本文介绍: ”’partitionBy(“Group”) 表示数据将根据 Group 列的值进行分区。在每个分区内,数据行将独立于其他分区处理。orderBy(“Value”) 指定了在每个分区内,数据将根据 Value 列的值进行排序。注:此时windowSpec 本身并不知道它将被应用于哪个 DataFrame。它只是定义了一个窗口规范”’
1 方法介绍
1.1 基本概念
1.2 over函数通常步骤
在 PySpark 中,使用 over 函数通常涉及以下步骤:
2 举例
2.1 创建DataFrame
假设有一个如下的 DataFrame:

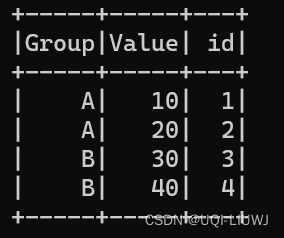
现在,如果你想在每个 Group 内部对 Value 进行排名,你可以使用 over 函数与 rank() 窗口函数结合来实现这一点:
2.2 定义窗口规范
2.3 应用窗口规范到 DataFrame

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




