:[x00-x7F] |
| p{Alpha} | 字母字符:[p{Lower}p{Upper}] |
| p{Digit} | 十进制数字:[0-9] |
| p{Alnum} | 字母数字字符:[p{Alpha}p{Digit}] |
| p{Punct} | 标点符号:!”#$%&'()*+,-./:;<=>?@[]^_`{|}~ |
| p{Graph} | 可见字符:[p{Alnum}p{Punct}] |
| p{Print} | 可打印字符:[p{Graph}x20] |
| p{Blank} | 空格或制表符:[ t] |
| p{Cntrl} | 控制字符:[x00-x1Fx7F] |
| p{XDigit} | 十六进制数字:[0-9a-fA-F] |
| p{Space} | 空白字符:[ tnx0Bfr] |
| java.lang.Character 类(简单的 java 字符类型) | |
| p{javaLowerCase} | 等效于 java.lang.Character.isLowerCase() |
| p{javaUpperCase} | 等效于 java.lang.Character.isUpperCase() |
| p{javaWhitespace} | 等效于 java.lang.Character.isWhitespace() |
| p{javaMirrored} | 等效于 java.lang.Character.isMirrored() |
| Unicode 块和类别的类 | |
| p{InGreek} | Greek 块(简单块)中的字符 |
| p{Lu} | 大写字母(简单类别) |
| p{Sc} | 货币符号 |
| P{InGreek} | 所有字符,Greek 块中的除外(否定) |
| [p{L}&&[^p{Lu}]] | 所有字母,大写字母除外(减去) |
| 边界匹配器 | |
| ^ | 行的开头 |
| $ | 行的结尾 |
| b | 单词边界 |
| B | 非单词边界 |
| A | 输入的开头 |
| G | 上一个匹配的结尾 |
| Z | 输入的结尾,仅用于最后的结束符(如果有的话) |
| z | 输入的结尾 |
| Greedy 数量词 | |
| X? | X,一次或一次也没有 |
| X* | X,零次或多次 |
| X+ | X,一次或多次 |
| X{n} | X,恰好 n 次 |
| X{n,} | X,至少 n 次 |
| X{n,m} | X,至少 n 次,但是不超过 m 次 |
| Reluctant 数量词 | |
| X?? | X,一次或一次也没有 |
| X*? | X,零次或多次 |
| X+? | X,一次或多次 |
| X{n}? | X,恰好 n 次 |
| X{n,}? | X,至少 n 次 |
| X{n,m}? | X,至少 n 次,但是不超过 m 次 |
| Possessive 数量词 | |
| X?+ | X,一次或一次也没有 |
| X*+ | X,零次或多次 |
| X++ | X,一次或多次 |
| X{n}+ | X,恰好 n 次 |
| X{n,}+ | X,至少 n 次 |
| X{n,m}+ | X,至少 n 次,但是不超过 m 次 |
| Logical 运算符 | |
| XY | X 后跟 Y |
| X|Y | X 或 Y |
| (X) | X,作为捕获组 |
| Back 引用 | |
| n | 任何匹配的 nth 捕获组 |
| 引用 | |
| Nothing,但是引用以下字符 | |
| Q | Nothing,但是引用所有字符,直到 E |
| E | Nothing,但是结束从 Q 开始的引用 |
| 特殊构造(非捕获) | |
| (?:X) | X,作为非捕获组 |
| (?idmsux-idmsux) | Nothing,但是将匹配标志i d m s u x on – off |
| (?idmsux-idmsux:X) | X,作为带有给定标志 i d m s u x on – off |
| 的非捕获组 | |
| (?=X) | X,通过零宽度的正 lookahead |
| (?!X) | X,通过零宽度的负 lookahead |
| (?<=X) | X,通过零宽度的正 lookbehind |
| (?<!X) | X,通过零宽度的负 lookbehind |
| (?>X) | X,作为独立的非捕获组 |
反斜线、转义和引用
反斜线字符 (”) 用于引用转义构造,如上表所定义的,同时还用于引用其他将被解释为非转义构造的字符。因此,表达式 \ 与单个反斜线匹配,而 { 与左括号匹配。
在不表示转义构造的任何字母字符前使用反斜线都是错误的;它们是为将来扩展正则表达式语言保留的。可以在非字母字符前使用反斜线,不管该字符是否非转义构造的一部分。
根据 Java Language Specification 的要求,Java 源代码的字符串中的反斜线被解释为 Unicode 转义或其他字符转义。因此必须在字符串字面值中使用两个反斜线,表示正则表达式受到保护,不被 Java 字节码编译器解释。例如,当解释为正则表达式时,字符串字面值 “b” 与单个退格字符匹配,而 “\b” 与单词边界匹配。字符串字面值 “(hello)” 是非法的,将导致编译时错误;要与字符串 (hello) 匹配,必须使用字符串字面值 “\(hello\)”。
字符类
字符类可以出现在其他字符类中,并且可以包含并集运算符(隐式)和交集运算符 (&&)。并集运算符表示至少包含其某个操作数类中所有字符的类。交集运算符表示包含同时位于其两个操作数类中所有字符的类。
字符类运算符的优先级如下所示,按从最高到最低的顺序排列:
1 字面值转义 x 2 分组 […] 3 范围 a-z 4 并集 [a-e][i-u] 5 交集 [a-z&&[aeiou]]
注意,元字符的不同集合实际上位于字符类的内部,而非字符类的外部。例如,正则表达式 . 在字符类内部就失去了其特殊意义,而表达式 – 变成了形成元字符的范围。
行结束符
行结束符 是一个或两个字符的序列,标记输入字符序列的行结尾。以下代码被识别为行结束符:
- 新行(换行)符 (‘n’)、
- 后面紧跟新行符的回车符 (“rn”)、
- 单独的回车符 (‘r’)、
- 下一行字符 (‘u0085’)、
- 行分隔符 (‘u2028’) 或
- 段落分隔符 (‘u2029)。
如果激活
UNIX_LINES模式,则新行符是唯一识别的行结束符。如果未指定
DOTALL标志,则正则表达式 . 可以与任何字符(行结束符除外)匹配。默认情况下,正则表达式 ^ 和 $ 忽略行结束符,仅分别与整个输入序列的开头和结尾匹配。如果激活
MULTILINE模式,则 ^ 在输入的开头和行结束符之后(输入的结尾)才发生匹配。处于MULTILINE模式中时,$ 仅在行结束符之前或输入序列的结尾处匹配。组和捕获
捕获组可以通过从左到右计算其开括号来编号。例如,在表达式 ((A)(B(C))) 中,存在四个这样的组:
1 ((A)(B(C))) 2 A 3 (B(C)) 4 (C) 组零始终代表整个表达式。
之所以这样命名捕获组是因为在匹配中,保存了与这些组匹配的输入序列的每个子序列。捕获的子序列稍后可以通过 Back 引用在表达式中使用,也可以在匹配操作完成后从匹配器获取。
与组关联的捕获输入始终是与组最近匹配的子序列。如果由于量化的缘故再次计算了组,则在第二次计算失败时将保留其以前捕获的值(如果有的话)例如,将字符串 “aba” 与表达式 (a(b)?)+ 相匹配,会将第二组设置为 “b”。在每个匹配的开头,所有捕获的输入都会被丢弃。
以 (?) 开头的组是纯的非捕获 组,它不捕获文本,也不针对组合计进行计数。
Unicode 支持
此类符合 Unicode Technical Standard #18:Unicode Regular Expression Guidelines 第 1 级和 RL2.1 Canonical Equivalents。
Java 源代码中的 Unicode 转义序列(如 u2014)是按照 Java Language Specification 的 第 3.3 节中的描述处理的。这样的转义序列还可以由正则表达式解析器直接实现,以便在从文件或键盘击键读取的表达式中使用 Unicode 转义。因此,可以将不相等的字符串 “u2014” 和 “\u2014” 编译为相同的模式,从而与带有十六进制值 0x2014 的字符匹配。
与 Perl 中一样,Unicode 块和类别是使用 p 和 P 构造编写的。如果输入具有属性 prop,则与 p{prop} 匹配,而输入具有该属性时与 P{prop} 不匹配。块使用前缀 In 指定,与在 InMongolian 中一样。可以使用可选前缀 Is 指定类别:p{L} 和 p{IsL} 都表示 Unicode 字母的类别。块和类别在字符类的内部和外部都可以使用。
受支持的类别是由
Character类指定版本中的 The Unicode Standard 的类别。类别名称是在 Standard 中定义的,即标准又丰富。Pattern所支持的块名称是UnicodeBlock.forName所接受和定义的有效块名称。行为类似 java.lang.Character boolean 是 methodname 方法(废弃的类别除外)的类别,可以通过相同的 p{prop} 语法来提供,其中指定的属性具有名称 javamethodname。
与 Perl 5 相比较
Pattern引擎用有序替换项执行传统上基于 NFA 的匹配,与 Perl 5 中进行的相同。此类不支持 Perl 构造:
-
条件构造 (?{X}) 和 (?(condition)X|Y)、
-
嵌入式代码构造 (?{code}) 和 (??{code})、
-
嵌入式注释语法 (?#comment) 和
-
预处理操作 l u、L 和 U。
此类支持但 Perl 不支持的构造:
-
Possessive 数量词,它可以尽可能多地进行匹配,即使这样做导致所有匹配都成功时也如此。
-
字符类并集和交集,如上文所述。
与 Perl 的显著不同点是:
-
在 Perl 中,1 到 9 始终被解释为 Back 引用;如果至少存在多个子表达式,则大于 9 的反斜线转义数按 Back 引用对待,否则在可能的情况下,它将被解释为八进制转义。在此类中,八进制转义必须始终以零开头。在此类中,1 到 9 始终被解释为 Back 引用,较大的数被接受为 Back 引用,如果在正则表达式中至少存在多个子表达式的话;否则,解析器将删除数字,直到该数小于等于组的现有数或者其为一个数字。
-
Perl 使用 g 标志请求恢复最后匹配丢失的匹配。此功能是由
Matcher类显式提供的:重复执行find方法调用可以恢复丢失的最后匹配,除非匹配器被重置。 -
在 Perl 中,位于表达式顶级的嵌入式标记对整个表达式都有影响。在此类中,嵌入式标志始终在它们出现的时候才起作用,不管它们位于顶级还是组中;在后一种情况下,与在 Perl 中类似,标志在组的结尾处还原。
-
Perl 允许错误匹配构造,如在表达式 *a 中,以及不匹配的括号,如在在表达式 abc] 中,并将其作为字面值对待。此类还接受不匹配的括号,但对 +、? 和 * 不匹配元字符有严格限制;如果遇到它们,则抛出
PatternSyntaxException。
- 行分隔符 (‘u2028’) 或
- 下一行字符 (‘u0085’)、
- 单独的回车符 (‘r’)、
- 后面紧跟新行符的回车符 (“rn”)、
| 字段摘要 | |
|---|---|
static int |
CANON_EQ启用规范等价。 |
static int |
CASE_INSENSITIVE启用不区分大小写的匹配。 |
static int |
COMMENTS模式中允许空白和注释。 |
static int |
DOTALL启用 dotall 模式。 |
static int |
LITERAL启用模式的字面值解析。 |
static int |
MULTILINE启用多行模式。 |
static int |
UNICODE_CASE启用 Unicode 感知的大小写折叠。 |
static int |
UNIX_LINES启用 Unix 行模式。 |
| 方法摘要 | |
|---|---|
static Pattern |
compile(String regex)将给定的正则表达式编译到模式中。 |
static Pattern |
compile(String regex, int flags)将给定的正则表达式编译到具有给定标志的模式中。 |
int |
flags()返回此模式的匹配标志。 |
Matcher |
matcher(CharSequence input)创建匹配给定输入与此模式的匹配器。 |
static boolean |
matches(String regex, CharSequence input)编译给定正则表达式并尝试将给定输入与其匹配。 |
String |
pattern()返回在其中编译过此模式的正则表达式。 |
static String |
quote(String s)返回指定 String 的字面值模式 String。 |
String[] |
split(CharSequence input)围绕此模式的匹配拆分给定输入序列。 |
String[] |
split(CharSequence input, int limit)围绕此模式的匹配拆分给定输入序列。 |
String |
toString()返回此模式的字符串表示形式。 |
| 从类 java.lang.Object 继承的方法 |
|---|
clone, equals, finalize, getClass, hashCode, notify, notifyAll, wait, wait, wait |
练习2:
- 请编写正则表达式验证用户输入的手机号码是否满足要求
- 请编写正则表达式验证用户输入的邮箱号是否满足要求
- 请编写正则表达式验证用户输入的座机号码号是否满足要求
public static void main(String[] args) {
/*验证手机号码 13112345678 13712345667 13945679027 139456790271
验证座机电话号码 020-2324242 02122442 027-42424 0712-3242434
验证邮箱号码 3232323@qq.com zhangsan@itcast,cnn dlei0009@163.com dleigee9@pci.com.cn*/
//请编写正则表达式验证用户输入的手机号码是否满足要求
//13112345678
String regex1 = "1[3-9]\d{9}"; // 1[3-9][0-9]{9}
System.out.println("13112345678".matches(regex1));//true
System.out.println("1311234578".matches(regex1));//false
System.out.println("=========================");
//请编写正则表达式验证用户输入的邮箱号是否满足要求
// 3232323@qq.com zhangsan@itcast,cnn dlei0009@163.com dleigee9@pci.com.cn
String regex2 = "\w+@[\w&&[^_]]{2,6}(\.[a-zA-Z]{2,3}){1,2}";
System.out.println("3232323@qq.com".matches(regex2));//true
System.out.println("3232323qq.com".matches(regex2));//false
System.out.println("=========================");
//请编写正则表达式验证用户输入的座机号码号是否满足要求
//020-2324242 02122442 027-42424 0712-3242434
String regex3 = "0\d{2,3}-?[1-9]\d{4,9}";
System.out.println("020-2324242".matches(regex3));//true
System.out.println("020-0324242".matches(regex3));//false
}关于正则表达式可以使用插件生成



String regex4 ="(?:[01]\d|2[0-3]):[0-5]\d:[0-5]\d";
String regex5 ="([01]\d|2[0-3])(:[0-5]\d){2}";
System.out.println("15:50:23".matches(regex4)); // true
System.out.println("15:50:23".matches(regex5)); // true练习3:
需求:
- 请编写正则表达式验证用户名是否满足要求
要求:大小写字母,数字,下划线一共4-16位
- 请编写正则表达式验证身份证号码是否满足要求。
简单要求:18位,前17位任意数字,最后一位可以是数字可以是大写或小写的X
复杂要求:按照身份证号码的格式严格要求。
public static void main(String[] args) {
/*需求:
请编写正则表达式验证用户名是否满足要求
要求:大小写字母,数字,下划线一共4-16位
请编写正则表达式验证身份证号码是否满足要求。
简单要求:18位,前17位任意数字,最后一位可以是数字可以是大写或小写的X
复杂要求:按照身份证号码的格式严格要求。*/
//验证用户名 要求:大小写字母,数字,下划线一共4-16位
String regex1 = "\w{4,16}";
System.out.println("zhangsan".matches(regex1)); //true
System.out.println("lisi".matches(regex1)); //true
System.out.println("$123".matches(regex1)); //false
System.out.println("=============1===============");
//验证身份证号码是否满足要求
//简单要求:18位,前17位任意数字,最后一位可以是数字可以是大写或小写的X
String regex2 = "[1-9]\d{16}(\d|X|x)";
String regex3 = "[1-9]\d{16}[\dXx]";
String regex6 = "[1-9]\d{16}(\d|(?i)x)";
System.out.println("41080119930228457x".matches(regex6));
System.out.println("510801197609022309".matches(regex6));
System.out.println("15010119810705387X".matches(regex6));
System.out.println("4108011993022845".matches(regex6)); //false
System.out.println("=============2===============");
//复杂要求:按照身份证号码的格式严格要求。
/*410801 1993 02 28 457x
* 前面6位:省份,市区,派出所等信息 第一位不能是0,后面5位是任意数字 [1-9]\d{5}
* 年的前半段:18 19 20 (18|19|20)
* 年的后半段:任意数字出现两次 \d{2}
* 月份: 01~09 10 11 12 (0[1-9]|1[0-2])
* 日期: 01-31 01~09 10~19 20~29 30 31 (0[1-9]|[12]\d|3[01])
* 后面四位: 任意数字出现3次,最后一位可以是数字,也可以是大写X或者小写x \d{3}(\d|(?i)x)
* */
String regex7 = "[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}(\d|(?i)x)";
String regex4 = "[1-9]\d{5}(?:18|19|20)\d{2}(?:0[1-9]|10|11|12)(?:0[1-9]|[1-2]\d|30|31)\d{3}[\dXx]";
System.out.println("41080119930028457x".matches(regex7)); //false 00月
System.out.println("510801197609022309".matches(regex7));
System.out.println("15010119810705387X".matches(regex7));
System.out.println("4108011993022845".matches(regex7)); //false
System.out.println("+++++++++++++++++++++++++++++");
//忽略大小写书写方式
String regex5 = "(?i)abc";
System.out.println("abc".matches(regex5));
System.out.println("ABC".matches(regex5)); //true
}忽略大小写书写方式
//忽略大小写书写方式
String regex5 = "(?i)abc";
System.out.println("abc".matches(regex5));
System.out.println("ABC".matches(regex5)); //true总结

编写正则表达式时,
- 第一步,按照正确的数据进行拆分
- 第二步,找每一部分的规律,并编写正则表达式
- 第三步,把每一部分的正则拼接在一起,就是最终的结果
书写的时候,从左到右去书写。
原文地址:https://blog.csdn.net/qq_72332648/article/details/135661526
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_58306.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!