本文介绍: 因为网页中,只能显示出歌单的前20首歌曲,所以仅支持下载前20首歌曲(非VIP音乐)爬取网易云音乐实战,仅供学习,不可商用,出现问题,概不负责!联系邮箱:mango_1698@163.com。分为爬取网易云歌单和排行榜单两部分。下载部分与下载歌单歌曲相同。
爬取网易云音乐实战,仅供学习,不可商用,出现问题,概不负责!
分为爬取网易云歌单和排行榜单两部分。
因为网页中,只能显示出歌单的前20首歌曲,所以仅支持下载前20首歌曲(非VIP音乐)
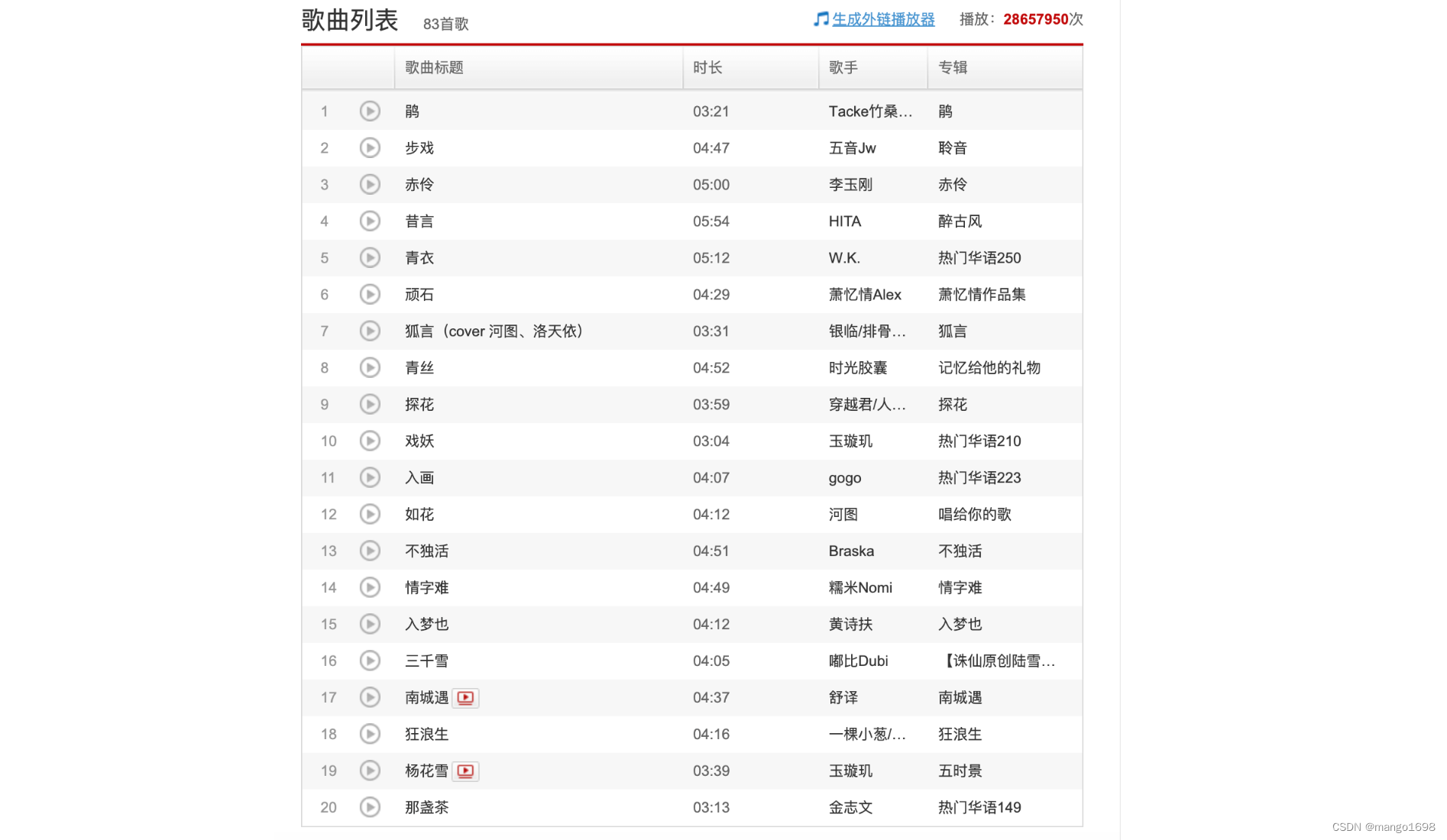
具体过程:
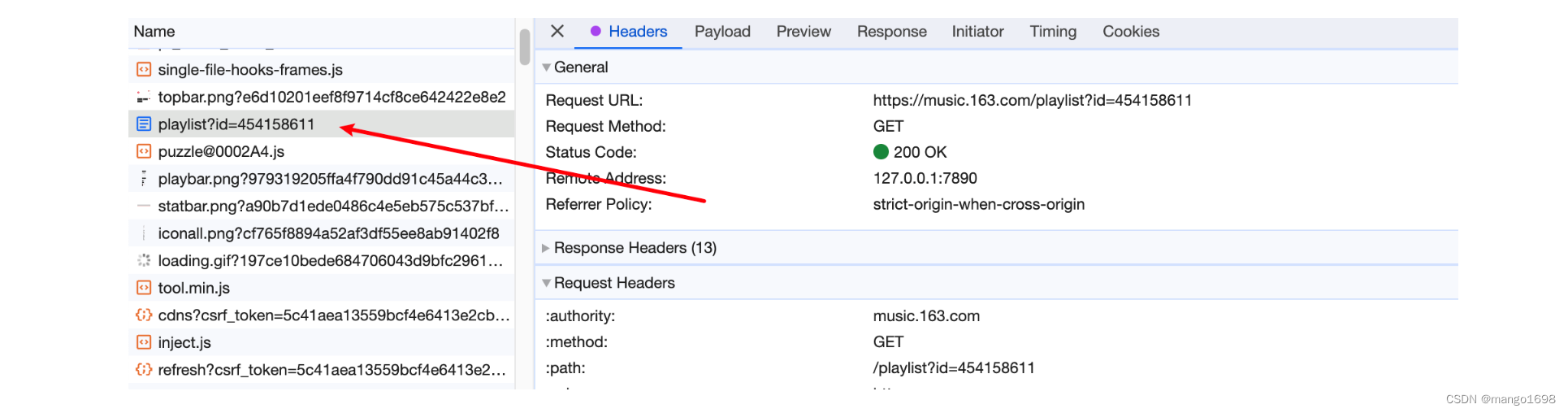
1.通过抓包,获取到请求头


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。