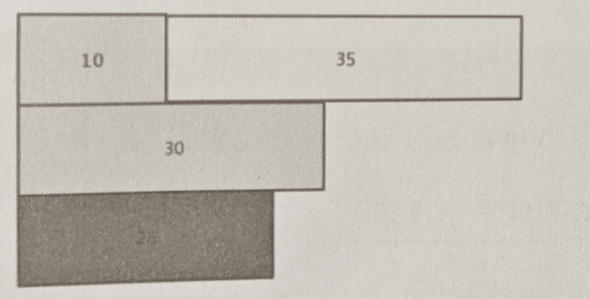
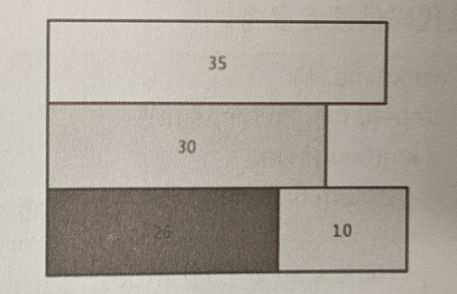
本文介绍: 对如上的两个例子进行最短时间求解,考虑使用贪心算法得出一个较好的近似最优解。如果说将用时最短的任务优先分配给机器,可能会出现其他任务均已经完成,最终就剩下的是用时最长的任务,也就剩下它还处在正在运行中的情况,以第一个例子为例,如果将耗时为10,26,30这三个任务优先分配给3台机器,此时的最终总耗时为45,这样就可以看出当3个作业都已经完成的时候,耗时最长的作业35却仍在运行,这样就导致了时间的加长和浪费,所以就需要考虑对贪心算法的策略进行调整,就需要优先考虑将耗时最长的作业进行分配。
对于作业调度问题,其实至今都还不能找到一个最优的解决方案,对与如何将任务和机器进行一个合理安排和分配,让其能够在最短时间内将所有任务全部完成,和计算机操作系统的任务调度过程相类似。
这里主要是给定n个作业和m台相同的机器,使用这些机器来对给定的作业进行处理,则作业k所需要的处理时间是time[k],任一作业可以在任意的一台机器上进行处理,但是在未完成正在完成的作业之前不允许中断当前作业操作,同时任何作业都不可以进行拆分,这里需要给出一种作业调度的方案,使得对这n个作业进行操作,在尽可能短的时间内由这m台机器加工处理完成。
如下例子:

添加图片注释,不超过 140 字(可选)

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。