本文介绍: WAF可以通过对Web应用程序的流量进行过滤和监控,识别并阻止潜在的安全威胁。WAF可以检测Web应用程序中的各种攻击,例如SQL注入、跨站点脚本攻击(XSS)、跨站请求伪造(CSRF)等,并采取相应的措施,例如拦截请求、阻止访问、记录事件等。常见的waf拦截页面的汇总,可以根据waf的拦截页面进行判断waf的种类参考下面链接里面的总结微信公众平台 (qq.com)
什么是WAF
WAF可以通过对Web应用程序的流量进行过滤和监控,识别并阻止潜在的安全威胁。WAF可以检测Web应用程序中的各种攻击,例如SQL注入、跨站点脚本攻击(XSS)、跨站请求伪造(CSRF)等,并采取相应的措施,例如拦截请求、阻止访问、记录事件等。
常见的waf拦截页面的汇总,可以根据waf的拦截页面进行判断waf的种类
参考下面链接里面的总结
微信公众平台 (qq.com)![]() https://mp.weixin.qq.com/s/3uUZKryCufQ_HcuMc8ZgQQ
https://mp.weixin.qq.com/s/3uUZKryCufQ_HcuMc8ZgQQ

触发waf的条件–不正常的流量特征
解决方案一:使用被动扫描
平台推荐
1.奇安信的鹰图平台

2.360测绘空间

3.fofa平台网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 – FOFA网络空间测绘系统 https://fofa.info/
https://fofa.info/

解决方式二:使用搜索引擎的爬虫头

解决方式三:代码伪造
解决方案四:代理延迟

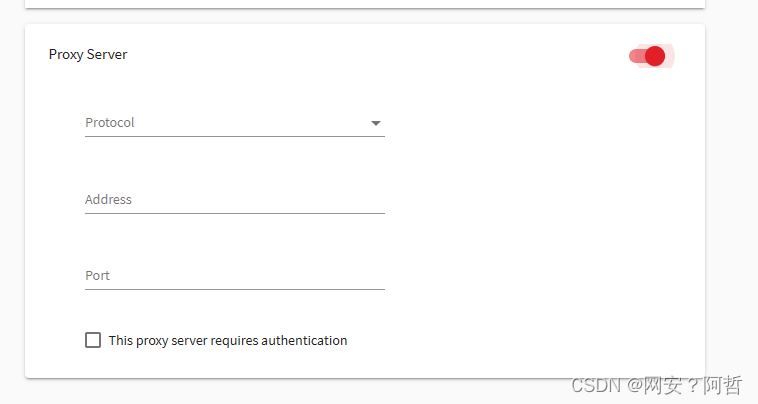
解决方案五:使用代理

写在最后
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




