本文介绍: Vision MLP合集
一、MLP-Mixer
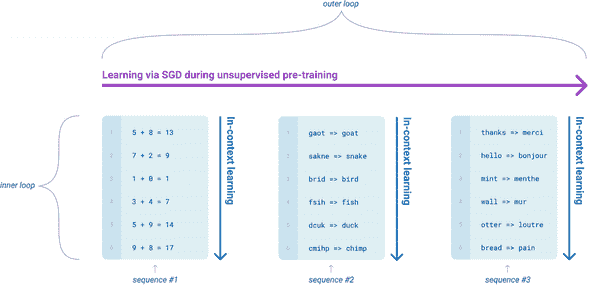
使用纯MLP处理图像信息,其原理类似vit,将图片进行分块(patch)后展平(fallten),然后输入到MLP中。理论上MLP等价于1×1卷积,但实际上1×1卷积仅能结合通道信息而不能结合空间信息。根据结合的信息不同分为channel-mixing MLPs和token-mixing MLPs。
总体结构如下图,基本上可以视为以mlp实现的vit。
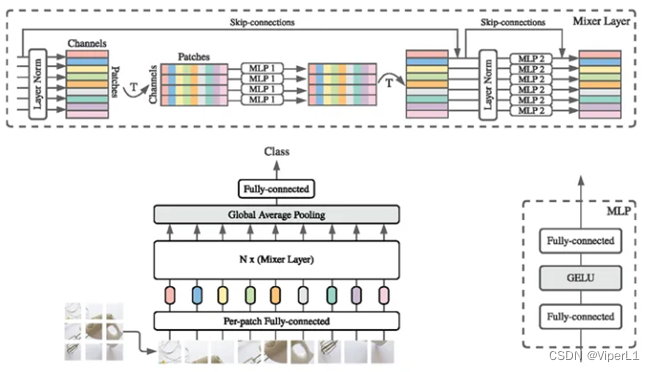
二、RepMLP
传统卷积仅能处理局部领域信息,不具备捕获长程依赖的能力,其特性被称为归纳偏置(inductive bias)或局部先验性质(local prior)。而Transformer虽然可以使用自注意力捕获长程依赖,却无法有效获取局部先验信息。全连接(FC)结构与Transformer类似,可以捕获长程依赖(每个输入和输出都有连接)但是缺乏局部先验性质。而RepVGG则是通过将MLP和CNN的优点结合在一起实现高质量的特征提取。其核心是结构重参数技术(structural reparameterization technique)。
训练时的RepMLP与预测时截然不同。训练时,每一层都会添加平行的卷积+BN分支,而预测时会将卷积分支等效为MLP分支。



三、ResMLP


四、gMLP

五、CycleMLP
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。