论文链接:https://arxiv.org/abs/2203.02688
代码;https://github.com/lartpang/zoomnet
1.摘要
最近提出的遮挡对象检测(COD)试图分割视觉上与其周围环境融合的对象,这在现实场景中是非常复杂和困难的。除了与它们的背景具有高度的内在相似性之外,这些对象通常在尺度上是多样的,外观上是模糊的,甚至严重遮挡。为了解决这些问题,我们提出了一种混合尺度三元网络,ZoomNet,模仿人类观察模糊图像时的行为,即放大和缩小。具体来说,我们的ZoomNet采用缩放策略,通过设计的尺度集成单元和分层混合尺度单元来学习区分性混合尺度语义,充分挖掘候选对象和背景环境之间的不可感知线索。此外,考虑到不可区分的纹理所带来的不确定性和模糊性,我们构造了一个简单而有效的正则化约束,即不确定性感知损失,以促进模型在候选区域中准确地产生具有更高置信度的预测。我们提出的高度任务友好的模型在四个公共数据集上始终超过现有的23种最先进的方法。此外,在SOD任务上优于最近的尖端模型的上级性能也验证了我们模型的有效性和通用性。
2.主要贡献
1.在COD任务中,我们提出了一种混合尺度的三元组网络ZoomNet,它通过描述和统一不同“缩放”尺度下的特定尺度的外观特征以及有针对性的优化策略,可以有效地捕获复杂场景中的对象。
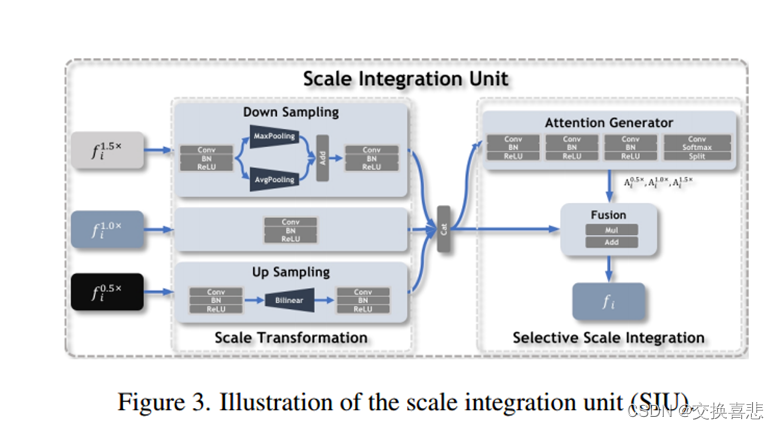
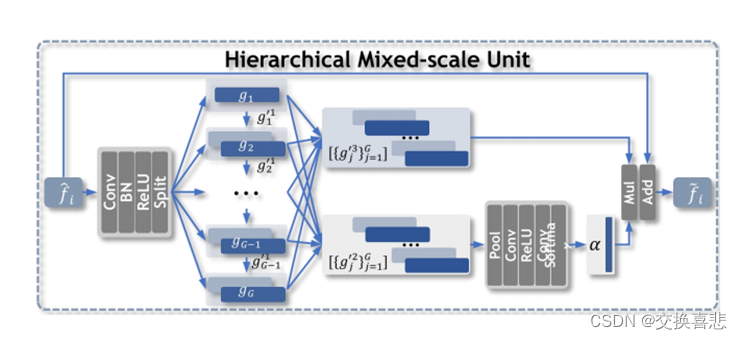
2.为了获得被捕获对象的区分性特征表示,我们设计了SIU和HMU进行提取,聚合和加强特定于尺度和微妙的语义表示,以获得准确的COD。
3.我们提出了一种简单而有效的优化增强策略,UAL,该模型在不增加额外参数量的情况下,可以有效地抑制背景的不确定性和干扰
在4个COD数据集上对7种度量标准下的方法进行了比较,并在SOD任务中表现出了很好的泛化能力,与现有的SOD方法相比具有上级性能。
3.模型结构图
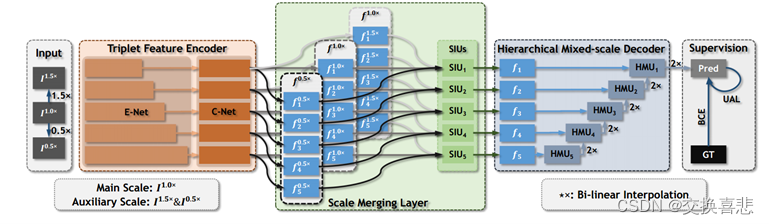
4.模型组成
HMU迭代式构造,iteration struction in the HMU
共享三元组特征编码器用于提取对应不同输入“缩放”尺度的多级特征,由分别用于特征提取和压缩的E-Net和C-Net组成,在尺度合并层采用SIU对不同尺度的关键线索进行筛选和融合,然后通过自顶向下的方式逐步融合特征。
求助于图像金字塔,具体来说基于单尺度输入定制了一个图像金字塔来识别被遮挡的物体,将尺度分为单尺度和两个辅助尺度,
4.1 三重特征编码器
由特征提取和通道压缩网络组成,E-net和C-net,E-net由常用的Resnet50组成,删除了layer4之后的结构,C-net进行级联,进一步优化计算,找到更紧凑的特征。
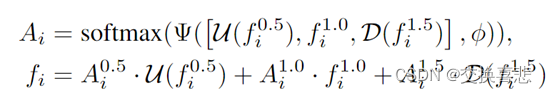
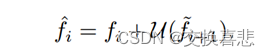
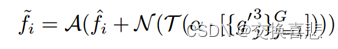
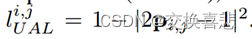
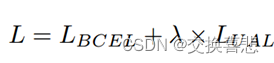





![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)