本文介绍: 随着接触的分布式系统(产品)越来越多,关于分布式系统的数据存储逐渐有了一些理解,进行统一整理和梳理。
随着接触的分布式系统(产品)越来越多,关于分布式系统的数据存储逐渐有了一些理解,进行统一整理和梳理。
1. 数据存储场景和存储策略
在进行分布式系统设计时,面临的数据场景不同,因此对应的产品在进行架构设计时也采用了不同的存储策略。但是总的说来,主要包括如下两类。
1.1 镜像模式-小规模数据
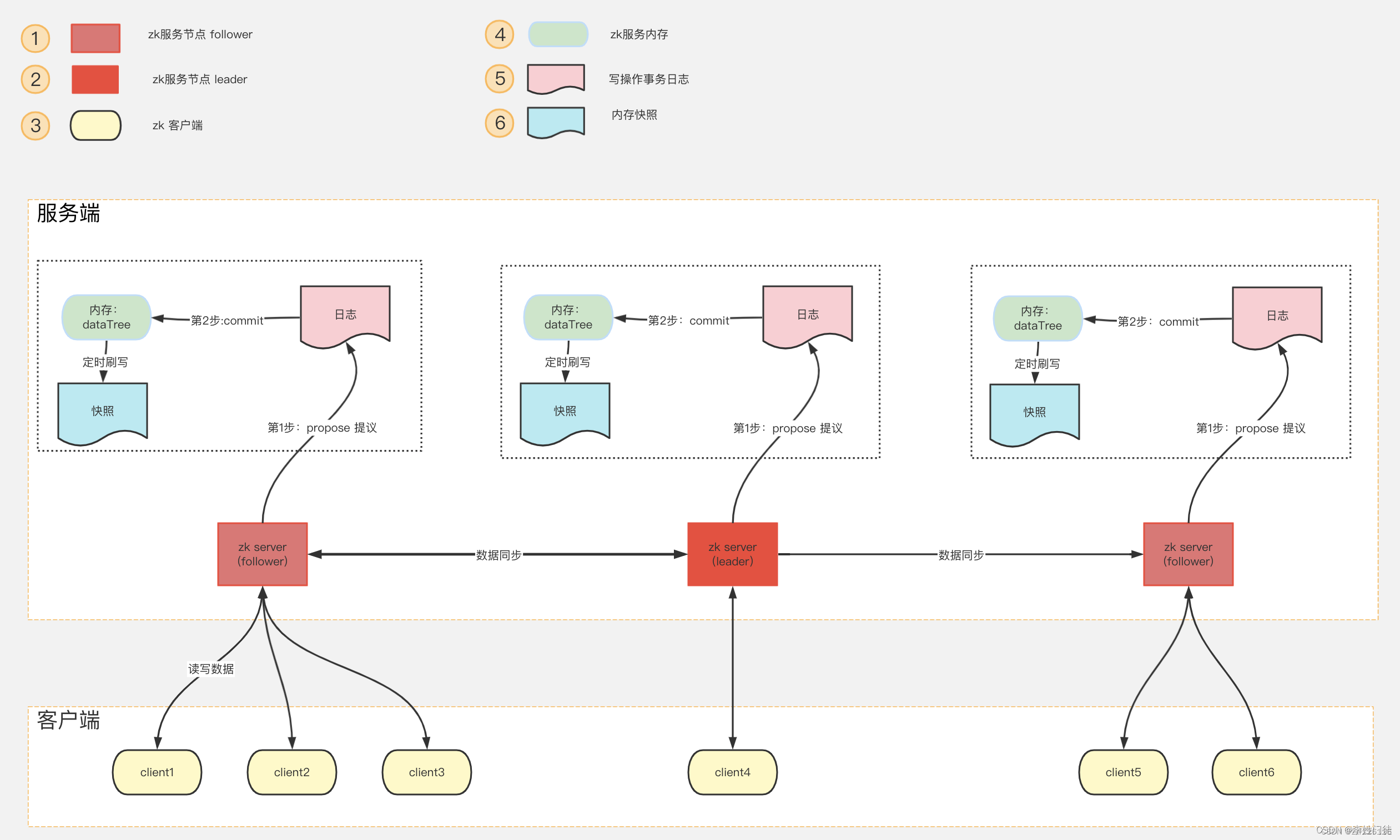
小规模数据场景主要包括: 元数据、少量业务数据等。这种数据类型的特点是,存储的数据量一般都比较小(比如10G以内)。通常情况下,单个节点能够满足数据的存储、读写性能要求,因此该类型的分布式产品在设计时通常使用镜像模式进行存储。单节点保存所有数据(业务数据+元数据),通过多节点(主从模式,强同步或者半强同步)形成多副本,从而保证数据的一致性。主从模式能够避免数据不一致的问题,不同节点通过复杂的选主逻辑选择最合适的节点作为leader,leader节点响应客户端的写请求,从节点响应客户端的读请求(不同产品有差异)。该类型常见的产品如zk、etcd等。
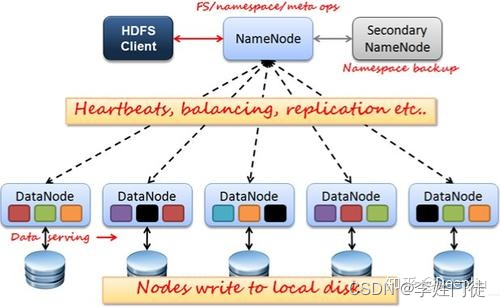
参考zk的架构图如下
1.2 分片模式-大规模数据
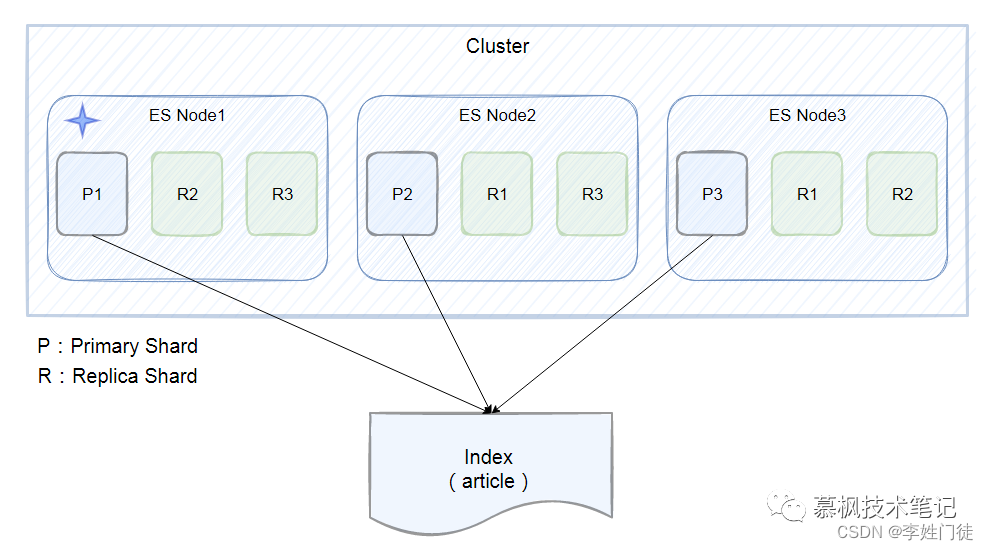
大规模数据场景主要包括:大数据、日志、图片、大量文档数据等,这种数据类型的特点是,存储的数据规模大(TB级别甚至更高)。通常情况下,单节点无法满足数据存储需求(单节点的磁盘、cpu内存等成为瓶颈),因此该类型的分布式产品在设计时通常使用分片模式进行存储。 将一个完整的业务数据(比如大索引)拆分成多个分片进行存储,不同分片分散在不同的节点上,从而规避单节点性能不足问题。这种类型的架构模式需要master角色,保存整个集群的元数据,从而形成上帝视角,用于进行数据分配、调度等职责。常见的产品如hdfs、hbase、es等
2. 数据一致性和高可用问题
2.1 镜像模式如何保证数据一致性
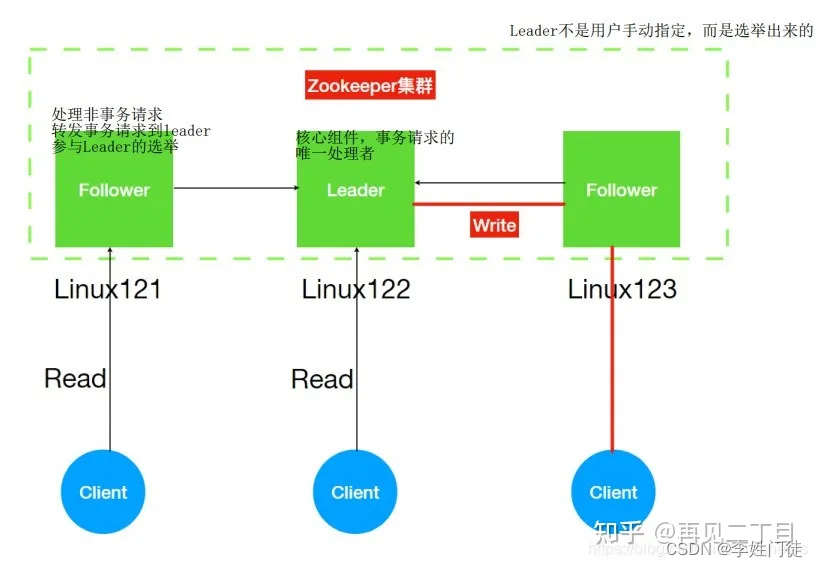
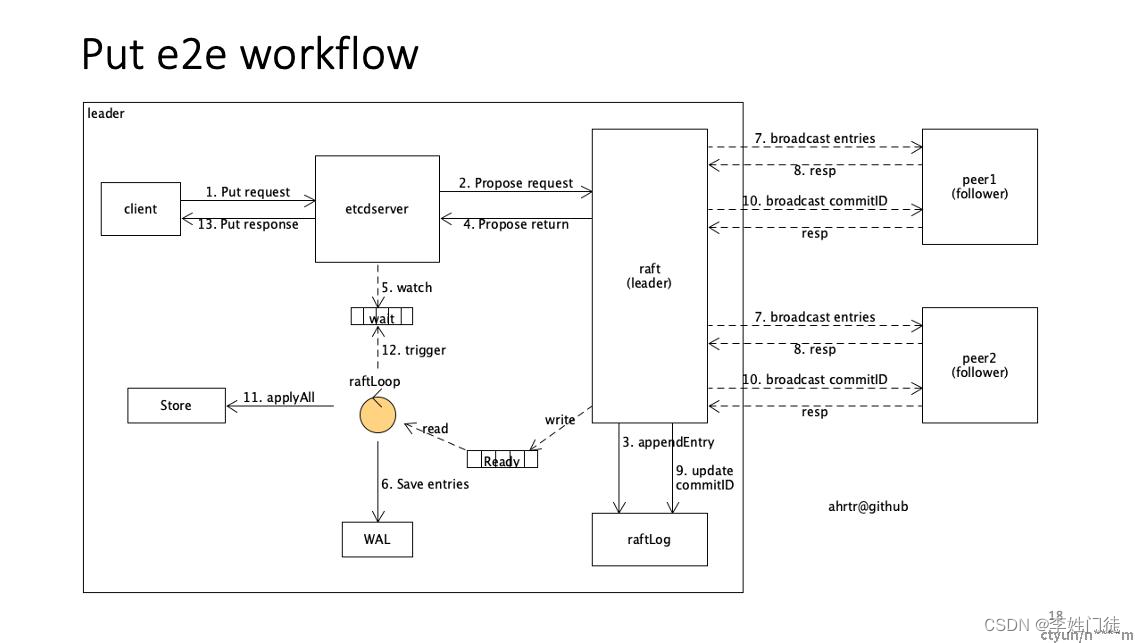
2.2 镜像模式如何保证数据高可用
2.2.1 HA模式
2.2.2 分布式选主模式
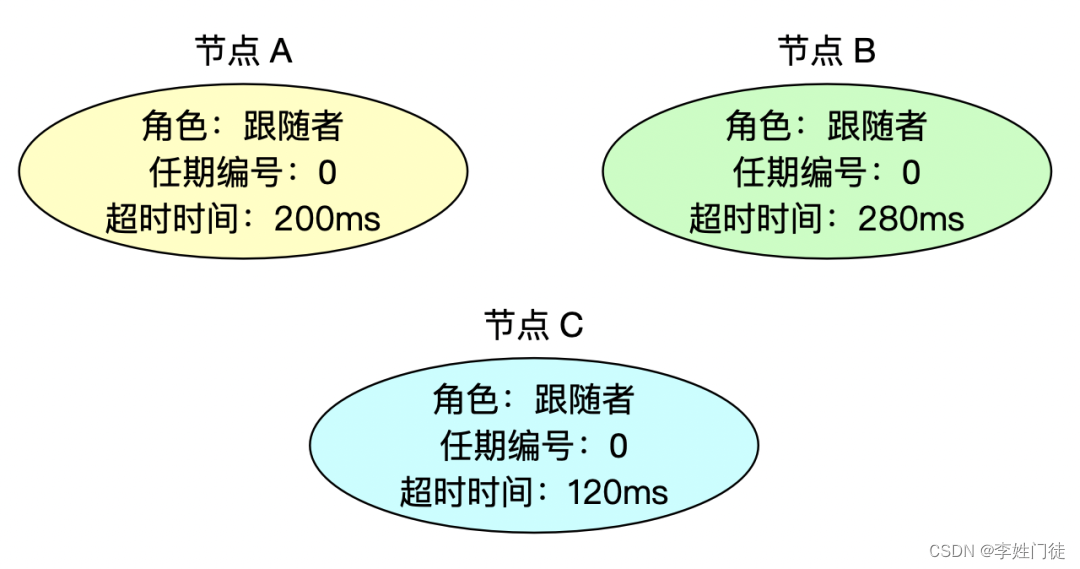
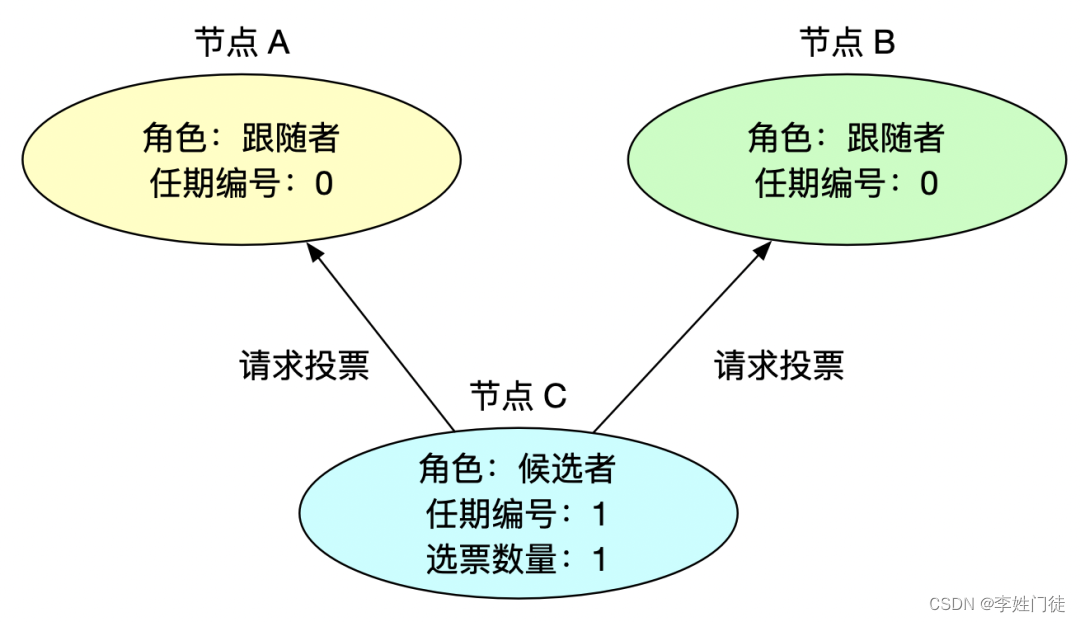
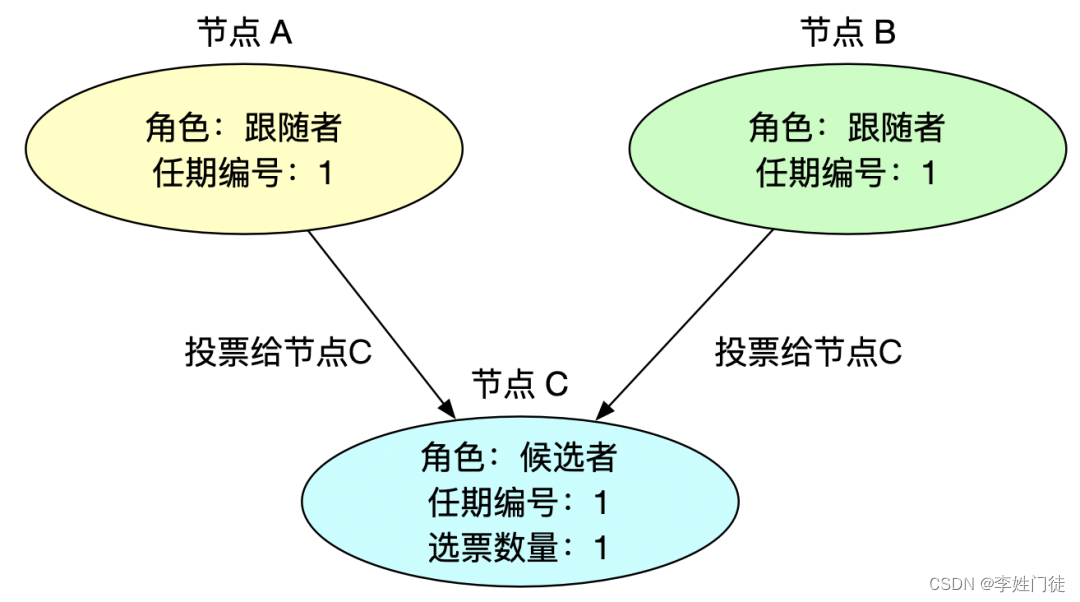
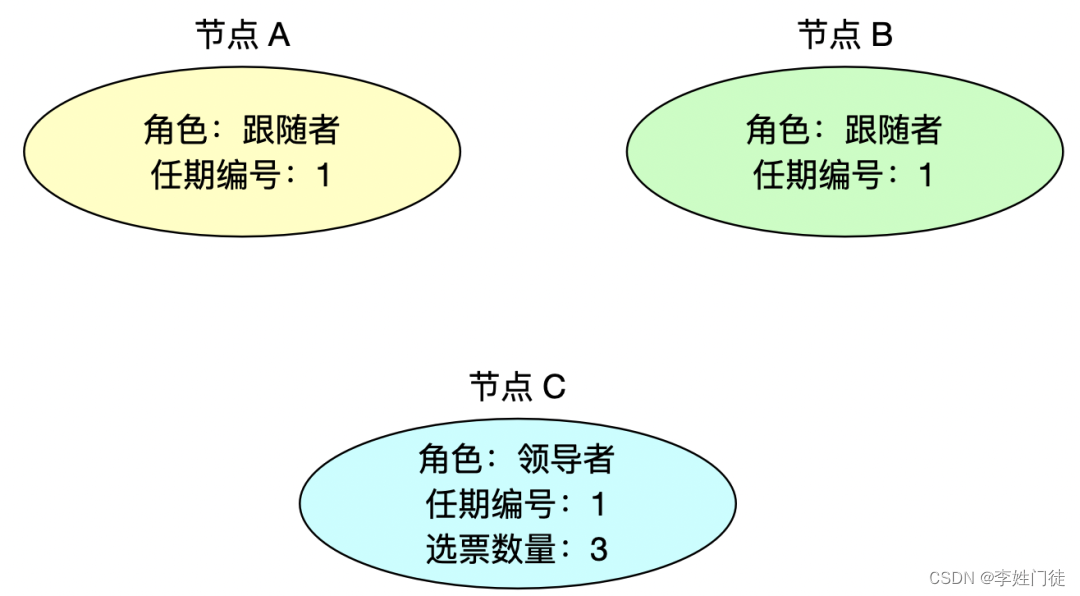
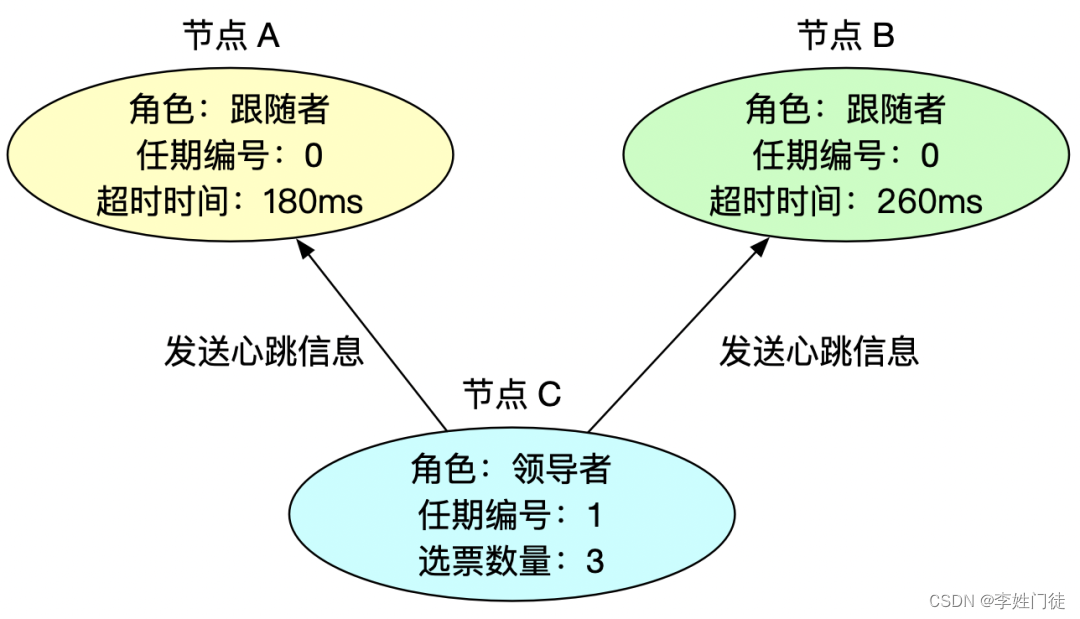
2.3 分片模式如何数据一致性和高可用
3. 大规模数据集群的架构设计模式
3.1 中心化模式
3.2 去中心化模式
4. 大规模数据集群故障转移模式
4.1 自动修复
4.2 人工修复
5. 故障转移也是有限度的
6. 系统稳定性的一些建议
6.1 梳理系统核心链路
6.2 鸡蛋不要放在一个篮子里
6.3 淘汰糟糕的iaas设备
6.4 更完善的监控和告警
7. 参考文档
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。