这篇文章是笔者学习cpp多线程操作的第二篇笔记,没有阅读过第一篇的读者可以移步此处:
如果读者发现我的文章里有问题,欢迎交流哈!
一、如何控制线程呢?
c++11在std::this_thread名称空间(显然,这是一个嵌套在大名称空间里的小名称空间)内定义了一系列公共函数来管理线程。
获得当前线程id
将当前线程时间片让渡给其他线程
当前线程休眠直到某个时间点
当前线程休眠一段时间
单纯看这些定义其实无法准确理解这些函数的意义。实践出真知,下面我们启动小实验来理解这些函数。
实验一:使用get_id
#include <iostream>
#include <thread>
void func1(void)
{
std::thread::id thread1_id=std::this_thread::get_id();
std::cout<<thread1_id<<std::endl;
}
int main(void)
{
std::thread thread1(func1);
thread1.join();
std::thread::id mainthread_id=std::this_thread::get_id();
std::cout<<mainthread_id<<std::endl;
} 输出结果:
2
1
由此我们发现:
1、get_id函数必须包含在名称空间std::this_thread里
2、get_id函数一般是没有参数的
3、查阅资料发现,get_id函数的返回值的具体类型由编译器定义。但是,任何编译器都定义了std::thread::id这一结构(类)来储存线程id。std::cout函数可以直接打印这一类型
4、在子线程和主线程中均可以使用get_id()
实验二:使用yield
yield函数的使用方法和get_id类似。
调用std::this_thread::yield()时,当前线程会主动放弃执行权,使得操作系统的线程调度器可以重新安排其他可运行的线程来执行。这样做可以提高多线程程序的执行效率和公平性。
需要注意的是,std::this_thread::yield()只是一个建议,具体的线程调度行为取决于操作系统和调度器的实现。在某些情况下,调度器可能会忽略该建议,继续让当前线程执行。
#include <iostream>
#include <thread>
#include <windows.h>
void func1(void)
{
std::this_thread::yield();
while(true)
{
std::this_thread::yield();
std::cout<<"thread1"<<std::endl;
Sleep(1000);
}
}
void func2(void)
{
while(true)
{
std::cout<<"thread2"<<std::endl;
Sleep(1000);
}
}
int main(void)
{
std::thread thread1(func1);
std::thread thread2(func2);
thread1.join();
thread2.join();
} 输出结果:
thread1thread2
thread2
thread1
thread2thread1……
可以看到,由于yield的作用,从第二次打印开始,thread2往往比thread1能够先进行打印。而如果注释掉std::this_thread::yield(),那么由于thread1比thread2先定义,thread1往往比thread2先打印。
实验三:使用sleep_for
下面的程序,主线程打印1 2 3,子线程打印4 5 6。为了让打印的数字是有顺序的,使用sleep_for函数让子线程暂停1秒,等待主线程的打印结束。(当然,现实中写程序肯定不会这么设计,我只是在呈现一种最简单的情况)
注意,这里使用了std::chorno::seconds,这是定义在chrono库中的一个类,用于表示时间。
#include <iostream>
#include <thread>
#include <chrono>
void func1(void)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
for(int i=4;i<=6;i++)
std::cout<<i<<std::endl;
}
int main(void)
{
std::thread thread1(func1);
for (int i=1;i<=3;i++)
std::cout<<i<<std::endl;
thread1.join();
} 输出结果:
1
2
3
4
5
6
由此我们发现:
1、sleep_for()函数的参数可以是std::chrono::seconds类型,也可以是chrono库中其他时间类型
2、sleep_for()函数没有返回参数
二、互斥锁mutex
1、为什么引入锁这个概念?
先看这段两线程轮流打印的代码:
#include <iostream>
#include <thread>
#include <windows.h>
void func1(void)
{
while(true)
{
std::cout<<"thread1"<<std::endl;
Sleep(1000);
}
}
void func2(void)
{
while(true)
{
std::cout<<"thread2"<<std::endl;
Sleep(1000);
}
}
int main(void)
{
std::thread thread1(func1);
std::thread thread2(func2);
thread1.join();
thread2.join();
} 正如我们之前所展示的那样,由于thread1和thread2轮流占用std::cout这一输出流对象,导致输出结果并不是我们想象的那样规整:
thread1
thread2
thread1
thread2
而是会出现这样的情况
thread1thread2
thread1
thread2
所以,我们引入mutex互斥锁这一概念。通过mutex锁的操作,使当thread1使用输出流对象时,把输出流对象锁住。这样,thread2将不被允许使用输出流对象。
#include <iostream>
#include <thread>
#include <windows.h>
#include <mutex>
std::mutex mtx;
void func1(void)
{
while(true)
{
mtx.lock();
std::cout<<"thread1"<<std::endl;
Sleep(1000);
mtx.unlock();
}
}
void func2(void)
{
while(true)
{
mtx.lock();
std::cout<<"thread2"<<std::endl;
Sleep(1000);
mtx.unlock();
}
}
int main(void)
{
std::thread thread1(func1);
std::thread thread2(func2);
thread1.join();
thread2.join();
} 读者可以自行验证上面这段代码,输出结果将非常规整,不会出现上面那种情况。这就使锁所产生的效果。
2、如何理解锁的概念?
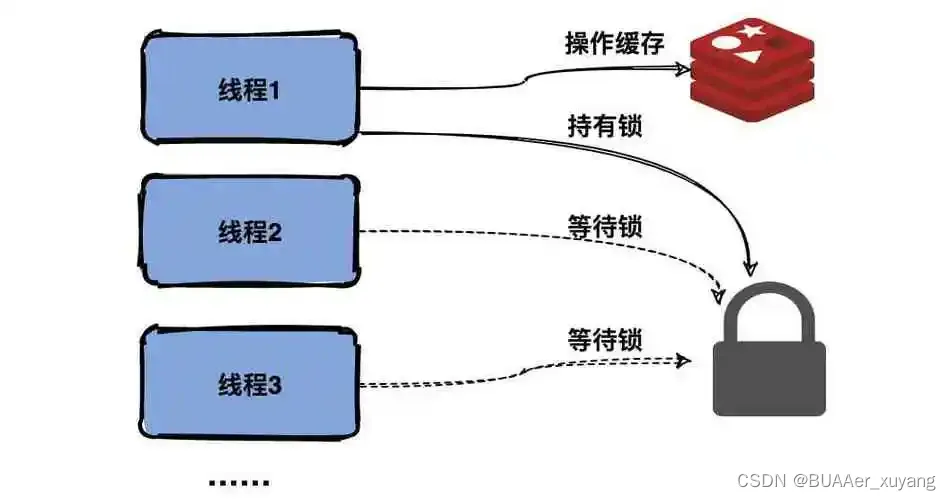
如果把内存比作一个个小房间,那么各个线程就要在各个房间里存取数据。如果两个线程同时存取数据,可能会造成一些错误。所以,当线程1在这个房间里存储数据时,就需要把这个房间锁住。线程2若要使用这个房间的数据,就要在外面等待。(具体的方式有线程阻塞,停止执行,即互斥锁;也有循环等待直到锁被打开,即自旋锁)
3、C++如何定义锁?
c++11的mutex库中定义了std::mutex类,作为操作锁的句柄,用来管理锁的各种行为。mutex类的具体实现对用户封闭,下面只介绍一些对外的接口(API)。了解这些接口(包括mutex的构造函数和公有函数)即可实现锁的操作。
–实例化锁对象
通常把锁对象实例化为全局变量:
#include <mutex>
//mutex类被定义在mutex中
std::mutex mtx;
void func()
{}
int main()
{}
–最简单的上锁和解锁
对mtx使用lock()方法,可以实现上锁操作。使用unlock()方法,可以解锁
假若线程1运行的是func函数,value是定义在全局的变量。
int value=0;
std::mutex mtx;
void func()
{
mtx.lock();
value+=1;
mtx.unlock();
}那么,在func1访问改写value变量前,添加mtx.lock()语句可以对value变量上锁;此时只有线程1可以访问value,确保了数据安全。改写完毕,使用mtx.unlock()解锁。
可以形象地理解mtx.lock()——这句话就好像给线程1一大把锁和钥匙,线程1要访问哪些变量(特指别的线程也可以访问地公共变量),就在访问时加一把锁,直到访问完成,才把它解开。在此期间,如果线程2也要访问这个变量,就会被暂停.直到线程1处理完毕,线程2才能被唤醒继续执行。
所以,锁这个类写的非常智能,优先拿到锁的线程要访问哪些对象,就把哪些对象锁住。
mtx.lock();
//这中间出现的变量,资源全部被锁保护,别人不许碰!!!
mtx.unlock();
//这之后出现的变量,就不一定是当前线程优先访问了!!!注意,解锁是非常重要的。试想,你使用一个房间后不解锁,直接翻窗走了(额,有点滑稽。但如果一个函数结束了,就是这样,直接消失),那么这个房间就一直锁住了,别人没有钥匙,不能用了。
–不同线程存在竞争关系
#include <iostream>
#include <thread>
#include <windows.h>
#include <mutex>
std::mutex mtx;
void func1(void)
{
while(true)
{
mtx.lock();
std::cout<<"thread1"<<std::endl;
Sleep(1000);
mtx.unlock();
}
}
void func2(void)
{
while(true)
{
mtx.lock();
std::cout<<"thread2"<<std::endl;
Sleep(1000);
mtx.unlock();
}
}
int main(void)
{
std::thread thread2(func2);
std::thread thread1(func1);
thread1.join();
thread2.join();
} 还是刚刚这一段代码,我们交换线程1和2的注册顺序。发现输出结果就变成了
thread2
thread1
thread2
……
这是由于thread2先注册,可以先抢夺锁的资源,拿到锁后,过河拆桥。不让thread1访问输出流对象了!(当然,thread2访问完毕后,还是要按照规则去唤醒thread1,所以第二个执行的必须是thread1线程)
4、其他方式实现锁
这里介绍mutex库中一个模板类——std::lock_guard。顾名思义,这个类模板实例化后能像保安一样帮我锁门开门(太形象了!)
把mtx.lock()出现的位置使用下面的语句:
std::lock_guard<std::mutex> mylock_guard(mtr);这是在使用类的构造函数,参数是之前定义的锁mtr。之后,在函数作用域中出现的全局变量和公共资源都会被锁住。
下面的示例代码就用两种方式实现了锁:
#include <iostream>
#include <thread>
#include <windows.h>
#include <mutex>
std::mutex mtx;
void func1(void)
{
while(true)
{
std::lock_guard<std::mutex> my_guard(mtx);
std::cout<<"thread1"<<std::endl;
Sleep(1000);
}
}
void func2(void)
{
while(true)
{
mtx.lock();
std::cout<<"thread2"<<std::endl;
Sleep(1000);
mtx.unlock();
}
}
int main(void)
{
std::thread thread2(func2);
std::thread thread1(func1);
thread1.join();
thread2.join();
} 可以发现,guard的作用区域是while循环内部。
这就像你雇佣了一群保安大叔,当你进入某个房间(内存)时,帮你锁上门;等你出来,自动帮你把门解锁了(怎么和现实相反了???)。
参考资料:
『面试问答』:互斥锁、自旋锁和读写锁的区别是什么?_哔哩哔哩_bilibili
C++多线程详解(全网最全) – 知乎 (zhihu.com)
原文地址:https://blog.csdn.net/BUAAer_xuyang/article/details/135671011
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_58394.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!