本文介绍: 分布式SQL执行引擎就是使用Spark提供的ThriftServer服务,以“后台进程”的模式持续运行,对外提供端口。SQL提交后,底层运行的就是Spark任务。相当于构建了一个以MetaStore服务为元数据,Spark为执行引擎的数据库服务,像操作数据库那样方便的操作SparkSQL进行分布式的SQL计算。
Spark On Hive的原理及配置
配置步骤
在代码中集成Spark On Hive
Spark分布式SQL执行原理及配置
配置步骤
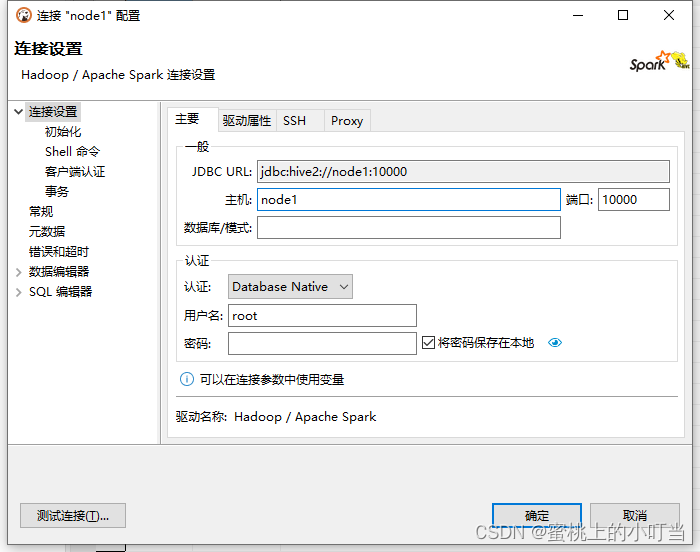
在代码中集成Spark JDBC ThriftServer
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。