本文介绍: 在C语言中,编译和链接是将源代码转换为可执行文件的两个主要步骤。预处理:将源代码中的预处理指令(如#include和#define)替换为实际的代码。编译:将预处理后的代码转换为汇编语言。汇编:将汇编语言转换为机器码指令。目标文件生成:将每个源文件编译后生成的目标文件(.o或.obj)进行合并,生成一个总的目标文件。符号解析:查找并解析目标文件中的所有符号(例如全局变量和函数名),以确保每个符号都有一个唯一的地址。
前言
在C语言中,编译和链接是将源代码转换为可执行文件的两个主要步骤。
编译过程包括以下步骤:
链接过程包括以下步骤:
在编译和链接过程中,可以使用不同的编译器和链接器来完成这些步骤。常见的C语言编译器包括GCC、Clang和MSVC等,而常见的链接器包括GNU ld和Microsoft Linker等。
编译器和链接器的具体命令和选项可以根据不同的平台和编译环境而有所不同,可以通过编译器和链接器的帮助文档或命令行参数来了解更多信息。
一、 翻译环境和运行环境
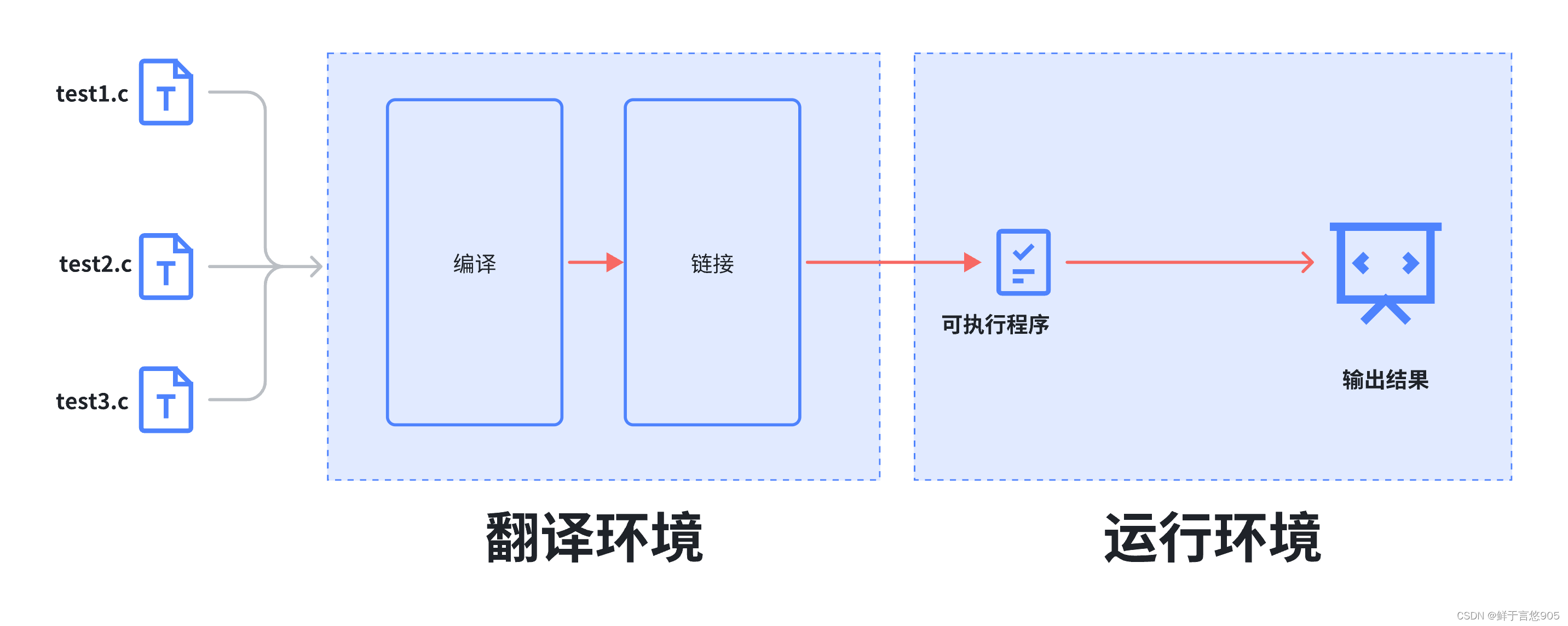
二、 翻译环境
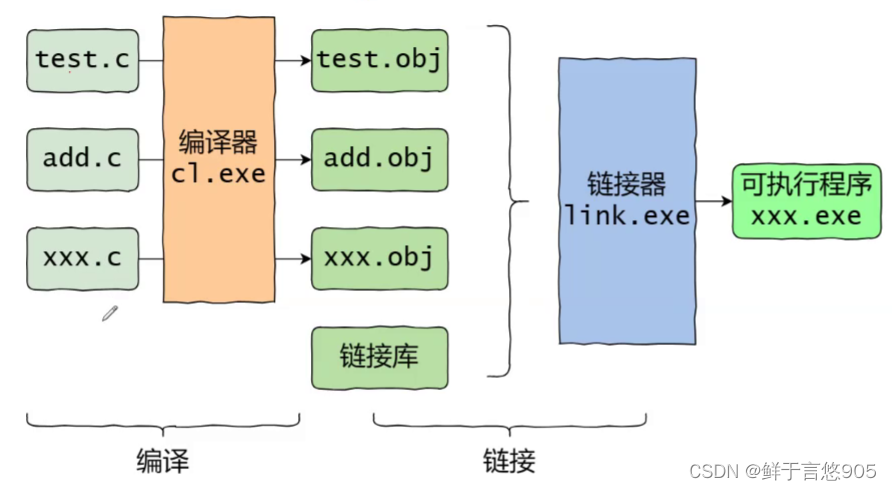
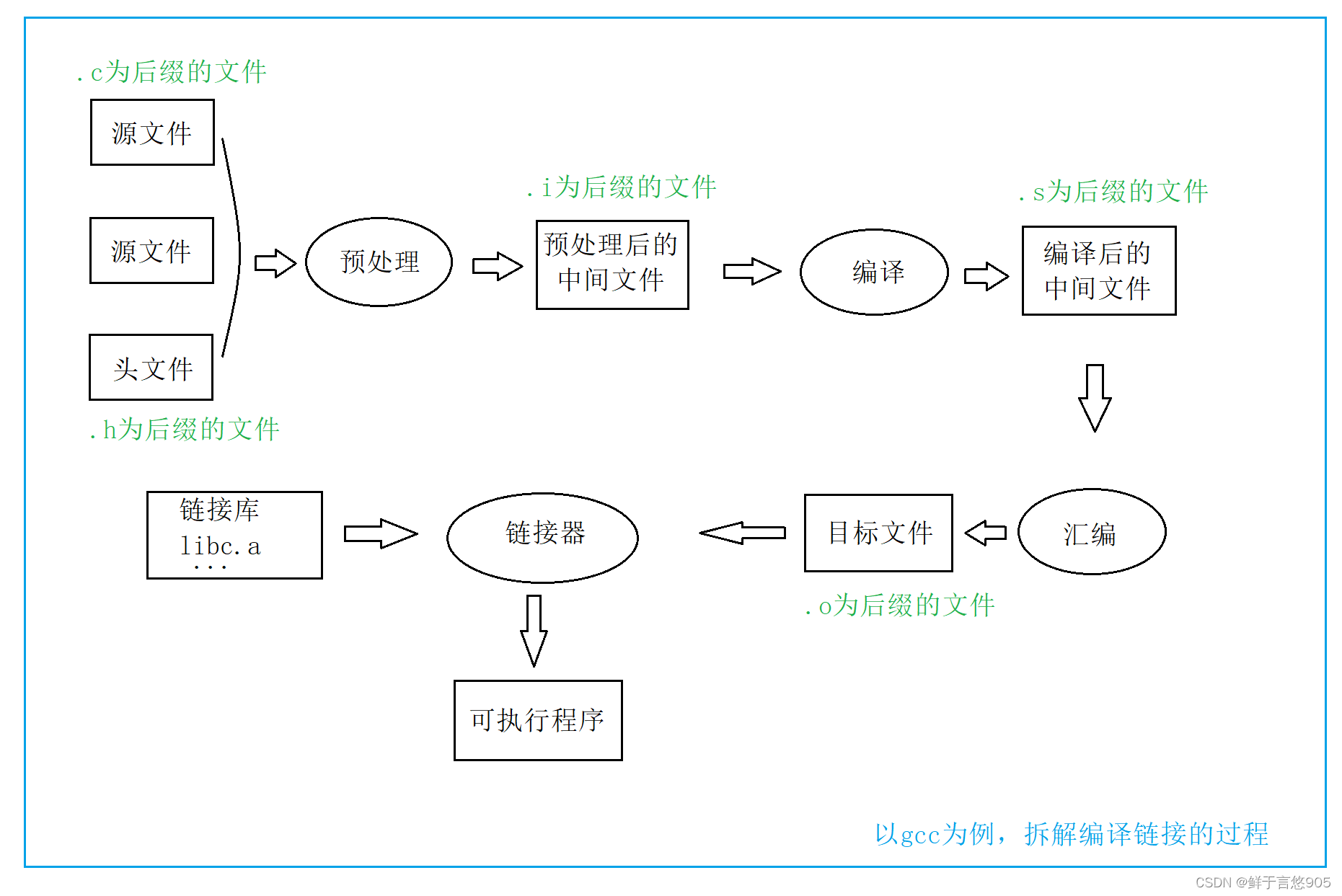
2.1 预处理(预编译)
2.2 编译
2.2.1 词法分析
2.2.2 语法分析
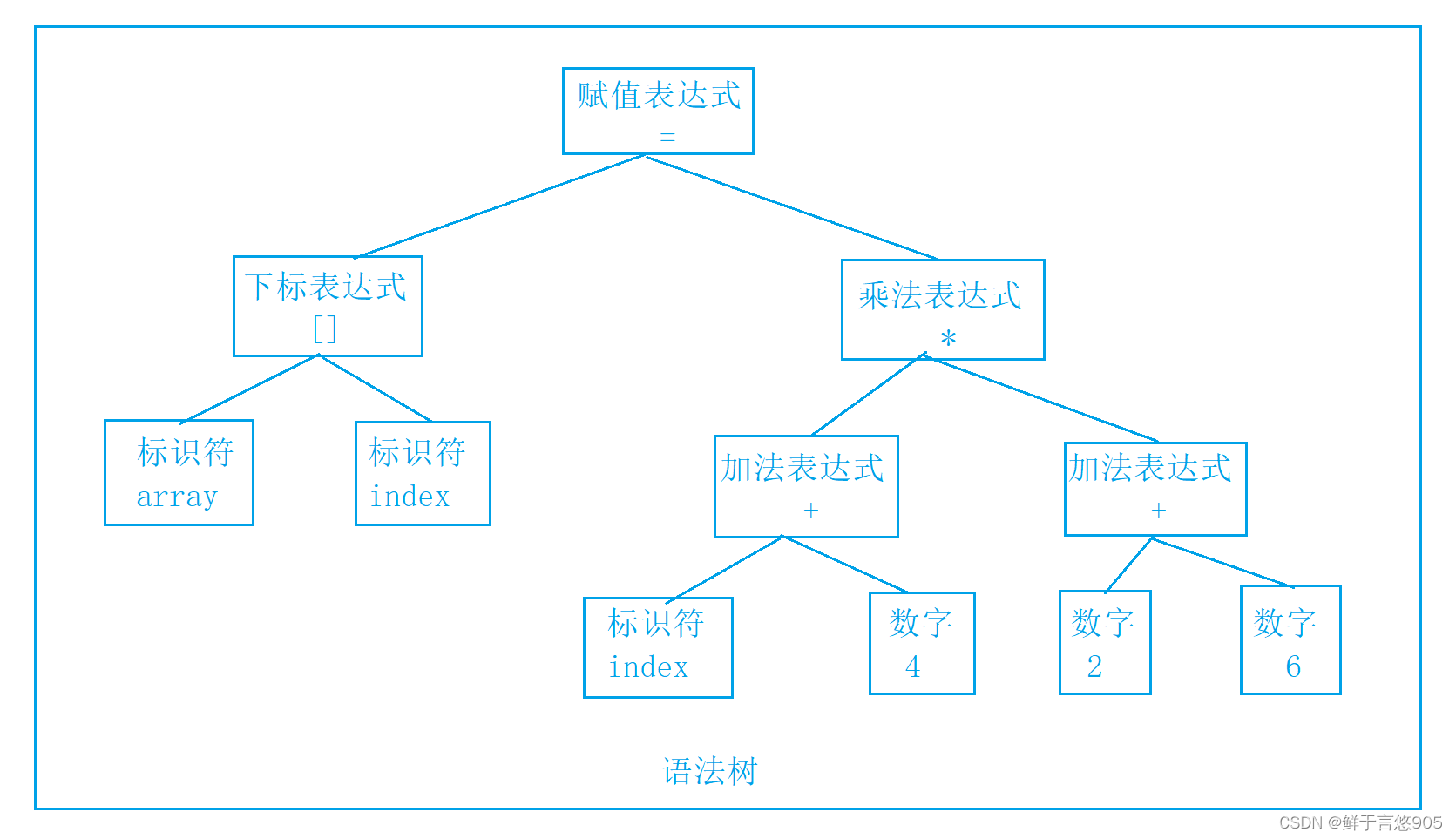
2.2.3 语义分析

2.3 汇编
2.4 链接
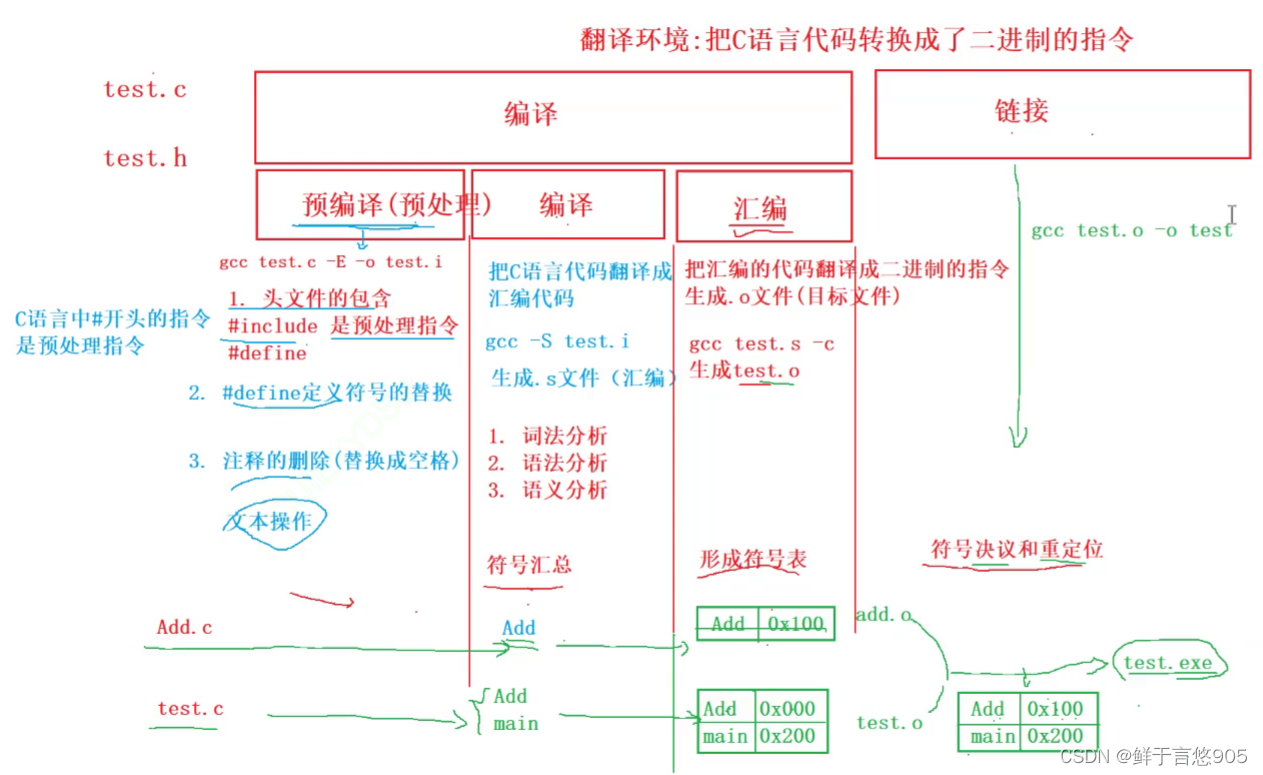
三、 运行环境
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。