引导
今天我们开始学习栈与队列的内容,我觉得栈并不难,所以篇幅也就不会那么多了。在虚拟空间中,栈是用户空间中的一种数据结构,它主要用于保存局部变量。那么问题来了,为什么用栈来保存局部变量,不用别的数据结构呢?堆,数组,链表不可以吗?
栈
我们知道栈的特点就是先进后出,后进先出。其实,我们可以这样定义,满足先进后出,后进先出操作特性的就是栈。因此栈没有固定的存储形式,比如数据是需要存储地址连续,链表存储地址可以不连续。栈可以用数组或链表都可以实现,只要它满足先进后出,后进先出操作特性即可。
栈的复杂度
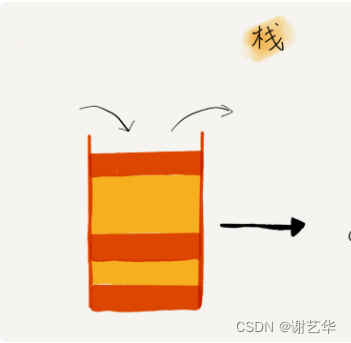
栈的操作只有入栈和出栈,并且只涉及到栈顶的元素。所以它的复杂度都为O(1)。如图:
栈的应用
特定的数据结构是对特定场景的抽象。那么有些问题用栈来处理肯定会比较方便。
栈在表达式中的使用
在《程序语言设计基础》中有关于表达式知识点:比如一个3+5*8-6的表达式,你会怎么设计,让计算机去识别,计算呢?记得以前写过类似的程序,现在想想还有很多的优化空间。
在表达式中,有中缀表达式,前缀表达式,后缀表达式3种。它们的分析方式也不相同。有兴趣的可以去了解一下我的另一篇文章【献给过去的自己】栈实现计算器(C语言)-CSDN博客。
栈在函数调用中的应用
正如我们在开头引入的话题,为什么局部变量要保存在栈中?这里有几点需要解释:
- 局部变量保存在栈中,这个栈是内存中实际存在的栈,是真实的物理区。而我们全文所介绍的栈是一个数据结构,是抽象的。要区分开两个栈。
- 内存中的栈因为它的操作特性符合栈数据结构的特点,所以称为栈区。栈区主要存储运行方法的形参、局部变量、返回值。由系统自动分配和回收。
那么我们为什么要将局部变量保存在栈区呢?
其实我们并不是必须要使用栈结构,使用数组和链表也是可以的。可能稍微会麻烦点。函数之间调用,变化的主要是作用域及生命周期。
针对作用域和生面周期变化的,我觉得栈可以很好的实现。进入一个函数时,在栈中记录入口(作用域界限),之后进行压栈操作,在该函数内部只能访问界限以内的数据。当退出函数时,将入口以内的数据直接释放。
队列
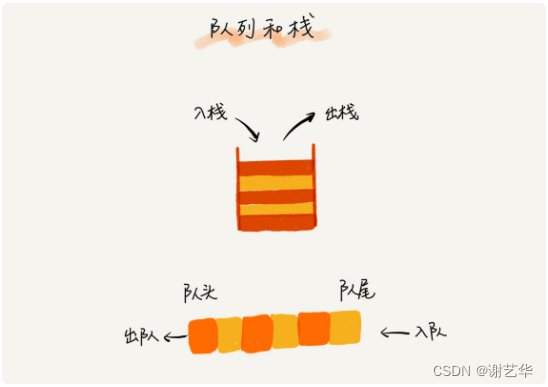
队列和栈都是抽象的数据结构,是一个操作受限的线性表。它的特点就是先进先出(FIFO)。 它的操作又入队(将一个数据放到队尾)和出队(从队列头部取出一个数据)。和栈相似,如图:
顺序队列
队列和栈一样,都能用数组和链表来实现。用数组实现就是顺序队列,用链表实现就是链式队列。我这里就简单用C语言实现一个顺序队列。
|
queue_len = 100 } } |
循环队列
在上面的队列中,当tail等于队列长度时,就需要进行数据搬移。循环队列就是省去了这个操作。循环队列的难点就在于如何确定队列满和队列空
堆满的判断方式会浪费数组中一个元素。故循环队列可按照下列实现:
|
queue_len = 100 |
队列的用途
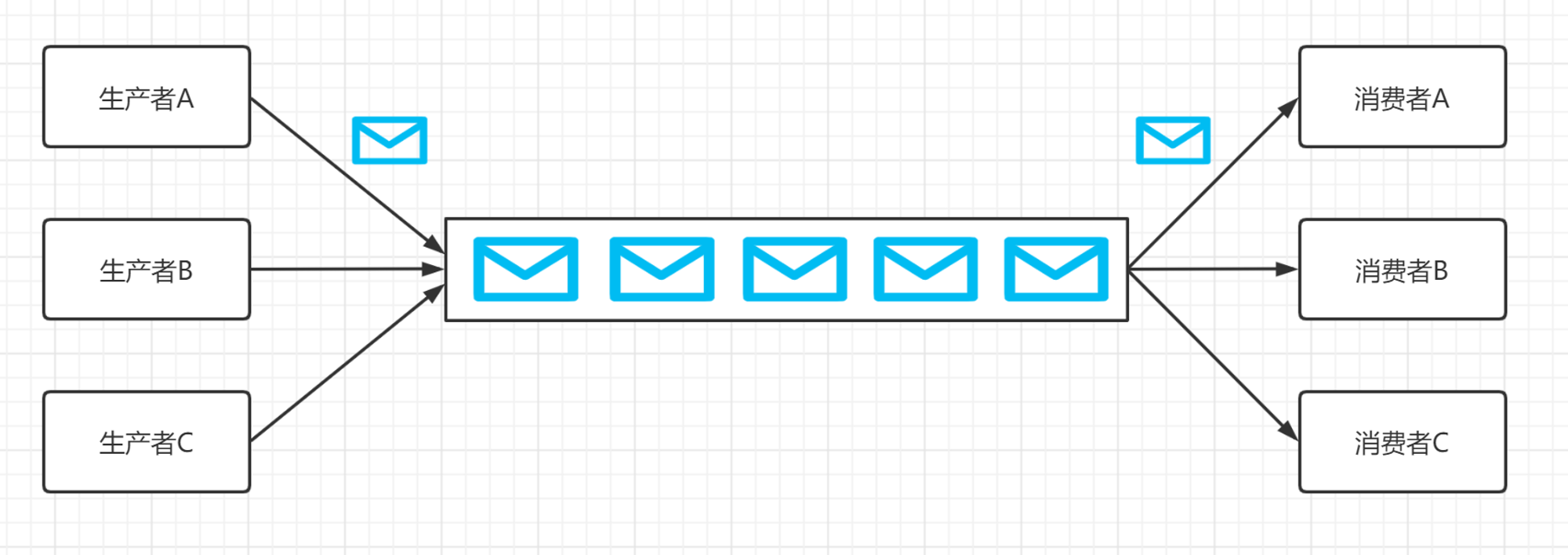
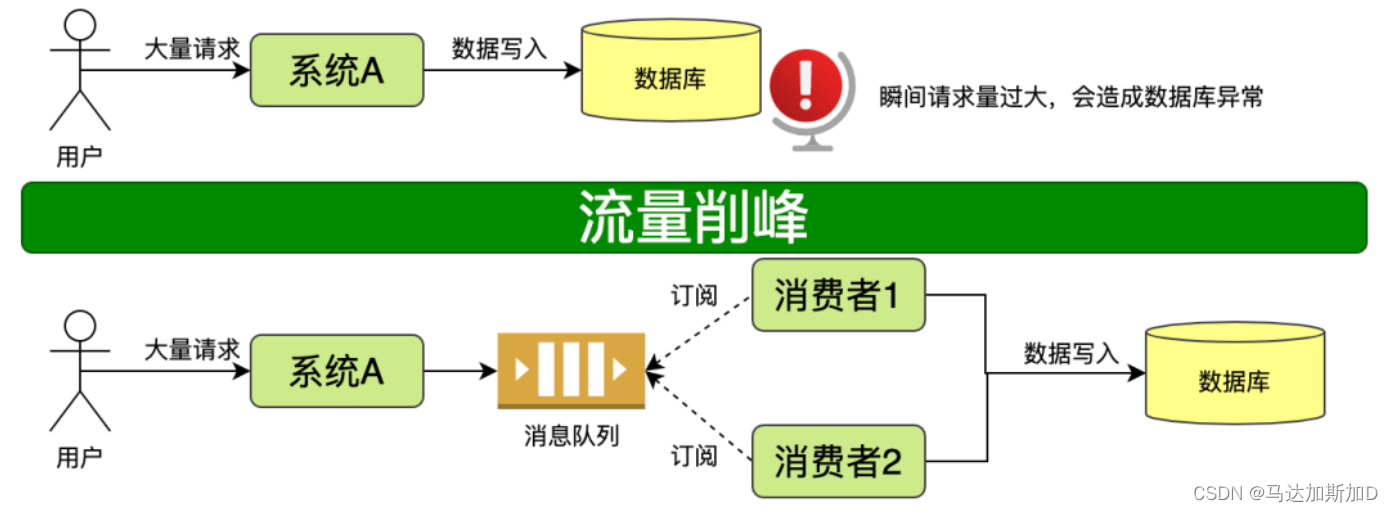
队列一般用于缓存操作。比如消息队列,线程池等都是使用了队列。但是队列的大小设置是需要我们关注的。我个人主要的考虑依据是:在可接受的反应时间内,将队列设置到最大。
总结
本节主要介绍了栈数据结构,它具有先进后出,后进先出的操作特点。以及栈的在表达式和函数调用上的应用。一定要区别栈数据结构和内存中的栈不是完全相同的概念。算是交际关系.
队列的概念,并实现了队列和循环队列。以及队列大小设置的依据。
原文地址:https://blog.csdn.net/xieyihua1994/article/details/134555922
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_5963.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!