一,数据库概述
1.1 数据库
数据库(DataBase,DB):存储在磁带 磁盘 光盘或其他外存介质上,按照一定结构组织在一起的相关数据的集合
数据库管理系统(DataBase Management System,DBMS):一种操纵和管理数据库的大型软件 用于建立,使用和维护数据库
数据库系统(DataBase System,DBS):由数据库和数据库管理系统组成
简单来说 数据库存放数据 ,数据库管理系统操作数据 他们的集合为数据库系统
1.2 了解 ACID 理论
ACID 理论是定义数据库管理系统 (DBMS) 中事务的可靠性和一致性的四个关键特征。首字母缩略词 ACID 代表原子性、一致性、隔离性和持久性。以下是对每个属性的简要说明:
原子性确保事务被视为一个单一的、不可分割的工作单元。事务中的所有操作要么都成功完成,要么都没有。如果事务的任何部分失败,则整个事务将回滚到最初的状态,以确保数据的一致性和完整性。
一致性确保事务将数据库从一种一致状态带到另一种一致状态。数据库在事务执行前后都处于一致状态。换句话说,数据库在整个事务过程中保持一致,并且强制执行所有约束和规则,这可确保数据始终准确且最新。
隔离性(Isolation)
隔离确保多个事务可以并发执行且独立,而不会相互干扰。每个事务在完成之前必须与其他事务是隔离开来的。一个事务的结果不会影响另一个事务的结果,这种隔离可以防止脏读、不可重复读和幻读。
持久性确保一旦事务被提交,就永久记录在数据库中,不可撤销。这意味着即使在系统出现故障的情况下,数据仍然是安全的并且可以恢复。
ACID 理论对于确保了 DBMS 和分布式系统的可靠和一致的数据管理至关重要。通过理解原子性、一致性、隔离性和持久性的概念,开发人员可以设计出既健壮又可扩展的分布式数据库系统。即使存在系统故障、网络问题或其他问题,这些特性能保障系统数据一致性、完整性和可靠性。
1.3 识别数据库
Oracle:1521
MySQL:3306
SQL Server:1433
Redis:6379
常见的搭配

二,SQL 语法基础
三,SQL语句实例
3.1 SQL基础语句
CREATE
创建数据库 并启用数据库
CREATE DATABASE testdb;
use testdb;创建数据库表以及表内的列
CREATE TABLE offices (officeCode INT,city VARCHAR(10),phone INT,addressLine VARCHAR(20));
INSERT
向表中添加数据
INSERT INTO offices (officeCode, city, phone, addressLine) VALUES (1, ‘japan’, 12345678, ‘addressLine1′);
INSERT INTO offices (officeCode, city, phone, addressLine) VALUES (2, ‘Germany‘, 123456789, ‘addressLine2′);SELECT
UODATE
修改表中数据 并查询结果
UPDATE offices SET city=’China’ WHERE officeCode=1;
DELETE
DELETE from offices where officecode=8;
3.2 SQL高级语句
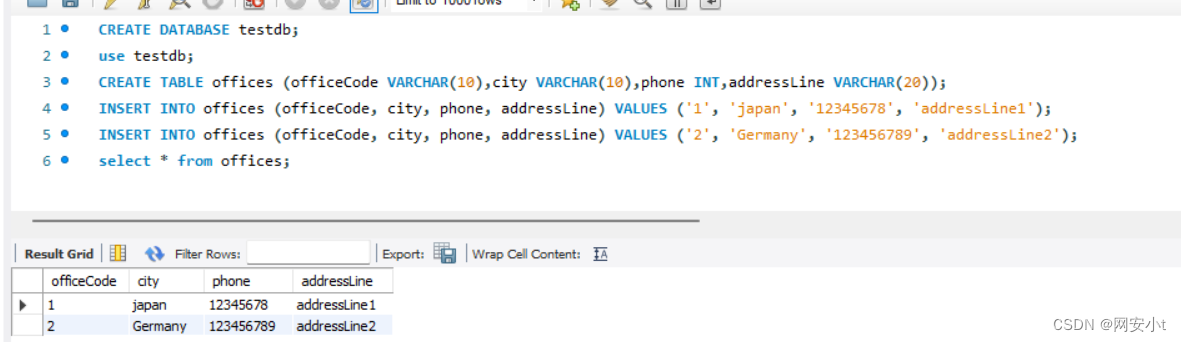
当前数据库中offices表内容
SELECT * FROM offices ORDER BY phone;
先排序后分组 必须要有聚合函数 sum() count() avg()来配合才能使用
SELECT city,COUNT(*) FROM offices GROUP BY city;
限定条数 limit
SELECT * FROM offices limit 0,3;
SELECT * FROM offices limit 1,4;
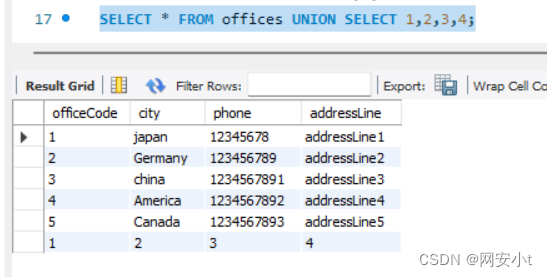
SELECT * FROM offices UNION SELECT 1,2,3,4;
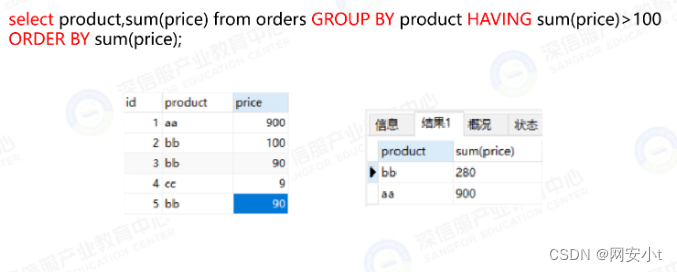
首先通过group by 进行分组 再通过HAVING筛选 筛选条件为:每组price的累加的值大于100
最后通过order by 对累加值 进行排序 最后输出查询结果







四,基于SQL注入理解语法/函数
4.1 语法
ORDER BY
SELECT * FROM offices ORDER BY 1;查询该表所有字段 通过第一列officeCode排序
SELECT * FROM offices ORDER BY 2;查询该表所有字段 通过第二列city排序
SELECT * FROM offices ORDER BY 3;查询该表所有字段 通过第三列phone排序
SELECT * FROM offices ORDER BY 4;查询该表所有字段 通过第四列addressLine排序
SELECT * FROM offices ORDER BY 5;
如果 查询第五个不存在的字段 就会报错 通过这一点也能判断出 该表有几个字段
UNION SELECT
在联合查询中 通过构造语句 可直接否认之前的查询 执行通过union后查询的语句
在使用 UNION 运算符进行联合查询时,两个 SELECT 语句的列数、数据类型和顺序必须严格匹配。这是因为 UNION 会将两个查询的结果合并在一起,并去除重复的行,如果两个 SELECT 查询返回的列不匹配,数据库就无法正确执行这个操作。
需要注意的是查询的列应当和之前对应( 因为原查询语句与union查询的四个值的结果集合并 所以原字段有4个 联合查询必须也要有4个位置的值)可以理解为通过union可以猜字段数 如果查询的数量与列数相等了才会输出 否则报错
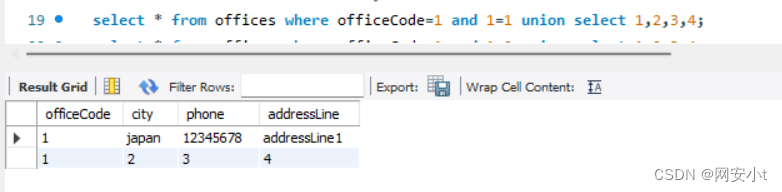
select * from offices where officeCode=1 and 1=1 union select 1,2,3,4;
使用and 一假则假的方式 否认union前查询语句 否认后 执行union后的查询语句 查询内容输出到每一个列名下 每一个联合查询值要对应一个列
select * from offices where officeCode=1 and 1=2 union select 1,2,3,4;
知道列名后 就可以通过联合查询把相应列的值暴出来 (说是知道列名就行 但是我看查询语句必须在后面输入表名)
select * from offices where officeCode=1 and 1=2 union select city,2,3,4 from offices;
4.2 函数
该函数用于检查子查询是否至少会返回一行数据 实际上不返回任何数据 而是返回True或者False
select * from offices where city=”china” and exists(select * from offices);
select * from offices where city=”china” and exists(select * from officess);
select * from offices where officeCode=1 and 1=1 union select 0,0,0,load_file(“D:/test.txt“) from offices;
我这个没读取到 不知道什么原因估计是mysql配置的原因 靶场都是正常成功的






五,目录数据库infomation_schema
在mysql 5.5以上版本中自带 infomation_schema数据库 保存着该服务器维护的所有数据库 表 列信息等等
通过联合查询暴所有数据库
select * from offices where city=”china” and 1=2 union select table_name,table_schema,0,0
from information_schema.tables where table_schema=”testdb” ;



原文地址:https://blog.csdn.net/m0_72125469/article/details/134581900
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_5979.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






