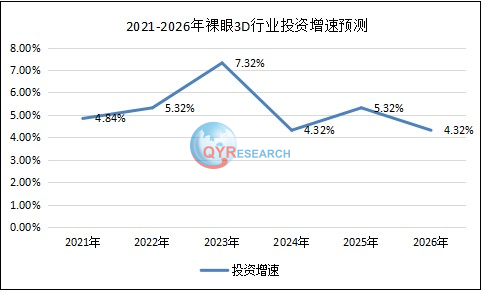
本文介绍: 很多工作在扩散先验中注入跨视图一致性,但仍然缺乏细粒度的视图一致性。论文提出的文本到3d的方法有效地减轻了漂浮物(由于密度过大)和完全空白空间(由于密度不足)的产生。
简介
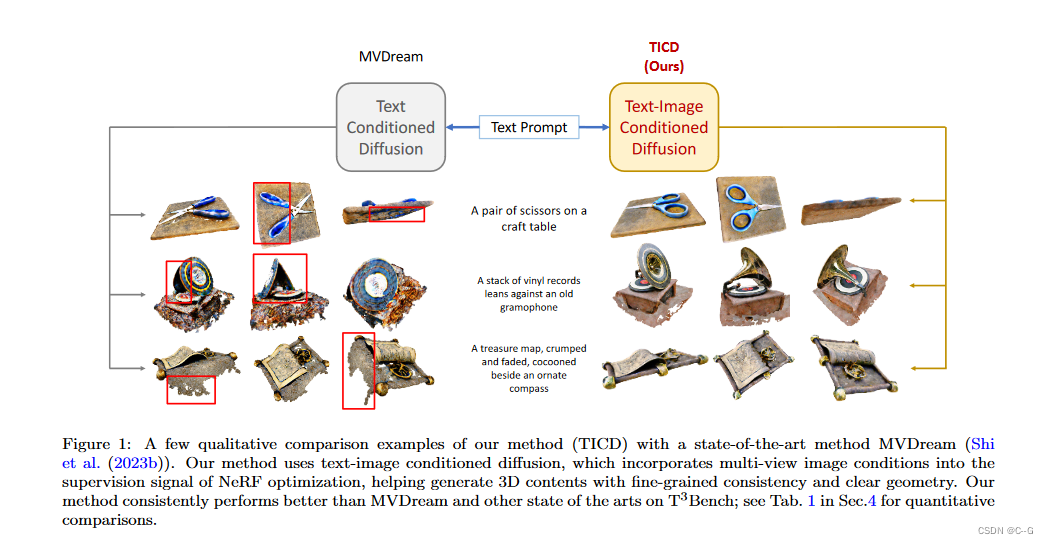
很多工作在扩散先验中注入跨视图一致性,但仍然缺乏细粒度的视图一致性。论文提出的文本到3d的方法有效地减轻了漂浮物(由于密度过大)和完全空白空间(由于密度不足)的产生。
实现过程
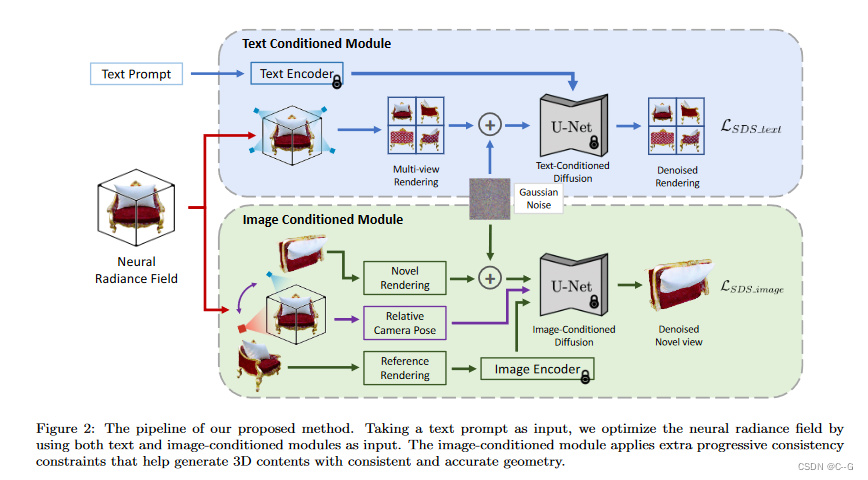
简单而言,论文工作是 Dreamfusion+Zero123。
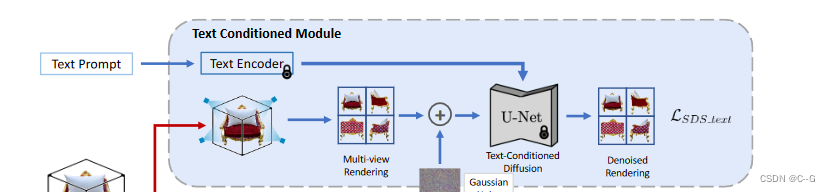
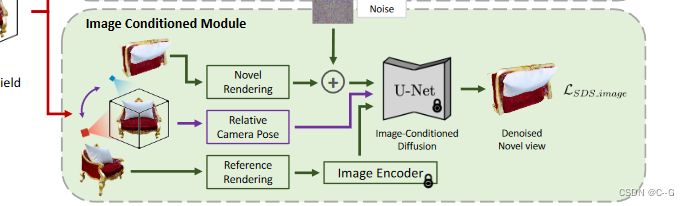
使用两种不同的分数蒸馏进行监督:文本条件下的多视图扩散模型(维护文本的多视图一致性)和图像条件下的新视图扩散模型(维护视图之间的一致性)。
对于3D表示,实现了threeststudio的隐式体积方法,该方法由多分辨率哈希网格和用于预测体素密度和RGB值的MLP网络组成
文本条件下的多视图扩散模型
图像条件下的新视图扩散模型
score distillation
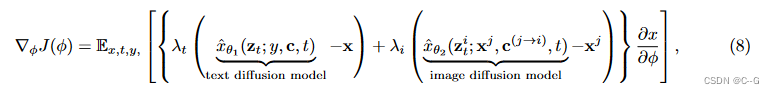
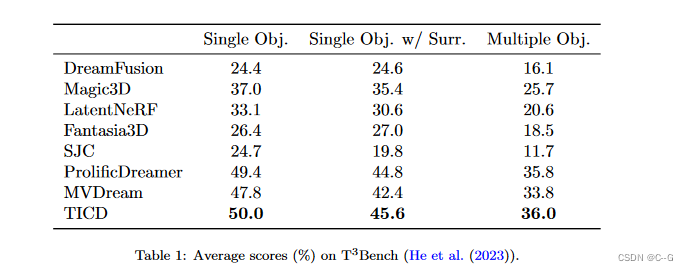
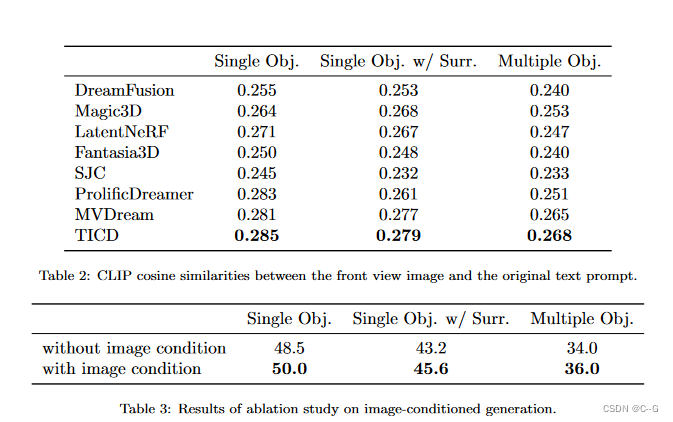
实验

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。