本文介绍: 索引(index)是帮助MysQL高效获取数据的数据结构有序在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
1.索引概述
优缺点:

2.索引结构

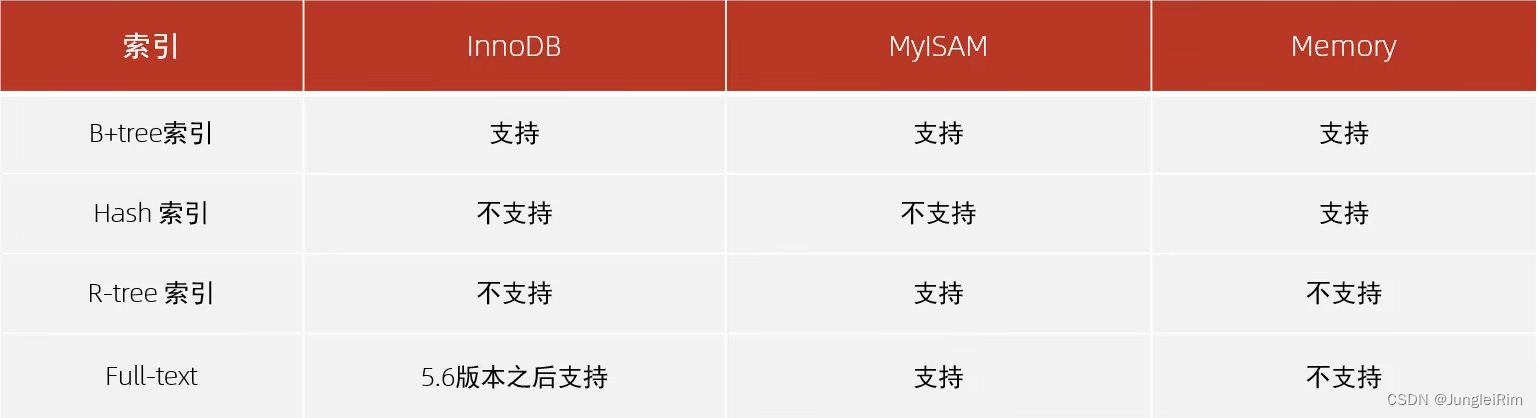
在不同存储引擎下的支持情况:
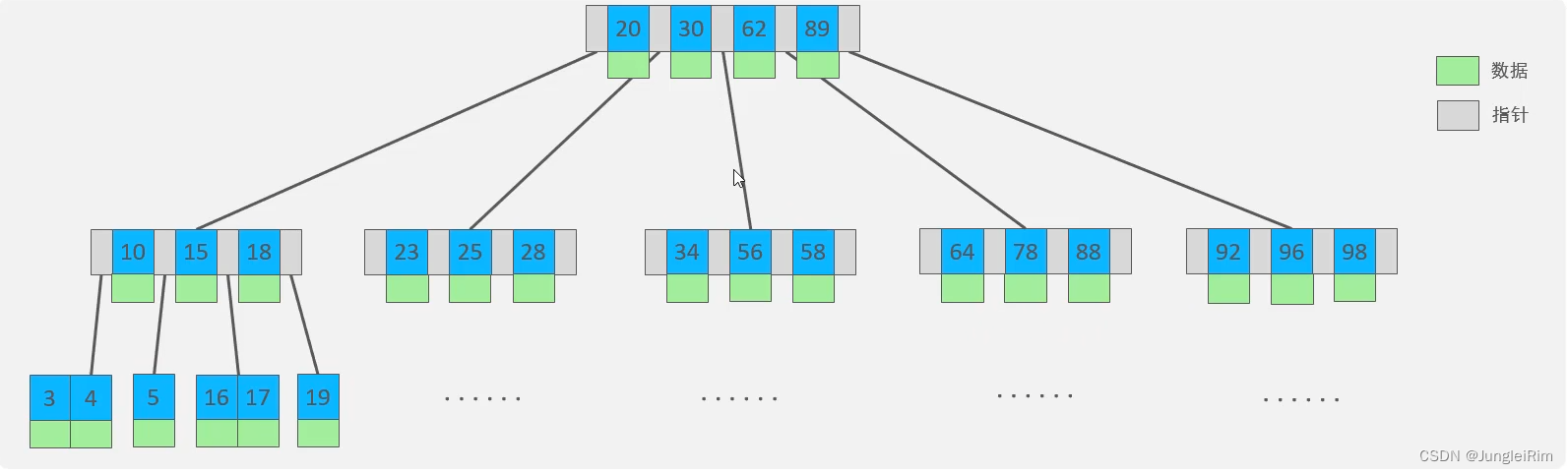
1.B树(多路平衡查找树)
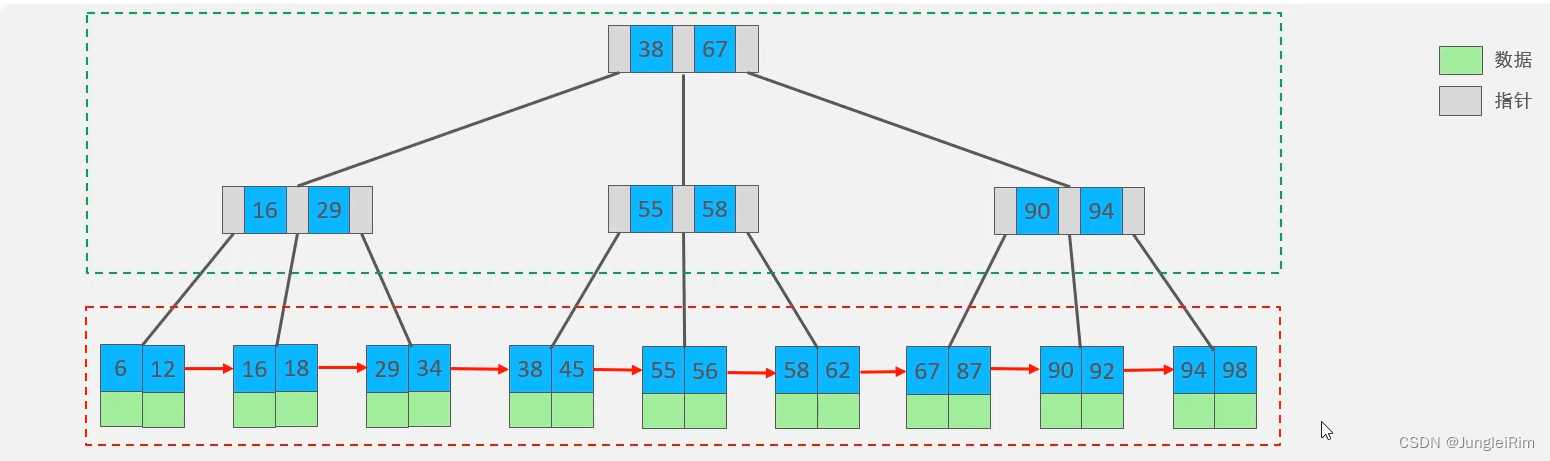
2.B+树
3.Hash
1.特点
2.存储引擎支持
4.选择B+树作为InnoDB存储引擎索引结构的原因
3.索引分类


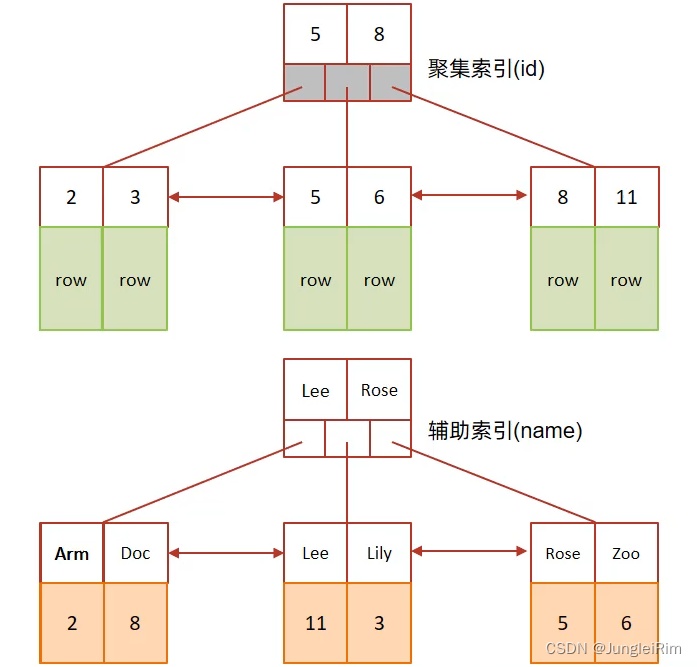
1.聚集索引选取规则
2.回表查询
4.索引语法
1.创建索引
2.查看索引
3.删除索引
5.SQL性能分析
1.SQL执行频率
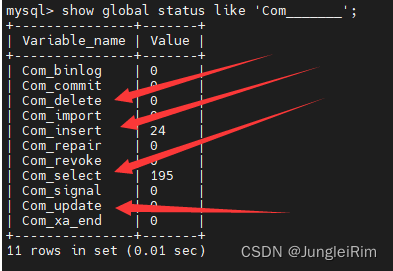
2.慢查询日志

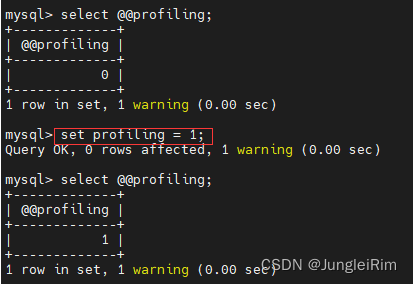
3.profile详情


4.explain执行计划


6.索引使用
1.最左前缀法则
2.范围查询
3.索引列运算
4.字符串不加引号
5.模糊查询
6.or连接的条件
7.数据分布影响
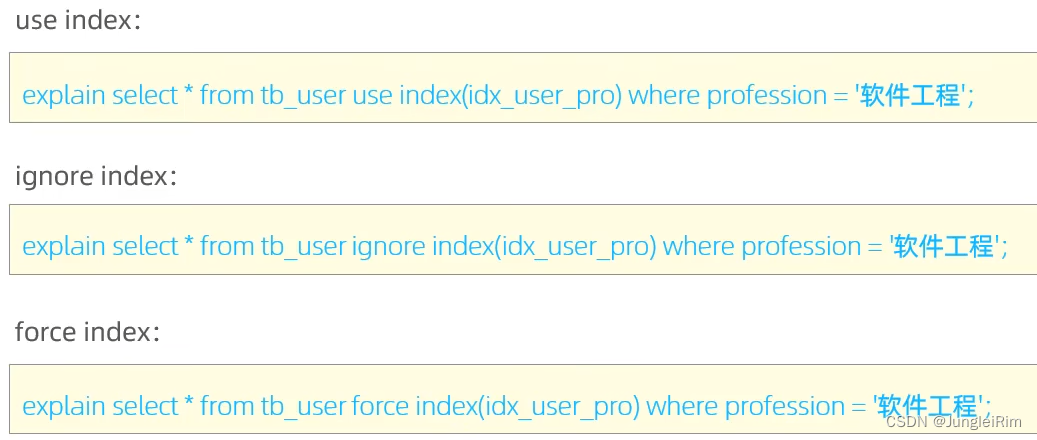
8.SQL提示
9.覆盖索引
10.前缀索引
1.创建语法
2.前缀长度
11.单列索引与联合索引
7.索引设计原则
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。