定义 User Case 和 约束
注意:没有一个面试官会阐述清楚问题,我们需要定义Use case和约束
Use cases
我们的作用域只是处理以下Use Case:
- Service 爬取一批 url
- 生成包含搜索词的单词到页面的反向索引
- 给页面生成标题和片段
- – 标题和片段是静态的,他们不会基于搜索语句改变
- User 输入一个搜索词然后看到相关页面的List, 伴随着爬虫生成的 title 和 snippet
- 只有描绘出High Level的组件和User Case的交互,不需要去深入
- Service有高可用
作用域外:
- 搜索分析
- 个人化的搜索结果
- 页面排名
约束和假设
状态假设:
- 流量分布不均匀
- 一些搜索访问非常频繁,当其他搜索都只是执行一次
- 只是支持匿名用户
- 生成搜索结果应该是很快的
- 这个 Web 爬虫不应该被阻塞在无限循环
- 如果这个图包含一个周期,我们将被阻塞在无限循环
- 10 亿link会被爬
- 页面需要被规律的爬去确保刷新
- 平均的刷新率应该是一次一周,热门网站应该更频繁
- – 每个月会爬4 亿 link
- 平均每个网页存储尺寸是:500 kb
- – 为了简化,计数和新页面相同
- 每个月1000 亿搜索
使用更传统的系统进行练习 – 不要使用现存的系统比如 solr 或者 nutch
计算使用量
和你的面试官说清楚你权衡之后选择的最优的方案
- 每个月 2 PB 的存储页面内容
- 500 KB 每页 * 40 亿 link / month
- 3年内存储 72 PB页面内容
- 1600 写请求 / s
- 40000 搜索请求 / s
便利的转换指南
- 每月有 250 万秒
- 1 请求 / 秒 = 250 万请求 / 月
- 40 请求 / 秒 = 一亿请求 / 月
- 400 请求 / 秒 = 十亿 请求 / 月
创建一个 High Level 设计
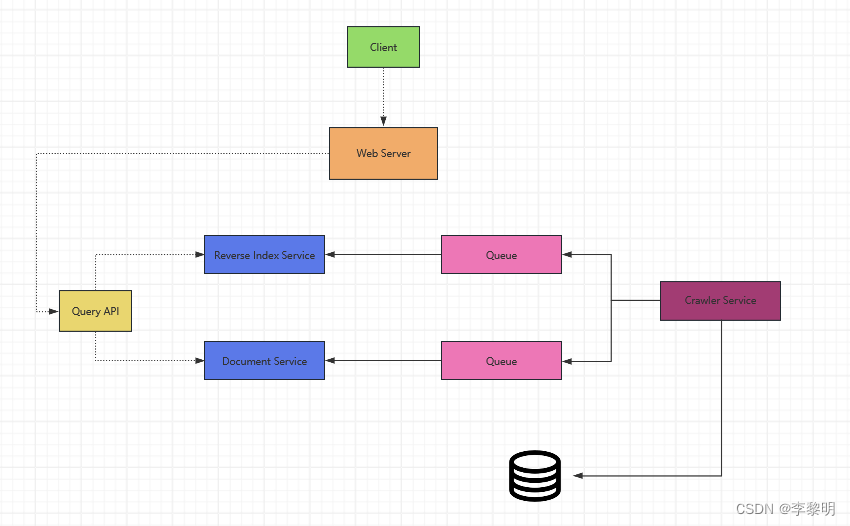
设计核心组件
Service 爬取 url 的 list
我们假设我们有一个初始化list links_to_crawl 基于整体站点流行度排序初始化,如果这不是一个合理的假设的话,我们可以搜索这个爬虫伴随着流行度网站。link到外面的内容,比如 Yahoo, DMOZ等
我们使用一个表 crawled_links 去存储处理过的link和他们的页面签名.
我们可以存储 links_to_crawl 和 crawled_links 在一个 key-value NoSQL Database. 对于排名的link 我们存进 links_to_crawl, 我们可以使用 Redis 伴随着 sorted set去维护一个页面link的排名。我们应该讨论不同 use case之间的最优解。
- Crawler Service 通过循环处理每个页面的link:
- 获取排名第一的page link给爬虫
- 检查在NoSQL数据库中
crawled_linksfor 一个有相同页面签名的 entry- If 我们有一个相同的 page,减少页面link的优先级
- 这将防止我们进入循环
- 继续
- Else 爬取这个 link
- 添加一个job到 Reverse Index Service的队列去生成一个 reverse index
- 添加一个 job 到 Document Service 队列去生成一个静态Title和代码片段
- 生成一个页面签名
- 从 links_to_crawl 移除 link 进 NoSQL Database
- 插入页面link和签名到
crawled_link进 NoSQL Database
- If 我们有一个相同的 page,减少页面link的优先级
- 检查在NoSQL数据库中
- 获取排名第一的page link给爬虫
PageDataStore 是一个抽象伴随着 Crawler Service,并且使用 NoSQL 数据库
class PagesDataStore(object):
def __init__(self, db);
self.db = db
...
def add_link_to_crawl(self, url):
"""Add the given link to `links_to_crawl`."""
...
def remove_link_to_crawl(self, url):
"""Remove the given link from `links_to_crawl`."""
...
def reduce_priority_link_to_crawl(self, url)
"""Reduce the priority of a link in `links_to_crawl` to avoid cycles."""
...
def extract_max_priority_page(self):
"""Return the highest priority link in `links_to_crawl`."""
...
def insert_crawled_link(self, url, signature):
"""Add the given link to `crawled_links`."""
...
def crawled_similar(self, signature):
"""Determine if we've already crawled a page matching the given signature"""
...
Page 是一个抽象伴随着 crawler service, 用来疯涨一个 Page, 他的内容, child urls,和签名
class Page(object):
def __init__(self, url, contents, child_urls, signature):
self.url = url
self.contents = contents
self.child_urls = child_urls
self.signature = signature
Crawler 是Crawler Service中的主类, 聚合 Page 和 PagesDataStore
class Crawler(object):
def __init__(self, data_store, reverse_index_queue, doc_index_queue):
self.data_store = data_store
self.reverse_index_queue = reverse_index_queue
self.doc_index_queue = doc_index_queue
def create_signature(self, page):
"""Create signature based on url and contents."""
...
def crawl_page(self, page):
for url in page.child_urls:
self.data_store.add_link_to_crawl(url)
page.signature = self.create_signature(page)
self.data_store.remove_link_to_crawl(page.url)
self.data_store.insert_crawled_link(page.url, page.signature)
def crawl(self):
while True:
page = self.data_store.extract_max_priority_page()
if page is None:
break
if self.data_store.crawled_similar(page.signature):
self.data_store.reduce_priority_link_to_crawl(page.url)
else:
self.crawl_page(page)
处理重复Link
我们需要小心这个Web爬虫不会被阻塞在一个无限循环里面,这种情况发生在graph包含一个Cycle.
我们需要去移除重复的 urls:
- 对于稍小的 list 我们可以使用 sort | unique
- 当有十亿 link需要爬时,我们可以使用 MapReduce 去输出,然后确定频率到1
class RemoveDuplicateUrls(MRJob):
def mapper(self, _, line):
yield line, 1
def reducer(self, key, values):
total = sum(values)
if total == 1:
yield key, total
检测重复内容是更加复杂的,我们可以基于页面的内容生成一个签名,然后基于这两个签名作比较,一些常见算法比如 Jaccard Index
决定什么时候去更新爬虫的结果
Pages 需要被常规的爬取用以刷新,爬取结果将有一个 timestamp 字段,用来指示这个pgae上一次被爬取的时间,在默认时间段,S一周所有的page会被刷新,频繁的更新或者更流行的网站会被刷新在更短的周期。
尽管我们不会深入分析细节,我们可以做一些数据修剪用来决定在特定页被更新的时间,而且使用 statistic 来决定重新爬取页面的频率
User Case: 用户输入一个搜索Term并且看到一个相关页面(包括title和片段)的list
- Client 发送一个请求到 Web Server
- Web Server 转发请求到 Query API server
- Query API server 做下面的事
- 解析 Query
- 移除 markup
- 分解 text 进 term
- 修复 typos
- 格式化首字母
- 转换 Query 去使用 bool 操作
- 使用 Reverse Index Service 去寻找匹配 query 的文档
- Reverse Index Service 排序匹配的结果,然后返回Top的记录
- 使用 Document Service 去返回 titles 和 文档片段
- 解析 Query
我们可以使用 public REST API:
$ curl https://search.com/api/v1/search?query=hello+world
Response:
{
"title": "foo's title",
"snippet": "foo's snippet",
"link": "https://foo.com",
},
{
"title": "bar's title",
"snippet": "bar's snippet",
"link": "https://bar.com",
},
{
"title": "baz's title",
"snippet": "baz's snippet",
"link": "https://baz.com",
},
扩展设计
在限制条件下,识别并解决瓶颈问题。
针对 Crawler Service目前发现这些优化点:
- 为了处理 data size 和 request load, Reverse Index Service 和 Document Service 将很有可能使用 Shadring 和 federation.
- DNS 查询会是一个 bottleneck, Crawler Service 会保持它自己的 DNS 查询,而且周期性刷新
- Crawler Service会提高性能并且减少内存使用(通过保持大量开放连接的方法),可以考虑切换到 UDP
- 网络爬虫是带宽密集型的,确保有足够的带宽来维持高吞吐量
原文地址:https://blog.csdn.net/weixin_44125071/article/details/135660533
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_58412.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!