💡💡💡本文摘要:介绍了学生课堂行为检测,并使用YOLOv8进行训练模型,以及引入BRA注意力和最新的Shape IoU提升检测能力
1.SCB介绍

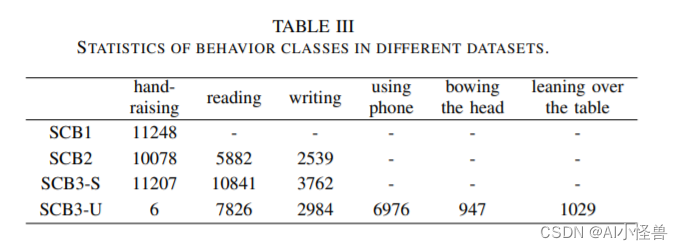
摘要:利用深度学习方法自动检测学生的课堂行为是分析学生课堂表现和提高教学效果的一种很有前途的方法。然而,缺乏关于学生行为的公开数据集给这一领域的研究人员带来了挑战。为了解决这个问题,我们提出了学生课堂行为数据集(SCB-dataset3),它代表了现实生活中的场景。我们的数据集包括5686张图像,45578个标签,重点关注六种行为:举手、阅读、写作、使用电话、低头和俯身在桌子上。我们使用YOLOv5、YOLOv7和YOLOv8算法对数据集进行评估,平均精度(map)高达80.3%。我们相信我们的数据集可以作为未来学生行为检测研究的坚实基础,并有助于该领域的进步。
在本研究中,我们对之前的工作进行了迭代优化,以进一步扩展scb数据集。最初,我们只关注学生举手的行为,但现在我们已经扩展到六种行为:举手,阅读,写作,使用电话,低头,靠在桌子上。通过这项工作,我们进一步解决了课堂教学场景中学生行为检测的研究空白。我们进行了广泛的数据统计和基准测试,以确保数据集的质量,提供可靠的训练数据。
我们的主要贡献如下:
1. 我们已经将scb数据集更新到第三个版本(SCB-Dataset3),增加了6个行为类别。该数据集共包含5686张图像和45578个注释。它涵盖了从幼儿园到大学的不同场景。
2. 我们对SCBDataset3进行了广泛的基准测试,为今后的研究提供了坚实的基础。
3. 对于SCB-Dataset3中的大学场景数据,我们采用了“帧插值”方法并进行了实验验证。结果表明,该方法显著提高了行为检测的准确率。
4. 我们提出了一种新的度量标准——行为相似指数(BSI),用来衡量网络模型下不同行为之间在形式上的相似性。


 不同YOLO模型性能如下:
不同YOLO模型性能如下: