MapReduce
1、介绍MapReduce
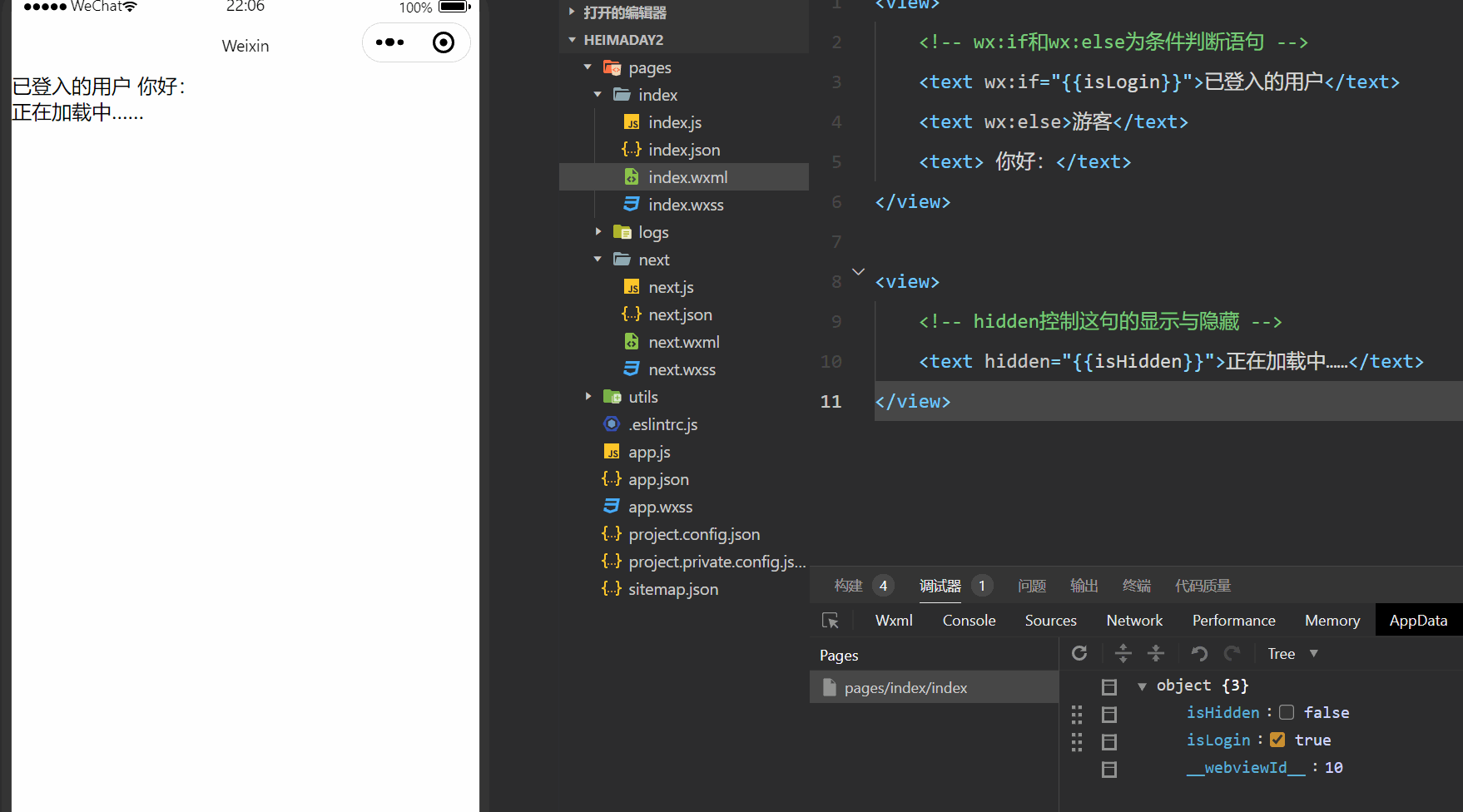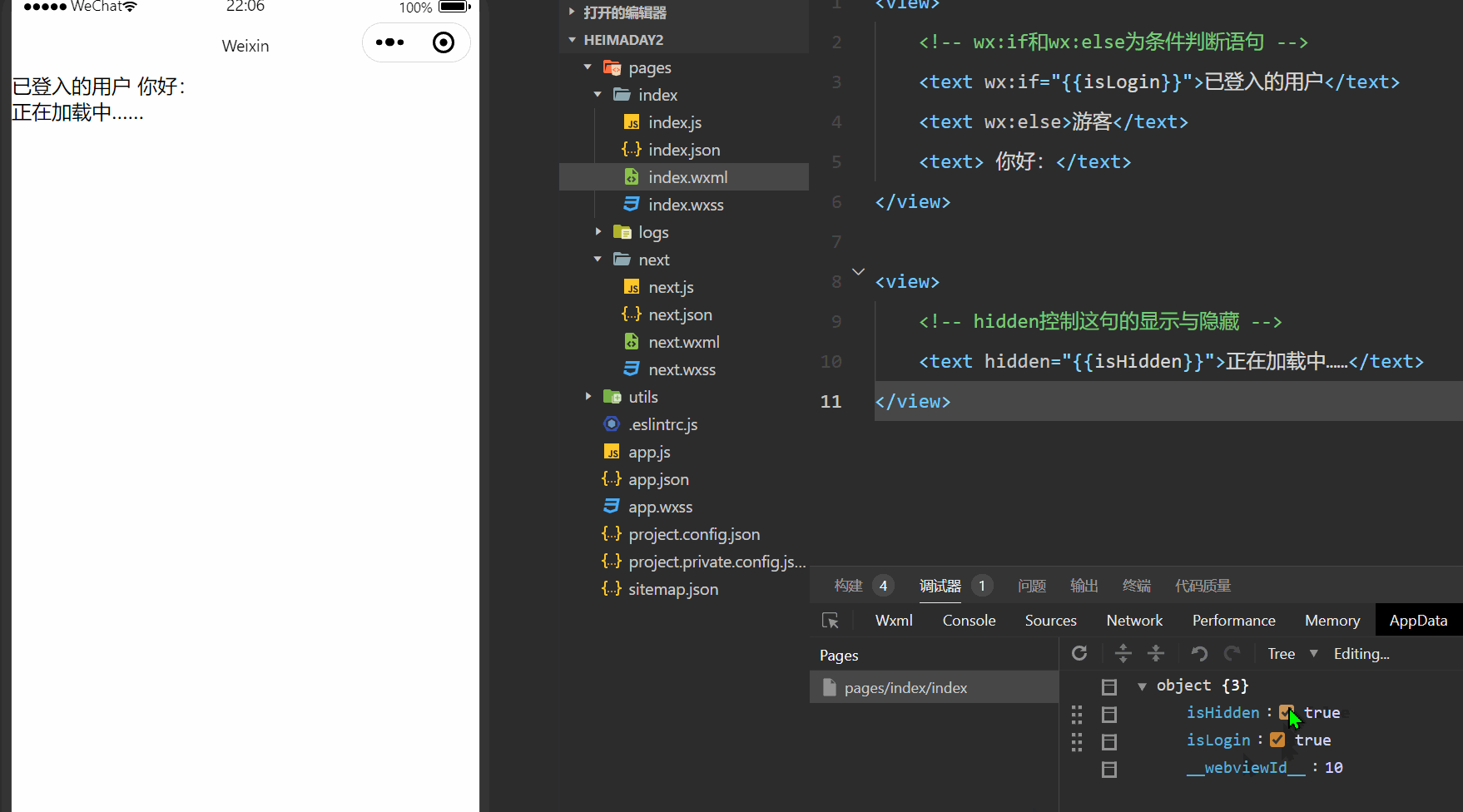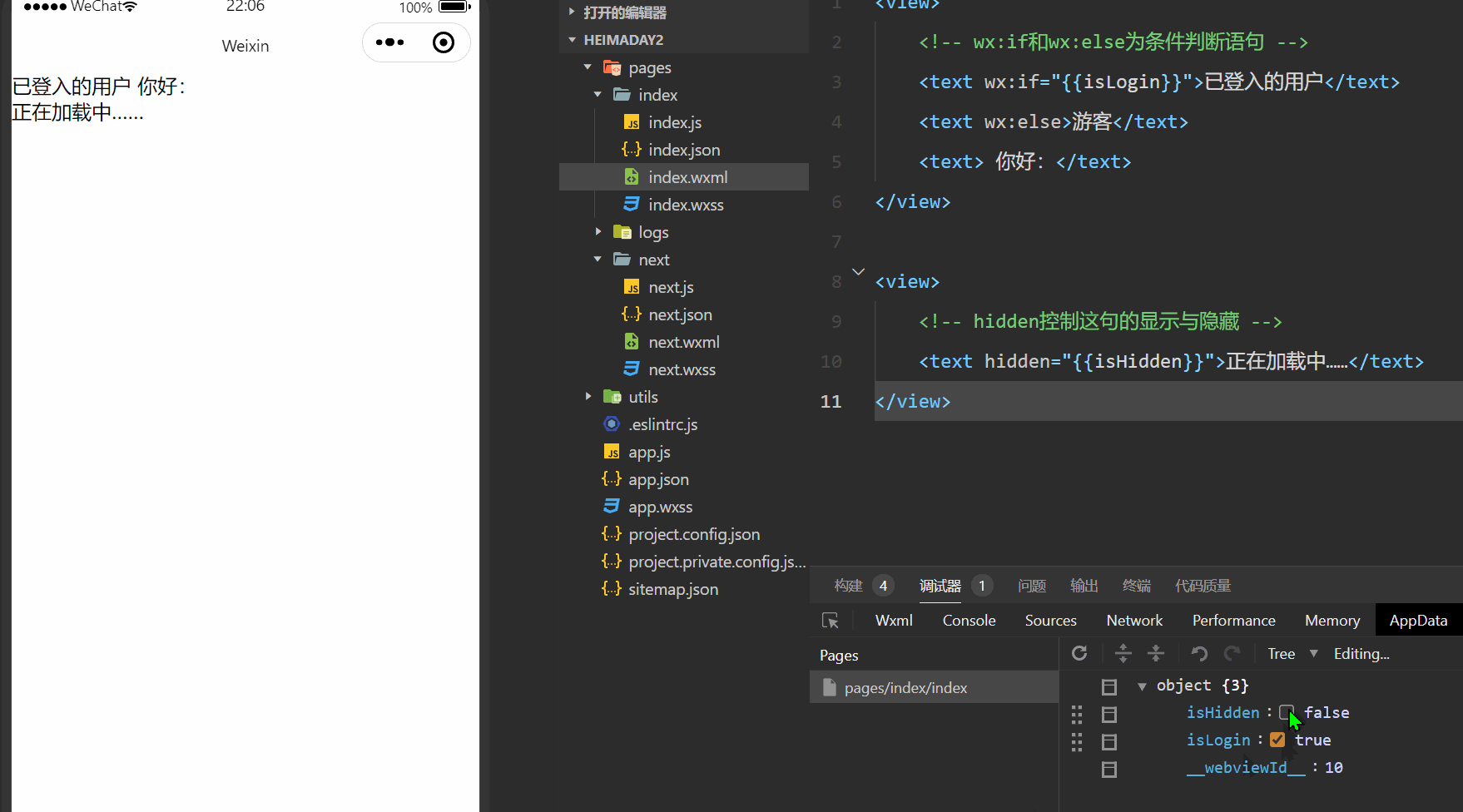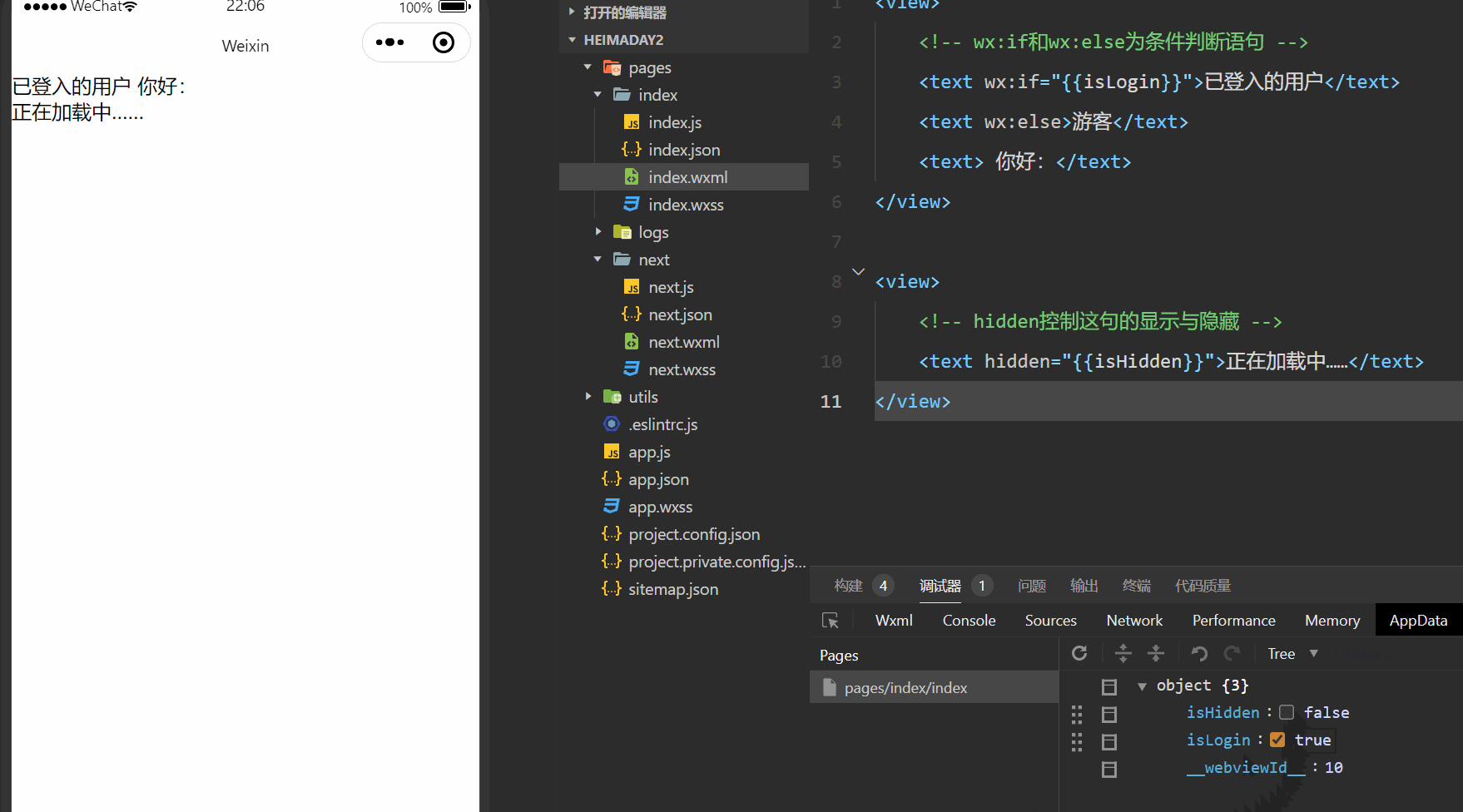
MapReduce的思想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。

图:MapReduce思想模型
2、样例Wordcount
- 定义一个mapper类
//首先要定义四个泛型的类型
//keyin: LongWritable valuein: Text
//keyout: Text valueout:IntWritable
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//map方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
- 定义一个reducer类
//生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组kv的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
- 定义一个主类,用来描述job并提交job
public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里……)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//指定我这个job所在的jar包
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class);
//指定要处理的数据所在的位置
FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置我们的业务逻辑Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
//指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/"));
//向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?0:1);
}
3、Combiner
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能。
例如:对于hadoop自带的wordcount的例子,value就是一个叠加的数字,
所以map一结束就可以进行reduce的value叠加,而不必要等到所有的map结束再去进行reduce的value叠加。

- 具体使用
自定义Combiner:
public static class MyCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(
Text key, Iterable<LongWritable> values,Context context)throws IOException, InterruptedException {
long count = 0L;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
};
}
- 在主类中添加
Combiner设置
// 设置Map规约Combiner
job.setCombinerClass(MyCombiner.class);
执行后看到map的输出和combine的输入统计是一致的,而combine的输出与reduce的输入统计是一样的。
4、partitioner
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。负责实现划分数据的类称作Partitioner。
- HashPartitioner源码如下
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
//默认使用key的hash值与上int的最大值,避免出现数据溢出 的情况
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
- key、value分别指的是Mapper任务的输出,numReduceTasks指的是设置的Reducer任务数量,默认值是1。那么任何整数与1相除的余数肯定是0。也就是说getPartition(…)方法的返回值总是0。也就是Mapper任务的输出总是送给一个Reducer任务,最终只能输出到一个文件中。
具体实现:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class FivePartitioner extends Partitioner<IntWritable, IntWritable>{
/**
* 我们的需求:按照能否被5除尽去分区
*
* 1、如果除以5的余数是0, 放在0号分区
* 2、如果除以5的余数不是0, 放在1分区
*/
@Override
public int getPartition(IntWritable key, IntWritable value, int numPartitions) {
int intValue = key.get();
if(intValue % 5 == 0){
return 0;
}else{
return 1;
}
}
}
- 在主函数里加入如下两行代码即可:
job.setPartitionerClass(FivePartitioner.class);
job.setNumReduceTasks(2);//设置为2
5、MapReduce的执行流程

-
详细流程
-
Map阶段
-
l 第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下,Split size = Block size。每一个切片由一个MapTask处理。(getSplits)
l 第二阶段是对切片中的数据按照一定的规则解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
l 第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个<k,v>,调用一次map方法。每次调用map方法会输出零个或多个键值对。
l 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
l 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。
l 第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
-
-
reduce阶段
-
l 第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
l 第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
l 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
-
6、MapReduce的shuffle阶段

-
shuffle被称作MapReduce的心脏,是MapReduce的核心。
-
由上图看出,每个数据切片由一个Mapper进程处理,也就是说mappper只是处理文件的一部分。
-
每一个Mapper进程都有一个环形的内存缓冲区,用来存储Map的输出数据,这个内存缓冲区的默认大小是100MB,当数据达到阙值0.8,也就是80MB的时候,一个后台的程序就会把数据溢写到磁盘中。在将数据溢写到磁盘的过程中要经过复杂的过程,首先要将数据进行分区排序(按照分区号如0,1,2),分区完以后为了避免Map输出数据的内存溢出,可以将Map的输出数据分为各个小文件再进行分区,这样map的输出数据就会被分为了具有多个小文件的分区已排序过的数据。然后将各个小文件分区数据进行合并成为一个大的文件(将各个小文件中分区号相同的进行合并)。
-
这个时候Reducer启动了三个分别为0,1,2。0号Reducer会取得0号分区 的数据;1号Reducer会取得1号分区的数据;2号Reducer会取得2号分区的数据。
-
map阶段:分区、排序、溢写、规约、合并
reduce阶段:复制、合并、排序、分组
7、MapReduce优化
7.1、资源相关参数
//以下参数是在用户自己的MapReduce应用程序中配置就可以生效
(1) mapreduce.map.memory.mb: 一个Map Task可使用的内存上限(单位:MB),默认为1024。如果Map Task实际使用的资源量超过该值,则会被强制杀死。
(2) mapreduce.reduce.memory.mb: 一个Reduce Task可使用的资源上限(单位:MB),默认为1024。如果Reduce Task实际使用的资源量超过该值,则会被强制杀死。
(3) mapreduce.map.cpu.vcores: 每个Maptask可用的最多cpu core数目, 默认值: 1
(4) mapreduce.reduce.cpu.vcores: 每个Reducetask可用最多cpu core数目默认值: 1
(5) mapreduce.map.java.opts: Map Task的JVM参数,你可以在此配置默认的java heap
size等参数, 例如:“-Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc”
(@taskid@会被Hadoop框架自动换为相应的taskid), 默认值: “”
(6) mapreduce.reduce.java.opts: Reduce Task的JVM参数,你可以在此配置默认的java
heap size等参数, 例如:“-Xmx1024m -verbose:gc -Xloggc:/tmp/@taskid@.gc”, 默认值: “”
//应该在yarn启动之前就配置在服务器的配置文件中才能生效
(1) yarn.scheduler.minimum-allocation-mb RM中每个容器请求的最小配置,以MB为单位,默认1024。
(2) yarn.scheduler.maximum-allocation-mb RM中每个容器请求的最大分配,以MB为单位,默认8192。
(3) yarn.scheduler.minimum-allocation-vcores 1
(4)yarn.scheduler.maximum-allocation-vcores 32
(5) yarn.nodemanager.resource.memory-mb 表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
//shuffle性能优化的关键参数,应在yarn启动之前就配置好
(1) mapreduce.task.io.sort.mb 100 shuffle的环形缓冲区大小,默认100m
(2) mapreduce.map.sort.spill.percent 0.8 环形缓冲区溢出的阈值,默认80%
7.2、容错相关参数
(1) mapreduce.map.maxattempts: 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
(2) mapreduce.reduce.maxattempts: 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
(3) mapreduce.map.failures.maxpercent: 当失败的Map Task失败比例超过该值,整个作业则失败,默认值为0. 如果你的应用程序允许丢弃部分输入数据,则该该值设为一个大于0的值,比如5,表示如果有低于5%的Map Task失败(如果一个Map Task重试次数超过mapreduce.map.maxattempts,则认为这个Map Task失败,其对应的输入数据将不会产生任何结果),整个作业任认为成功。
(4) mapreduce.reduce.failures.maxpercent: 当失败的Reduce Task失败比例超过该值为,整个作业则失败,默认值为0.
(5) mapreduce.task.timeout:如果一个task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该task处于block状态,可能是临时卡住,也许永远会卡住。为了防止因为用户程序永远block不退出,则强制设置了一个超时时间(单位毫秒),默认是600000,值为0将禁用超时。
7.3、效率跟稳定性参数
(1) mapreduce.map.speculative: 是否为Map Task打开推测执行机制,默认为true, 如果为true,则可以并行执行一些Map任务的多个实例。
(2) mapreduce.reduce.speculative: 是否为Reduce Task打开推测执行机制,默认为true
(3)mapreduce.input.fileinputformat.split.minsize: FileInputFormat做切片时最小切片大小,默认1。
(5)mapreduce.input.fileinputformat.split.maxsize: FileInputFormat做切片时最大切片大小
8、mapreduce程序在yarn上的执行流程
Hadoop jar xxx.jar

详细流程:
- 一:客户端向集群提交一个任务,该任务首先到ResourceManager中的ApplicationManager;
- 二:ApplicationManager收到任务之后,会在集群中找一个NodeManager,并在该NodeManager所在DataNode上启动一个AppMaster进程,该进程用于进行任务的划分和任务的监控;
- 三:AppMaster启动起来之后,会向ResourceManager中的ApplicationManager注册其信息(目的是与之通信);
- 四:AppMaster向ResourceManager下的ResourceScheduler申请计算任务所需的资源;
- 五:AppMaster申请到资源之后,会与所有的NodeManager通信要求它们启动计算任务所需的任务(Map和Reduce);
- 六:各个NodeManager启动对应的容器用来执行Map和Reduce任务;
- 七:各个任务会向AppMaster汇报自己的执行进度和执行状况,以便让AppMaster随时掌握各个任务的运行状态,在某个任务出了问题之后重启执行该任务;
- 八:在任务执行完之后,AppMaster向ApplicationManager汇报,以便让ApplicationManager注销并关闭自己,使得资源得以回收;
9、执行MapReduce常见的问题
- client对集群中HDFS的操作没有权限
在集群配置文件hdfs-site.xml
property>
<name>dfs.permissions</name>
<value>false</value>
</property>
然后重启
-
mapreduce的输出路径已存在,必须先删除掉那个路径
-
提交集群运行,运行失败
job.setJar("/home/hadoop/wordcount.jar");
- 日志打不出来,报警告信息
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
需要在项目的src下面新建file名为log4j.properties的文件
原文地址:https://blog.csdn.net/weixin_47120324/article/details/135680688
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_59552.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!