Self-Driving Database Management Systems
ABSTRACT
之前的advisory tools来帮助DBA处理系统调优和物理设计的各个方面,都仍然需要人类对数据库的任何更改做出最终决定,并且是在问题发生后修复问题的反动措施reactionary measures 。
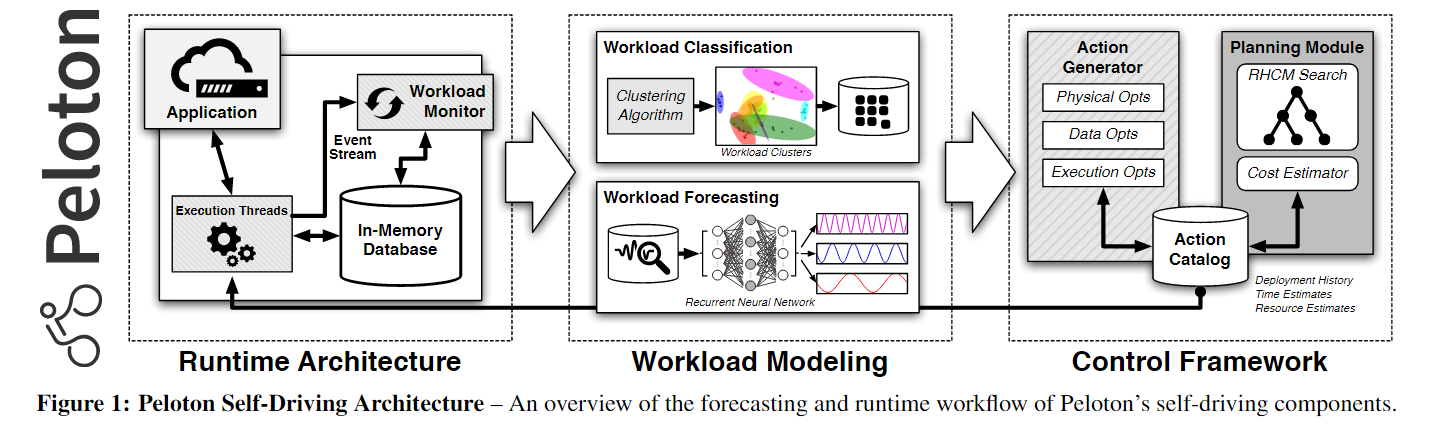
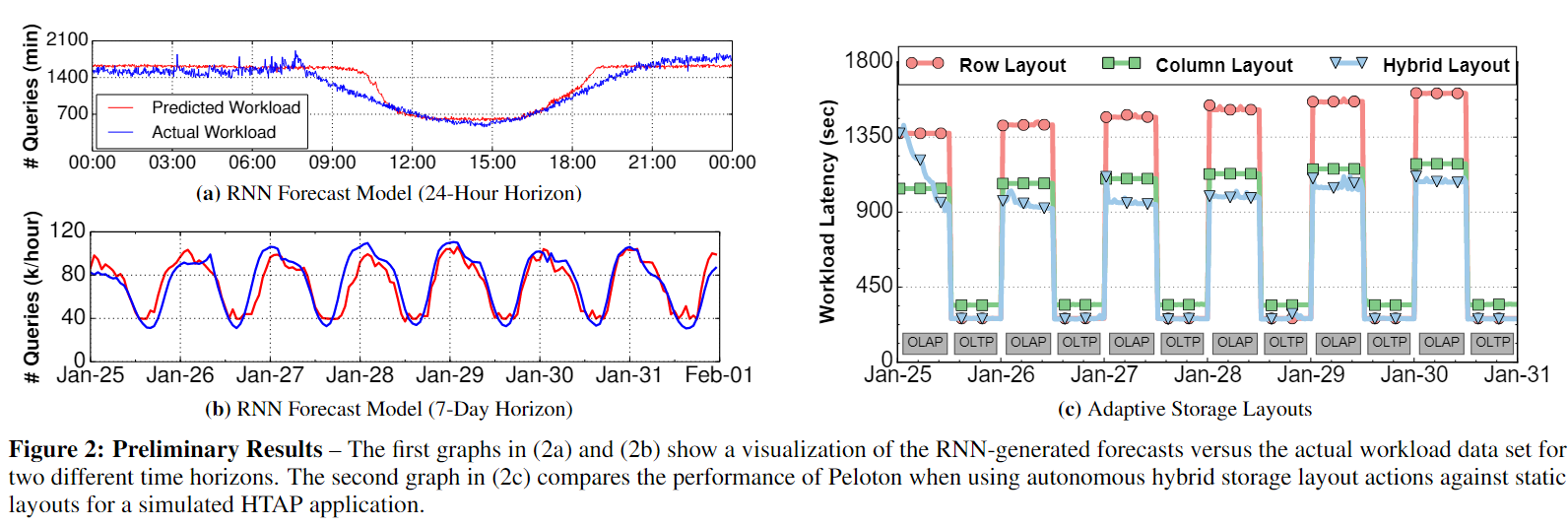
An truly “self-driving” database management system (DBMS)是针对autonomous operation(自主操作)设计的全新架构。系统的所有方面都是由一个integrated planning componen综合规划组件来控制。该组件不仅针对当前的工作负载优化系统,而且还预测未来的工作负载趋势,以便系统可以相应地做好准备。这样,DBMS就可以支持所有以前的调优技术,而不需要人工确定部署它们的正确方式和适当时间。
本文介绍了第一个自驱动DBMS Peloton的体系结构。由于深度学习算法的进步,以及硬件和自适应数据库架构的改进,Peloton的自主能力现在成为可能。
1. INTRODUCTION
其实SQL也是这种思路,关系模型和声明性查询语言就是使用DBMS来消除数据管理负担的想法。使用现有的自动调优工具是一项繁重的任务,因为它们需要费力地准备工作负载样本、分出一些硬件来测试提议的更新,最重要的是要放到DBMS的内部构件。如果DBMS可以自动做这些事情,那么它将消除掉调优过程中部署数据库所涉及的许多代价和成本。
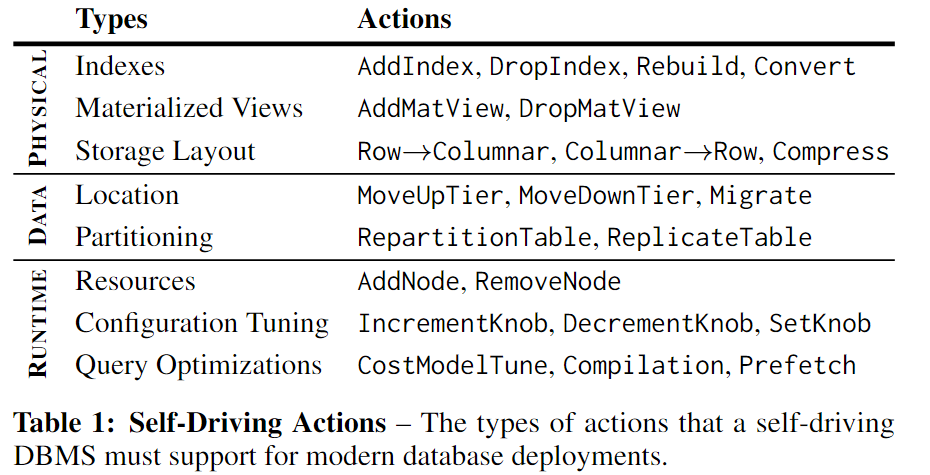
以前的许多self-tuning系统工作都集中在仅针对数据库的单个方面的工具上,例如,一些工具能够选择数据库的最佳逻辑或物理设计,主要是索引、分区方案、数据组织、物化视图。其他工具能够为应用程序选择调优参数。这些工具中的大多数都以相同的方式操作:DBA提供样本数据库和工作负载Track,以指导搜索找到最佳或接近最优的配置。基于云的系统在service-level使用动态资源分配,但不调整单个数据库。
这些都不足以实现完全自主的系统,因为(1) external to the DBMS, (2) reactionary,(3) 无法一次考虑多个问题的整体视图。即:他们从系统外部观察 DBMS 的行为,并建议 DBA 如何进行修复已经发生的问题。Tunning tool是假设DBA能够在一个影响数据库性能的最小窗口来更新DBMS。但是现在DBMS非常复杂,所以如果有工具是自动化的,这样它们就可以单独部署优化。