本文介绍: a3 = f(x)
【吴恩达p60-61】
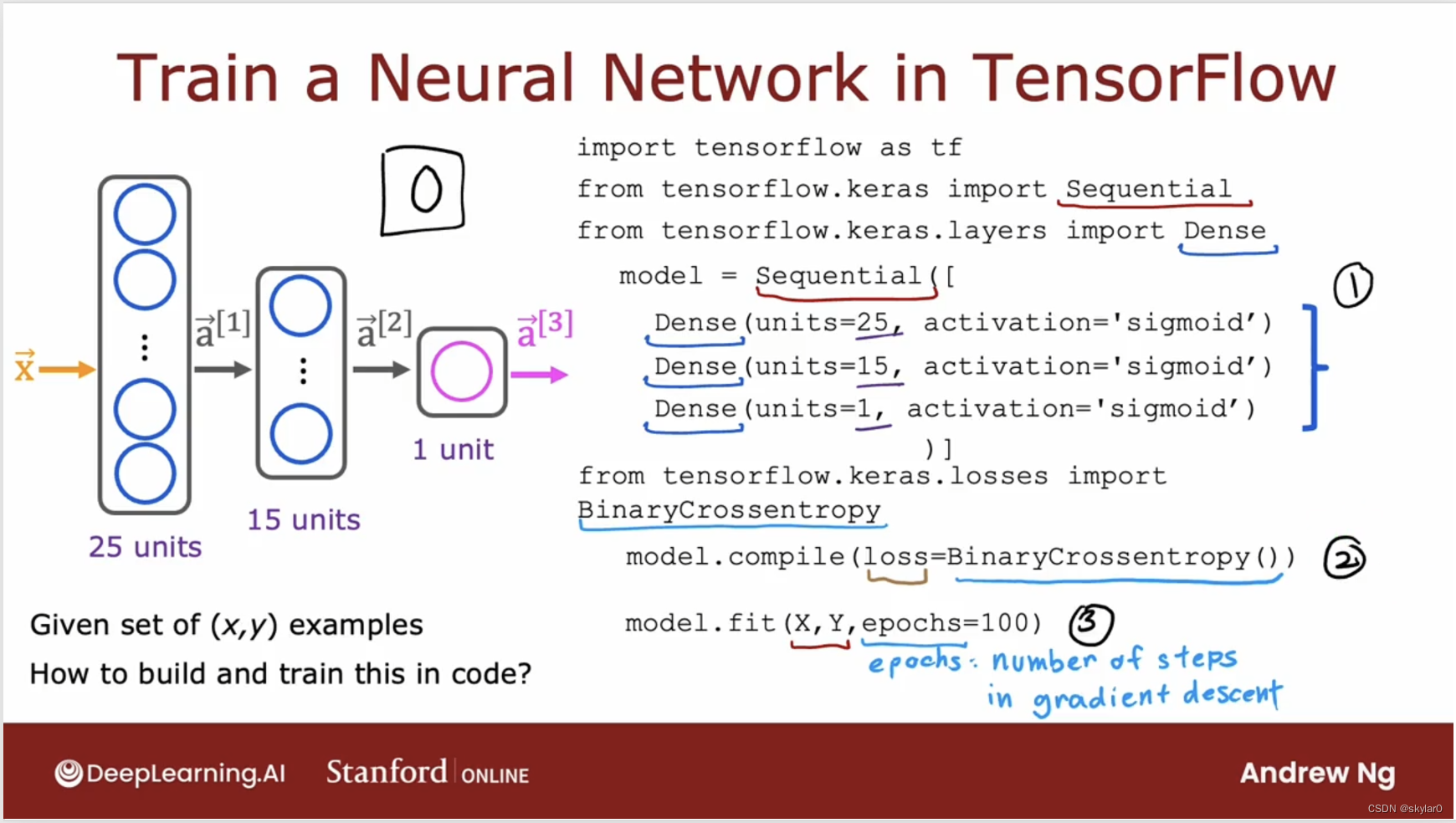
1. Tensorflow实现
- 继续看手写数字识别的例题
- 第一步,我们上周学习了。
- 第二步,让Tensorflow去编译模型。最重要的一步是通过指定你想使用的loss函数。(这里我们会用BinaryCrossentropy)
- 第三步,使用fit函数告诉Tensorflow将在第一步中指定的model,和第二步中指定的cost function拟合到XY。(第3步是用来训练模型的)
- epoch是一个专业名词,指定gradient descent步骤的数量。
2. 模型训练细节
【了解Tensorflow训练模型的代码细节。】
- 训练模型的三个步骤:
- 定义模型f(x)。
- 找出loss + cost function。(loss是单个样本的误差,cost是整体的误差和)
- 训练数据,最小化cost function。(ex. 使用gradient descent)
- 使用这3步训练neural network的模型:
- 定义model的式子。
- compile模型,并且告诉它你想使用的loss function。(这里的代码表示,我们将使用Binary Cross Entropy作为loss function。后续通过对其取平均值,可以得到整个neural network的cost function。)
- 调用函数,去最小化cost function。

2.1 定义模型f(x)
- a3 = f(x)

2.2 找到loss and cost funciton
- 必须指定loss function,这也会用来定义cost function。
- L(f(x), y)函数里y是truth label(target label
- f(x)是neural network的output。
- Tensorflow知道你要最小化cost是所有training example loss的平均值。
- 如果项训练的是regression的模型,你也可以告诉Tensorflow使用不同的loss function编译模型。(比如,要去最小化mean squared error,就可以让loss = MeanSquaredError())
- 神经网络里的W,B都是2维的数据


2.3 Gradient descent
- 需要分别对每一层每一神经元,更新它们的w,j。
- backpropagation反向传播:用来计算neural network里偏导项的一种算法。(Tensorflow可以做到:model.fit(x,y, epochs = 100),epochs表示,迭代100次。)
- 事实上,Tensorflow可以使用另一种比gradient descent更快的算法来做。

原文地址:https://blog.csdn.net/skylar0/article/details/135591395
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_59794.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






