本文介绍: 在本文中,TDengine 的资深研发将对多表低频场景写入性能的大幅优化工作进行深入分析介绍,并从实践层面剖析本次功能升级的具体作用。
在去年 8 月份发布的 3.1.0.0 版本中,TDengine 进行了一系列重要的企业级功能更新,其中包括对多表低频场景写入性能的大幅优化。这一优化工作为有此需求的用户提供了更大的便捷性和易用性。在本文中,TDengine 的资深研发将对此次优化工作进行深入分析介绍,并从实践层面剖析本次功能升级的具体作用。
三种时序场景分析
以 TDengine 的客户群体作为分析样本,我们发现,企业的时序场景大概可以分为以下三种类型:
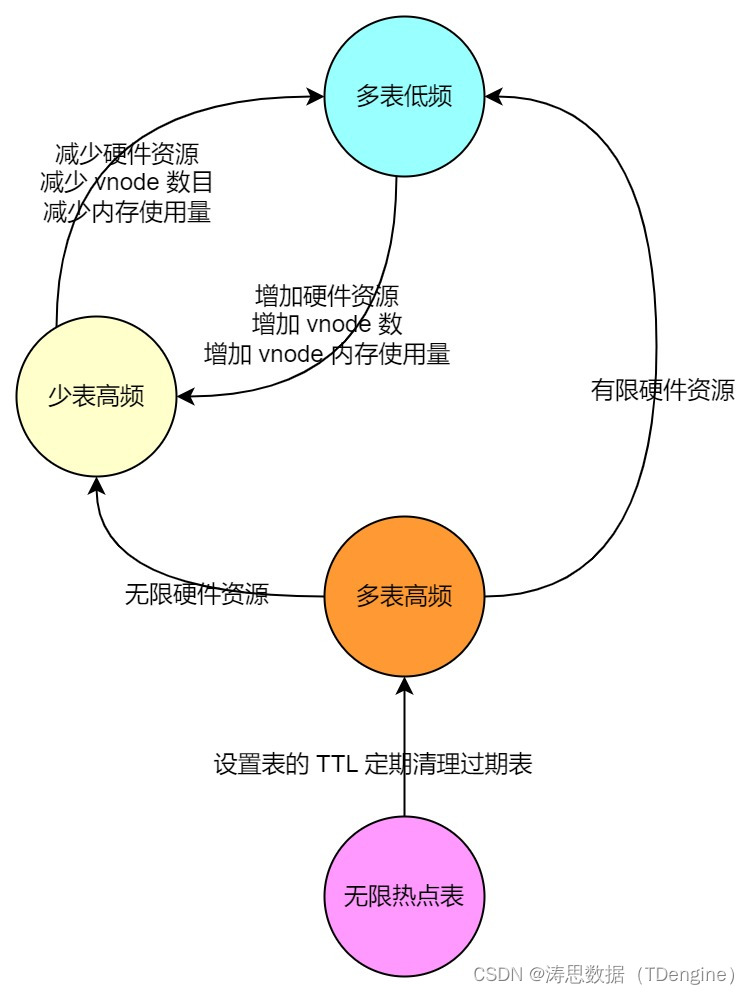
对于少表低频的场景来说,由于数据量不大,用任何方案都可以解决。而多表高频的场景,在有限的硬件资源下会转变为多表低频场景,在无限的硬件资源下,则会转变为少表高频场景。
在 TDengine 的用户群体中,部分多表低频的用户也可以通过增加节点,即增加 vnode 个数,使用更多的硬件资源将多表低频场景转化为了少表高频场景,从而较为高效地利用 TDengine 在少表高频场景下的高性能,但增加硬件资源本身和 TDengine 的初衷(为用户节省硬件资源)相违背。以北京燃气举例,在 300万+ 燃气表、每个燃气表每天采集一条记录的场景下,用 TDengine 3.0 处理,通过增大 vnode 个数将之转化为少表高频的场景后,相比用户以前用 Oracle 时成本并未节省多少。
对于无限热点表场景来说,如果用 TDengine 来处理该场景,随着时间的推移,表的数量会越来越多,效率会越来越低,成本会越来越高直至不可用。不过,TDengine 3.0 提供了表的 TTL(Time-To-Live)功能,用户可以通过该功能设置过期表自动删除,从而控制表的数目不至于达到无限。但该场景最终也退化成了多表高频场景。
TDengine 存储引擎设计概述

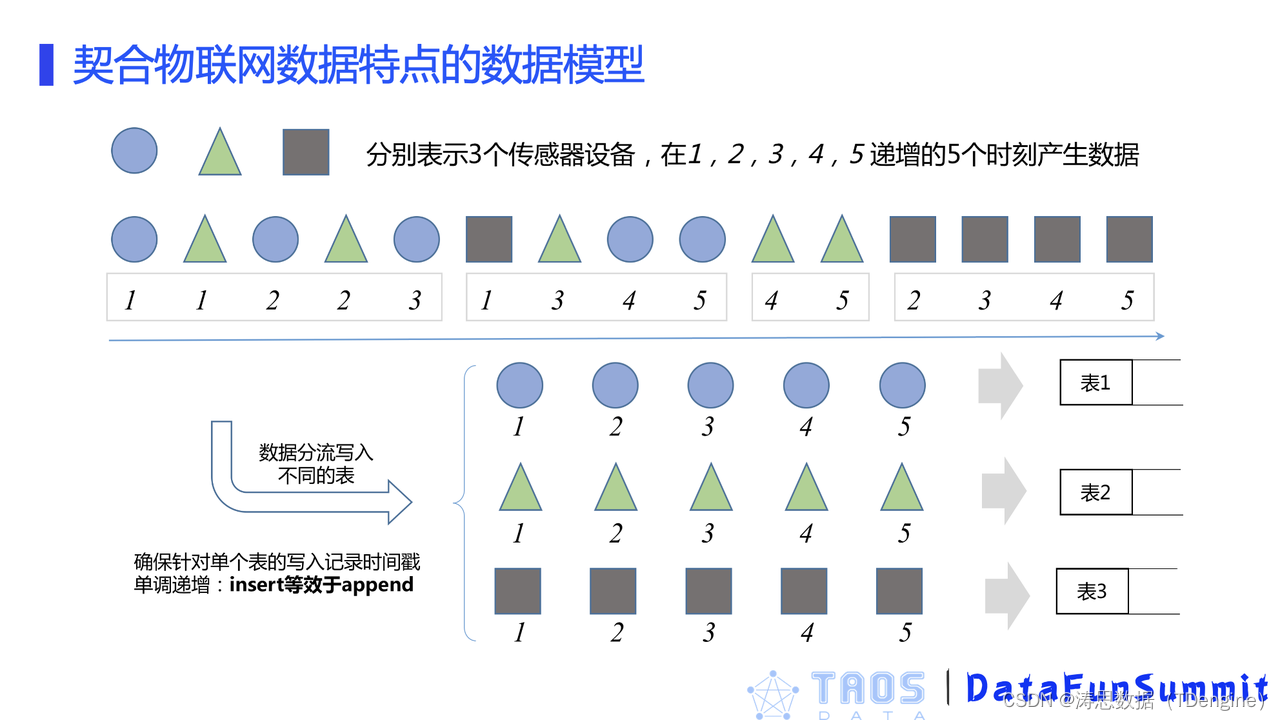
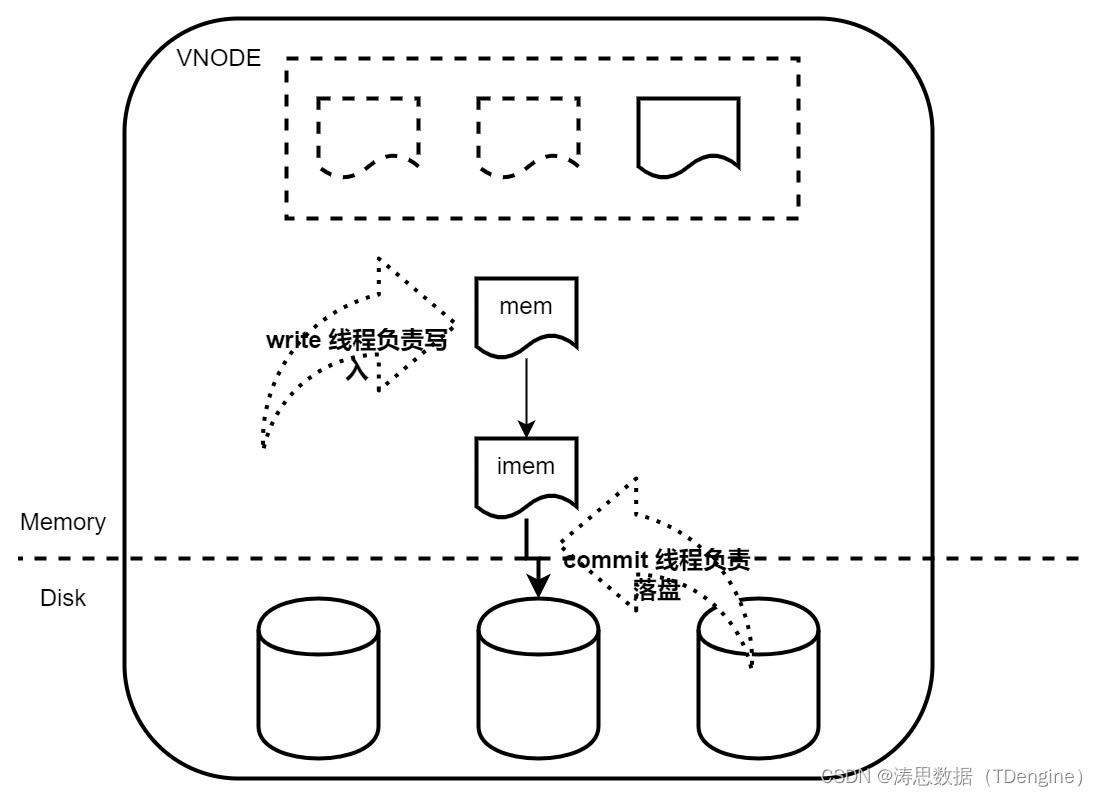
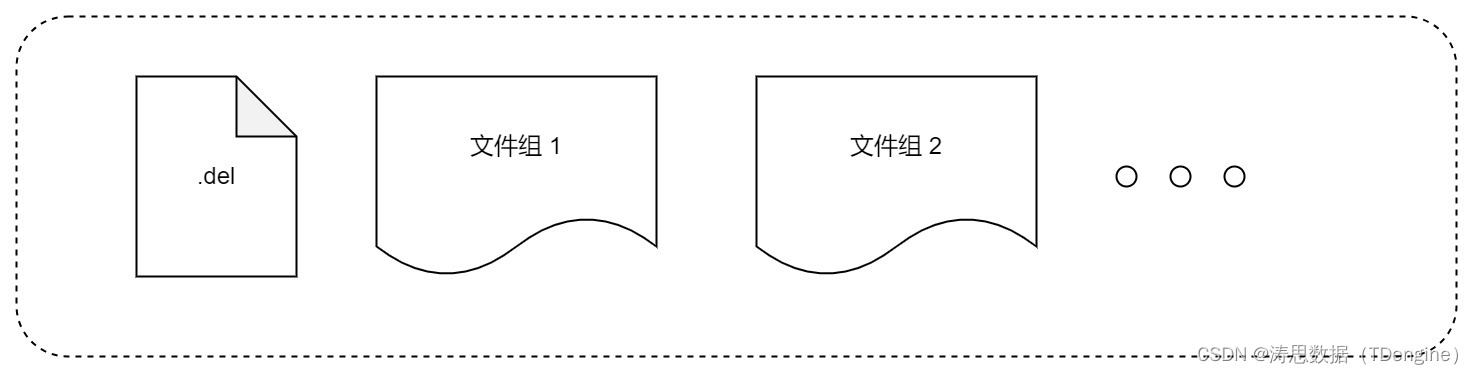
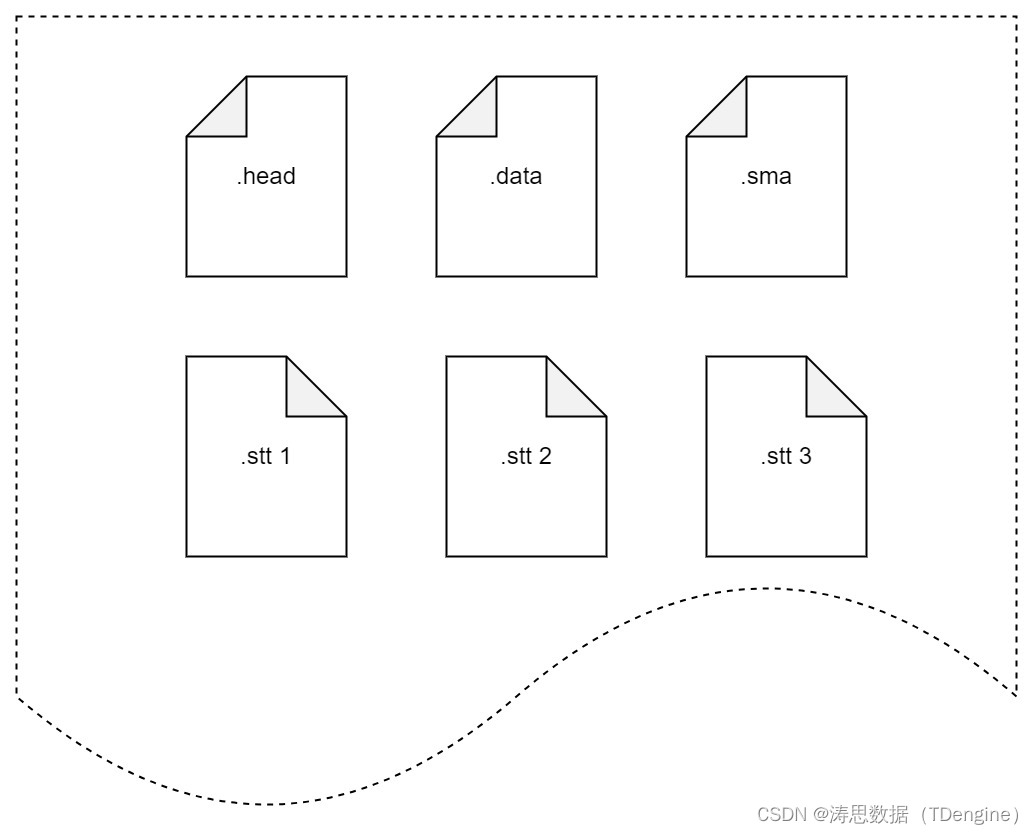
存储引擎优化工作的具体展开
明确优化要解决的问题


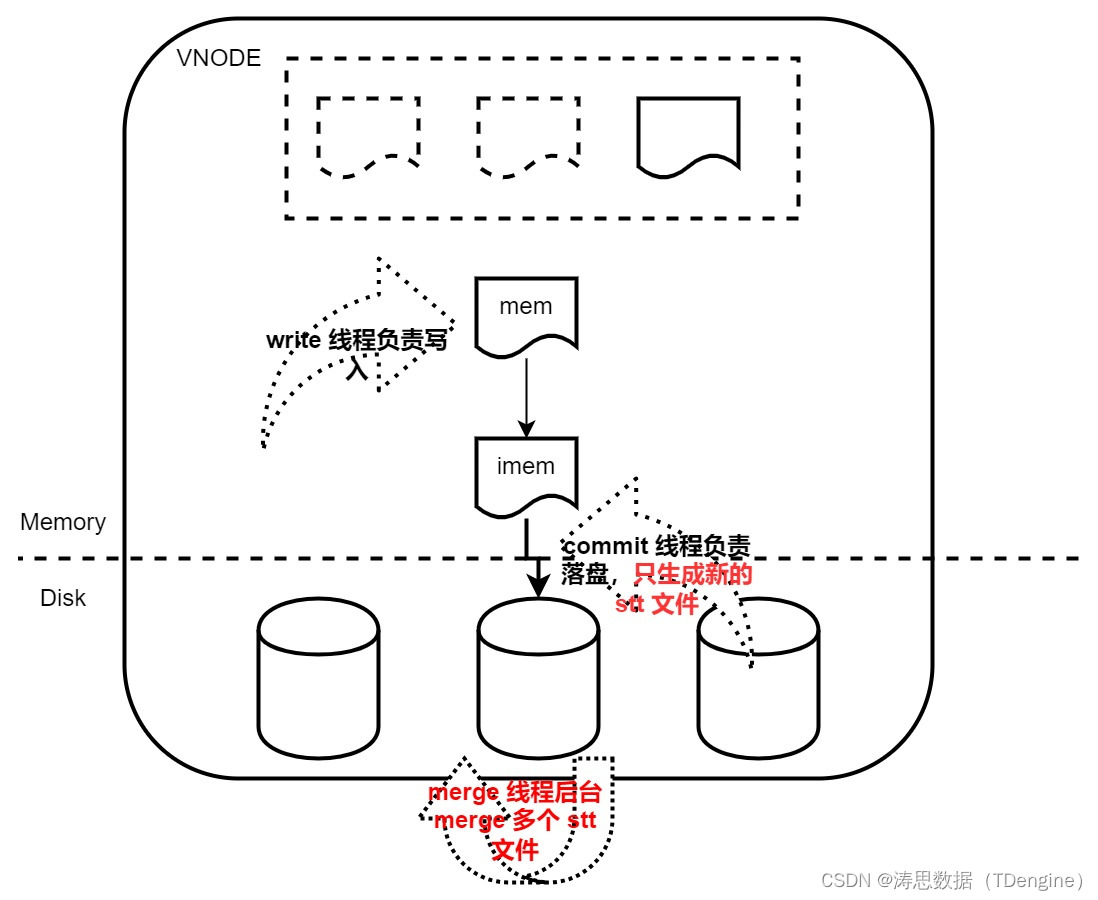
存储数据调整
LSM 实现完善
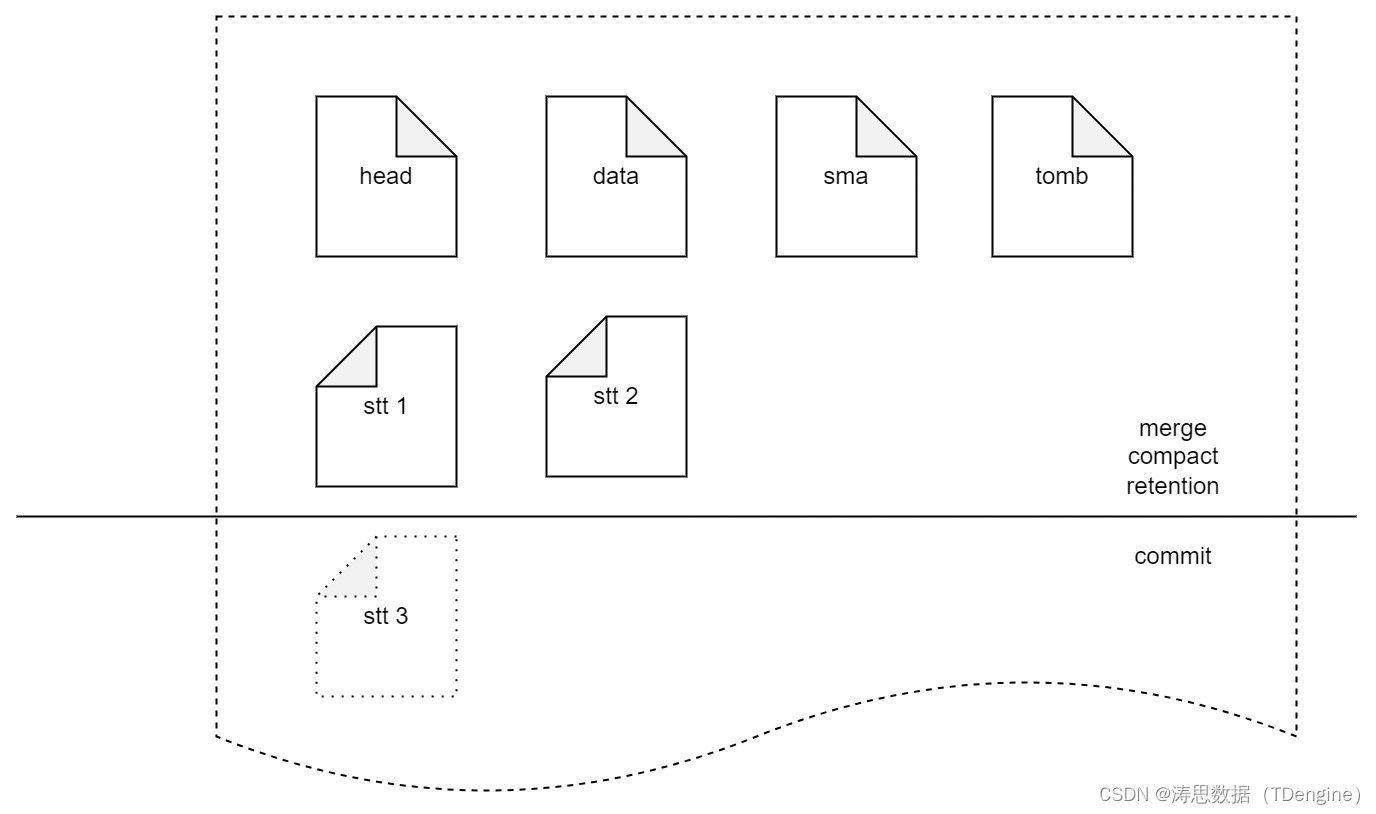
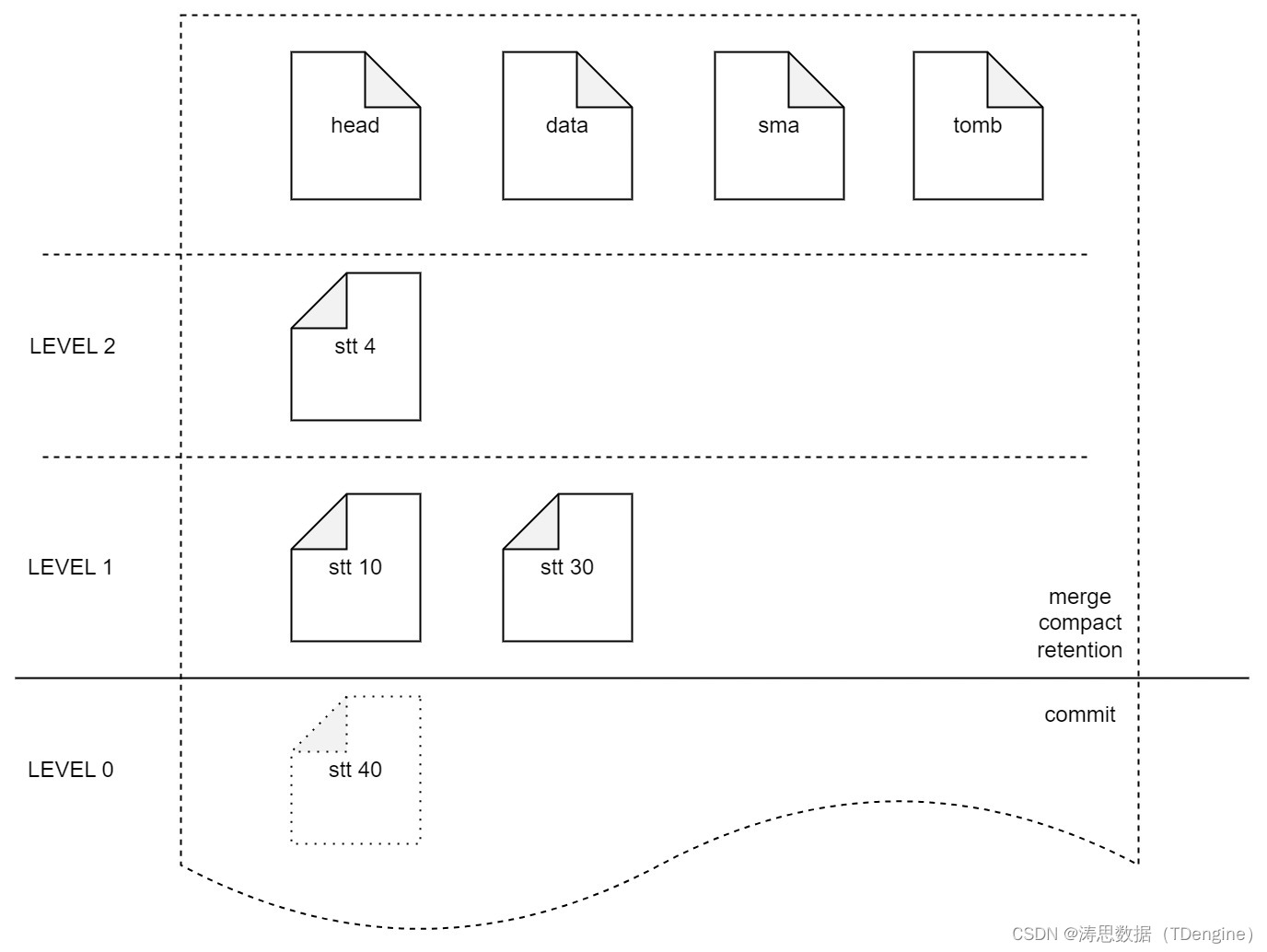
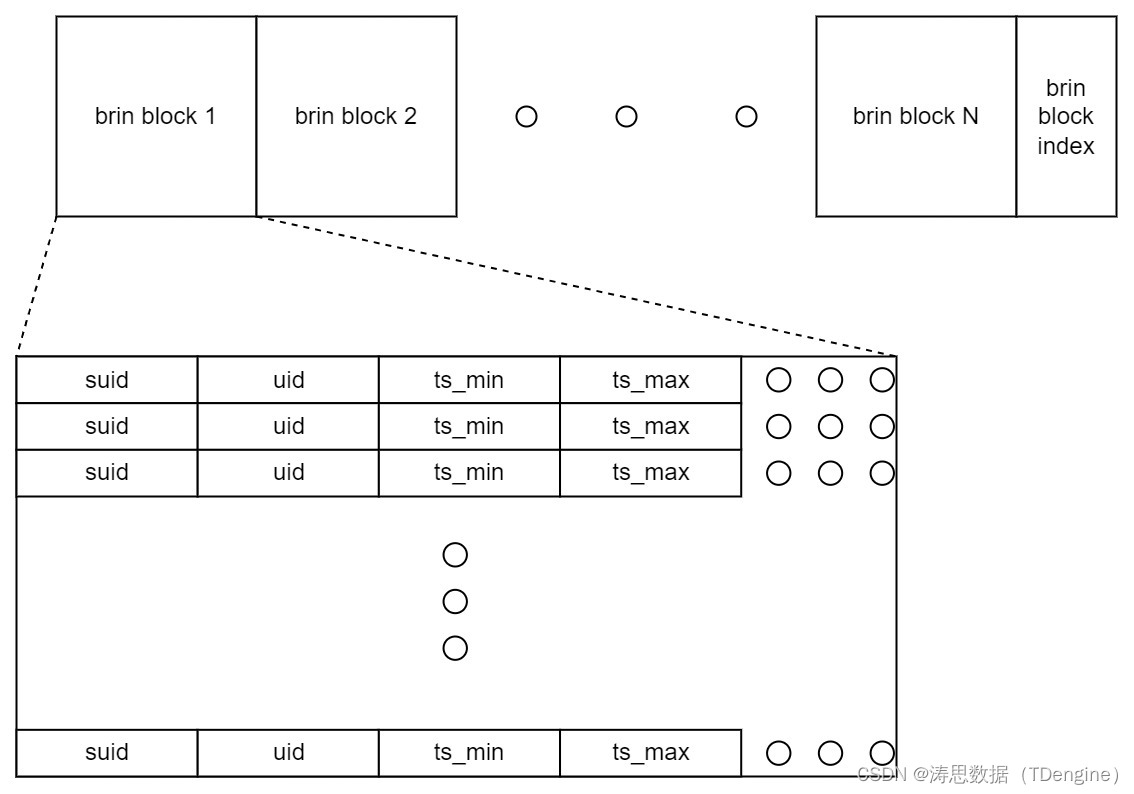
头文件列存
优化结果反馈
结语
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。