本文介绍: 如何在集群服务器的GPU上训练深度学习模型,如何配置环境,如何管理作业。
相关手册与软件准备
官方使用手册
用户手册:https://hpc.sustech.edu.cn/ref/cluster_User_Manual.pdf
培训视频:https://hpc.sustech.edu.cn/ref/meeting_20230810.mp4
启明2.0使用手册:https://hpc.sustech.edu.cn/ref/qiming_User_Manual_v3.0.pdf
Anaconda官方教程:https://hpc.sustech.edu.cn/ref/anaconda-install-by-user.html
安装前置软件
按照步骤登录节点,注意:在站点管理器中,传输协议要选择SFTP!!!不然会连接失败。
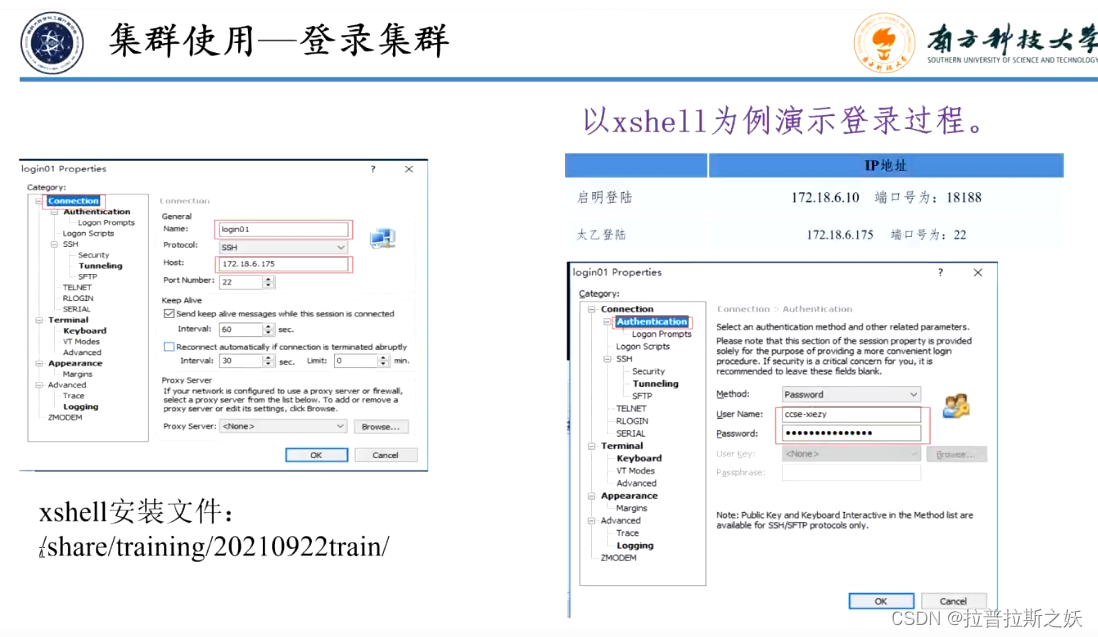
深度学习模型单节点训练
以yolov5最基本模型训练为例
1. 配置Anaconda
Anaconda官方教程:https://hpc.sustech.edu.cn/ref/anaconda-install-by-user.html
因为anaconda相关文件会存储在自己的工作文件夹里,所以和环境相关的步骤可以直接在登录节点执行。
下载Anaconda(只需完成一次)
为每一个任务创建一个conda环境
配置cuda+torch
2. pbs文件编写
3.作业提交与监控
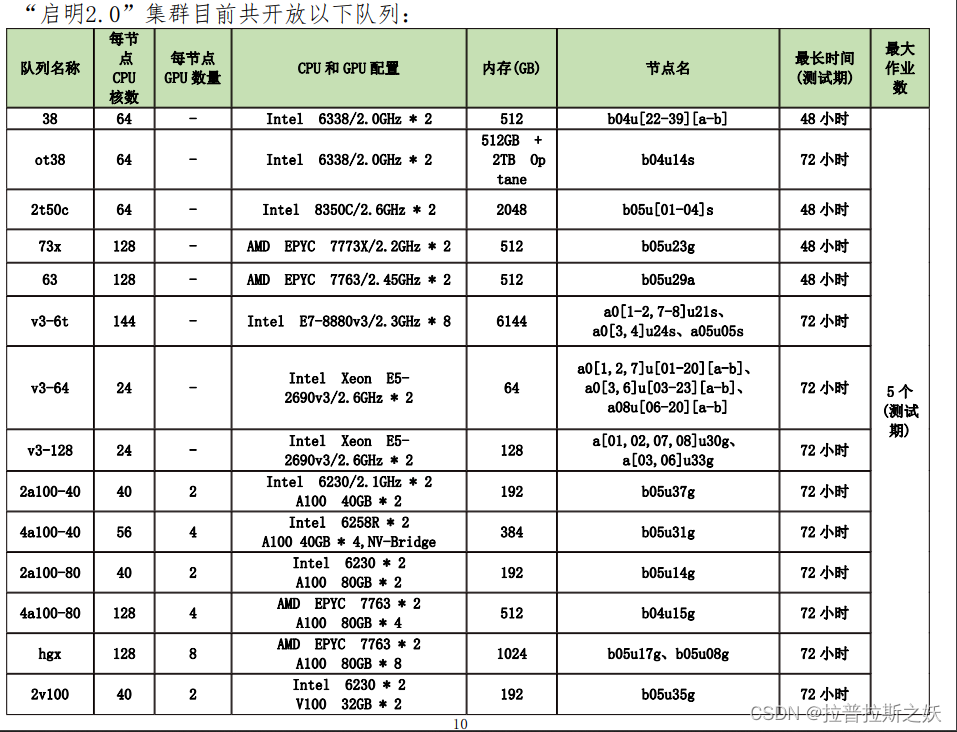
队列选择
Multi-GPU Training
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)
