目录
基于Arrow完成Pandas DataFrame和Spark DataFrame互转
窗口函数
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])
分析函数可以大致分成如下3类:
1- 第一类: 聚合函数 sum() count() avg() max() min()
2- 第二类: row_number() rank() dense_rank() ntile()
3- 第三类: first_value() last_value() lead() lag()
在Spark SQL中使用窗口函数案例:
需求是找出每个cookie中pv排在前3位的数据,也就是分组取TOPN问题
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql import Window as win
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder
.config('spark.sql.shuffle.partitions',1)
.appName('sparksql_win_function')
.master('local[*]')
.getOrCreate()
# 2- 数据输入
init_df = spark.read.csv(
path='file:///export/data/gz16_pyspark/02_spark_sql/data/cookie.txt',
schema='cookie string,datestr string,pv int',
sep=',',
encoding='UTF-8'
)
init_df.createTempView('win_data')
init_df.show()
init_df.printSchema()
# 3- 数据处理
# SQL
spark.sql("""
select
cookie,datestr,pv
from (
select
cookie,datestr,pv,
row_number() over (partition by cookie order by pv desc) as rn
from win_data
) tmp where rn<=3
""").show()
# DSL
"""
select:注意点,结果中需要看到哪几个字段,就要明确写出来
"""
init_df.select(
"cookie","datestr","pv",
F.row_number().over(win.partitionBy('cookie').orderBy(F.desc('pv'))).alias('rn')
).where('rn<=3').select("cookie","datestr","pv").show()
# 4- 数据输出
# 5- 释放资源
spark.stop()SQL函数分类
SQL函数,主要分为以下三大类:
-
UDF函数:用户自定义函数
-
特点:一对一,输入一个得到一个
-
例如:split() substr()
-
-
UDAF函数:用户自定义聚合函数
-
特点:多对一,输入多个得到一个
-
例如:sum() avg() count() min()
-
-
UDTF函数:用户自定义表数据生成函数
-
特点:一对多,输入一个得到多个
-
例如:explode()
-
在SQL中提供的所有的内置函数,都是属于以上三类中某一类函数
思考:有这么多的内置函数,为啥还需要自定义函数呢?
为了扩充函数功能。在实际使用中,并不能保证所有的操作函数都已经提前的内置好了。很多基于业务处理的功能,其实并没有提供对应的函数,提供的函数更多是以公共功能函数。此时需要进行自定义,来扩充新的功能函数

1- SparkSQL原生的时候,Python只能开发UDF函数
2- SparkSQL借助其他第三方组件,Python可以开发UDF、UDAF函数在Spark SQL中,针对Python语言,对于自定义函数,原生支持的并不是特别好。目前原生仅支持自定义UDF函数,而无法自定义UDAF函数和UDTF函数。
在1.6版本后,Java 和scala语言支持自定义UDAF函数,但Python并不支持。
Spark SQL原生存在的问题:大量的序列化和反序列
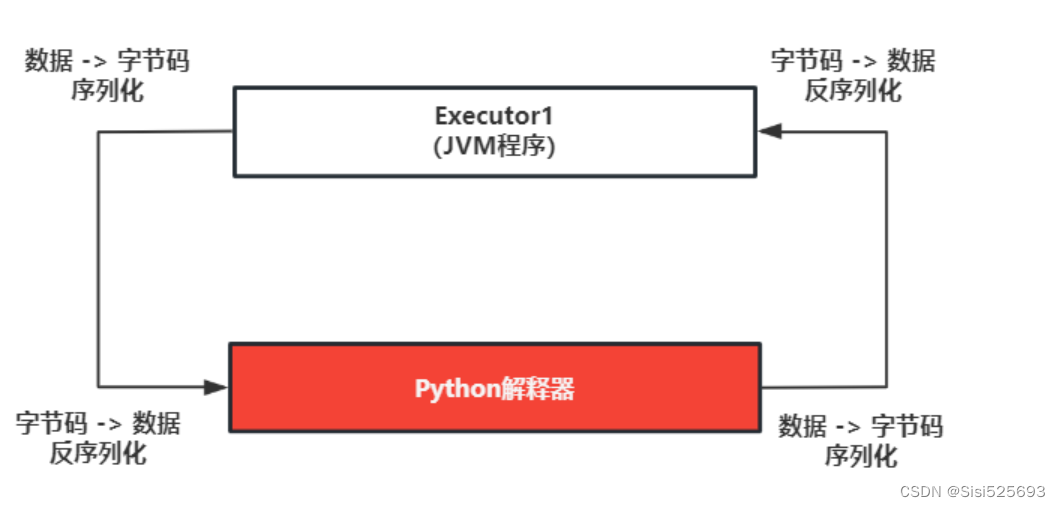
虽然Python支持自定义UDF函数,但是其效率并不是特别的高效。因为在使用的时候,传递一行处理一行,返回一行的方式。这样会带来非常大的序列化的开销的问题,导致原生UDF函数效率不好
早期解决方案: 基于Java/Scala来编写自定义UDF函数,然后基于python调用即可
目前主要的解决方案: 引入Arrow框架,可以基于内存来完成数据传输工作,可以大大的降低了序列化的开销,提供传输的效率,解决原生的问题。同时还可以基于pandas的自定义函数,利用pandas的函数优势完成各种处理操作
Spark原生自定义UDF函数
自定义函数流程:
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可
第二步: 将Python函数注册到Spark SQL中
注册方式一: udf对象 = sparkSession.udf.register(参数1,参数2,参数3)
参数1: 【UDF函数名称】,此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范
参数2: 【自定义的Python函数】,表示将哪个Python的函数注册为Spark SQL的函数
参数3: 【UDF函数的返回值类型】。用于表示当前这个Python的函数返回的类型
udf对象: 返回值对象,是一个UDF对象,可以在DSL中使用
说明: 如果通过方式一来注册函数, 【可以用在SQL和DSL】
注册方式二: udf对象 = F.udf(参数1,参数2)
参数1: Python函数的名称,表示将那个Python的函数注册为Spark SQL的函数
参数2: 返回值的类型。用于表示当前这个Python的函数返回的类型
udf对象: 返回值对象,是一个UDF对象,可以在DSL中使用
说明: 如果通过方式二来注册函数,【仅能用在DSL中】
注册方式三: 语法糖写法 @F.udf(returnType=返回值类型) 放置到对应Python的函数上面
说明: 实际是方式二的扩展。如果通过方式三来注册函数,【仅能用在DSL中】
第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可
# 自定义一个函数,完成对数据统一添加一个后缀名的操作
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# 绑定指定的Python解释器
from pyspark.sql.types import StringType
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("请自定义一个函数,完成对数据统一添加一个后缀名的操作_itheima")
# 1- 创建SparkSession对象
spark = SparkSession.builder
.config("spark.sql.shuffle.partitions",1)
.appName('sparksql_udf_basetype')
.master('local[*]')
.getOrCreate()
# 2- 数据输入
init_df = spark.createDataFrame(
data=[(1,'张三','广州'),(2,'李四','深圳')],
schema='id int,name string,address string'
)
init_df.printSchema()
init_df.show()
init_df.createTempView('tmp')
# 3- 数据处理
# 3.1- 创建自定义的Python函数
def add_suffix(address):
return address + "_itheima"
# 3.2- 将Python函数注册到Spark SQL
# 注册方式一
dsl_add_suffix = spark.udf.register('sql_add_suffix',add_suffix,StringType())
# 3.3- 在SQL/DSL中调用
# SQL
spark.sql("""
select
id,name,address,
sql_add_suffix(address) as new_address
from tmp
""").show()
# DSL
init_df.select(
"id",
"name",
"address",
dsl_add_suffix("address").alias("new_address")
).show()
print("-"*30)
# 在错误的地方调用了错误的函数。spark.udf.register参数1取的函数名只能在SQL中使用,不能在DSL中用。
# spark.sql("""
# select
# id,name,address,
# dsl_add_suffix(address) as new_address
# from tmp
# """).show()
# 注册方式二:UDF返回值类型传值方式一
dsl2_add_suffix = F.udf(add_suffix,StringType())
# DSL
init_df.select(
"id",
"name",
"address",
dsl2_add_suffix("address").alias("new_address")
).show()
# 注册方式二:UDF返回值类型传值方式二
dsl3_add_suffix = F.udf(add_suffix, 'string')
# DSL
init_df.select(
"id",
"name",
"address",
dsl3_add_suffix("address").alias("new_address")
).show()
# 注册方式三:语法糖/装饰器
@F.udf(returnType=StringType())
def add_suffix_candy(address):
return address + "_itheima"
# DSL
init_df.select(
"id",
"name",
"address",
add_suffix_candy("address").alias("new_address")
).show()
# 4- 数据输出
# 5- 释放资源
spark.stop()Pandas的UDF函数
Apache Arrow框架基本介绍
Apache Arrow是Apache旗下的一款顶级的项目。是一个跨平台的在内存中以列式存储的数据层,它的设计目标就是作为一个跨平台的数据层,来加快大数据分析项目的运行效率
Pandas 与 Spark SQL 进行交互的时候,建立在Apache Arrow上,带来低开销 高性能的UDF函数
Arrow并不会自动使用,在某些情况下,需要配置 以及在代码中需要进行小的更改才可以使用
如何安装? 三个节点建议都安装
检查服务器上是否有安装pyspark
pip list | grep pyspark 或者 conda list | grep pyspark如果服务器已经安装了pyspark的库,那么仅需要执行以下内容,即可安装。例如在 node1安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark[sql]
如果服务器中python环境中没有安装pyspark,建议执行以下操作,即可安装。例如在 node2 和 node3安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyarrow==10.0.0
如何使用呢? 默认不会自动启动的, 一般建议手动配置
sparkSession.conf.set(‘spark.sql.execution.arrow.pyspark.enabled’,True)
基于Arrow完成Pandas DataFrame和Spark DataFrame互转
使用场景:
1- Spark的DataFrame -> Pandas的DataFrame:当大数据处理到后期的时候,可能数据量会越来越少,这样可以考虑使用单机版的Pandas来做后续数据的分析
2- Pandas的DataFrame -> Spark的DataFrame:当数据量达到单机无法高效处理的时候,或者需要和其他大数据框架集成的时候,可以转成Spark中的DataFrame
总结:
Pandas的DataFrame -> Spark的DataFrame: spark.createDataFrame(data=pandas_df)
Spark的DataFrame -> Pandas的DataFrame: init_df.toPandas()
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("基于Arrow完成Pandas DataFrame和Spark DataFrame互转")
# 1- 创建SparkSession对象
spark = SparkSession.builder
.appName('dataframe')
.master('local[*]')
.getOrCreate()
# 手动开启Arrow框架
spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)
# 2- 数据输入
init_df = spark.createDataFrame(
data=[(1, '张三', '广州'), (2, '李四', '深圳')],
schema='id int,name string,address string'
)
# 3- 数据处理
# sparksql dataframe -> pandas dataframe
pd_df = init_df.toPandas()
print(type(pd_df),pd_df)
new_pd_df = pd_df[pd_df['id']==2]
# pandas dataframe -> sparksql dataframe
spark_df = spark.createDataFrame(data=new_pd_df)
spark_df.show()
spark_df.printSchema()
# 4- 数据输出
# 5- 释放资源
spark.stop()基于Pandas完成UDF函数
基于Pandas的UDF函数来转换为Spark SQL的UDF函数进行使用。底层是基于Arrow框架来完成数据传输,允许向量化(可以充分利用计算机CPU性能)操作。
Pandas的UDF函数其实本质上就是Python的函数,只不过函数的传入数据类型为Pandas的类型
基于Pandas的UDF可以使用自定义UDF函数和自定义UDAF函数
自定义函数流程:
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可
第二步: 将Python函数包装成Spark SQL的函数
注册方式一: udf对象 = spark.udf.register(参数1, 参数2)
参数1: UDF函数名称。此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范
参数2: Python函数的名称。表示将哪个Python的函数注册为Spark SQL的函数
使用: udf对象只能在DSL中使用。参数1指定的名称只能在SQL中使用
注意: 如果编写的是UDAF函数,那么注册方式一需要配合注册方式三,一起使用
注册方式二: udf对象 = F.pandas_udf(参数1, 参数2)
参数1: 自定义的Python函数。表示将哪个Python的函数注册为Spark SQL的函数
参数2: UDF函数的返回值类型。用于表示当前这个Python的函数返回的类型对应到Spark SQL的数据类型
udf对象: 返回值对象,是一个UDF对象。仅能用在DSL中使用
注册方式三: 语法糖写法 @F.pandas_udf(returnType=返回值Spark SQL的数据类型) 放置到对应Python的函数上面
说明: 实际是方式一的扩展。仅能用在DSL中使用
第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可
自定义UDF函数
自定义Python函数的要求:SeriesToSeries
表示:第一步中创建自定义Python函数的时候,输入参数的类型和返回值类型必须都是Pandas中的Series类型
需求:完成a列和b列的求和计算操作
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pandas as pd
import pyspark.sql.functions as F
# 绑定指定的Python解释器
from pyspark.sql.types import IntegerType
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder
.appName('pandas_udf')
.master('local[*]')
.getOrCreate()
# 手动开启Arrow框架
spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)
# 2- 数据输入
init_df = spark.createDataFrame(
data=[(1,2),(2,3),(3,4)],
schema='num1 int,num2 int'
)
init_df.createTempView('tmp')
# 3- 数据处理
# 3.1- 自定义Python函数
"""
1- num1:pd.Series用来限定输入的参数类型是Pandas中的Series对象
2- -> pd.Series用来限定返回值类型是Pandas中的Series对象
"""
def my_sum(num1:pd.Series, num2:pd.Series) -> pd.Series:
return num1+num2
# 3.2- 注册进SparkSQL。注册方式一
dsl_my_sum = spark.udf.register('sql_my_sum',my_sum)
# 3.3- 使用
# SQL
spark.sql("""
select
num1,num2,
sql_my_sum(num1,num2) as result
from tmp
""").show()
# DSL
init_df.select(
"num1",
"num2",
dsl_my_sum("num1", "num2").alias("result")
).show()
# 注册方式二
dsl2_my_sum = F.pandas_udf(my_sum,IntegerType())
# DSL
init_df.select(
"num1",
"num2",
dsl2_my_sum("num1", "num2").alias("result")
).show()
# 注册方式三
@F.pandas_udf(IntegerType())
def my_sum_candy(num1:pd.Series, num2:pd.Series) -> pd.Series:
return num1+num2
# DSL
init_df.select(
"num1",
"num2",
my_sum_candy("num1", "num2").alias("result")
).show()
# 4- 数据输出
# 5- 释放资源
spark.stop()
自定义UDAF函数
自定义Python函数的要求:Series To 标量
表示:自定义函数的输入数据类型是Pandas中的Series对象,返回值数据类型是标量数据类型。也就是Python中的数据类型,例如:int、float、bool、list….
需求:对某一列数据计算平均值的操作
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pandas as pd
import pyspark.sql.functions as F
# 绑定指定的Python解释器
from pyspark.sql.types import IntegerType, FloatType
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder
.appName('pandas_udaf')
.master('local[*]')
.getOrCreate()
# 手动开启Arrow框架
spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)
# 2- 数据输入
init_df = spark.createDataFrame(
data=[(1,2),(2,3),(3,3)],
schema='num1 int,num2 int'
)
init_df.createTempView('tmp')
# 3- 数据处理
# 3.1- 自定义Python函数
"""
UDAF对自定义Python函数的要求:输入数据的类型必须是Pandas中的Series对象,返回值类型必须是Python中的标量数据类型
"""
@F.pandas_udf(returnType=FloatType())
def my_avg(num2_col:pd.Series) -> float:
print(type(num2_col))
print(num2_col)
# 计算平均值
return num2_col.mean()
# 3.2- 注册进SparkSQL。注册方式一
dsl_my_avg = spark.udf.register('sql_my_avg',my_avg)
# 3.3- 使用
# SQL
spark.sql("""
select
sql_my_avg(num2) as result
from tmp
""").show()
# DSL
init_df.select(dsl_my_avg("num2").alias("result")).show()
# 4- 数据输出
# 5- 释放资源
spark.stop()原文地址:https://blog.csdn.net/denglh525693/article/details/135632833
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_59590.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




