本文介绍: 这一年下来,写两次工作流流转,总结下经验。第一次写的时候,只找到用模版设计模式包裹一下,每个方法都做隔离,但是在具体分支实现的时候,if/else 满屏分,而且因为要针对不同情况,重复代码很多,但是if/else的条件又不一样,搞得我没办法用设计模式修改,想过用工厂模式重构。一是没时间,二是工厂模式和策略模式基本上都用不来,首先,工厂模式一定是if else分支较多,并且入参明确、固定。策略模式也是不同的方法,实现不同的业务,入参明确、固定。
需求
这一年下来,写两次工作流流转,总结下经验。
第一次写的时候,只找到用模版设计模式包裹一下,每个方法都做隔离,但是在具体分支实现的时候,if/else 满屏分,而且因为要针对不同情况,重复代码很多,但是if/else的条件又不一样,搞得我没办法用设计模式修改,想过用工厂模式重构。
一是没时间,二是工厂模式和策略模式基本上都用不来,
首先,工厂模式一定是if else分支较多,并且入参明确、固定。
策略模式也是不同的方法,实现不同的业务,入参明确、固定。
它们两者都不适合参数多一个少一个的情况,用起来只能说恶心自己。
并且由于设计模式的方法过多,时常debug需要嵌套跳转好几轮代码,就比较恶心。
这一年,闲下来我都会重构部分重复的代码,比如if else过多用设计模式优化,优化下来的感受是,没感觉可读性有多提高,反而感觉代码可读性变差了,有些案例的设计模式,很多情况没考虑到,比如较多重复代码,直接复用interface default里的方法,给我直观的体验是其他人来看这个代码,不太好理解。
还不如if else来的直接。
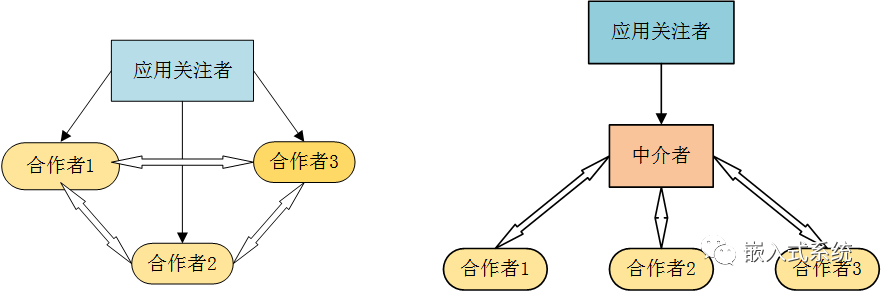
设计模式做不到事
举个例子,当有个非常恶心的业务,需要在两层for循环里写if else,continue关键字是你贴心侍卫,常伴汝身。
你必须用continue它,艹,这个东西用设计模式就不合理,只能复用一些代码,放到一个方法里面去,什么两层for循环里,写个四五百行if else,调试都要好几天,我不知道要是业务出现变动,这个代码后面还怎么改。
新奇的思路
原案例
填坑
追加内容 回退节点
关于优化
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)