本文介绍: 整理和梳理日常hbase的监控核心指标,作为经验沉淀
探讨hbase的监控数据采集方式以及需要关注的核心指标,便于日常生产进行监控和巡检。
1. 监控指标采集
监控指标的采集方式使用promethues + jmx_prometheus_javaagent的方式进行,具体方案部署方案可以参考HDFS监控方法以及核心指标
需要注意的是,调整几个关键配置,
1, 配置master.yaml和regionserver.yaml
root@Master:/usr/local/monitor# cat /usr/local/monitor/master.yaml
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
root@Master:/usr/local/monitor# cat /usr/local/monitor/regionserver.yaml
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
2, 配置hdfs相关的OPTS
vim /usr/local/hbase-2.4.17/conf/hbase-env.sh
# 增加jmx_prometheus_javaagent采集配置
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -javaagent:/usr/local/monitor/jmx_prometheus_javaagent-0.20.0.jar=10000:/usr/local/monitor/master.yaml"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -javaagent:/usr/local/monitor/jmx_prometheus_javaagent-0.20.0.jar=10001:/usr/local/monitor/regionserver.yaml"
3,正常启动hbase
cd /usr/local/hbase-2.4.17/bin
./hbase-daemon.sh start master
./hbase-daemon.sh start regionserver
4, 启动的进程中会携带jmx_prometheus_javaagent参数
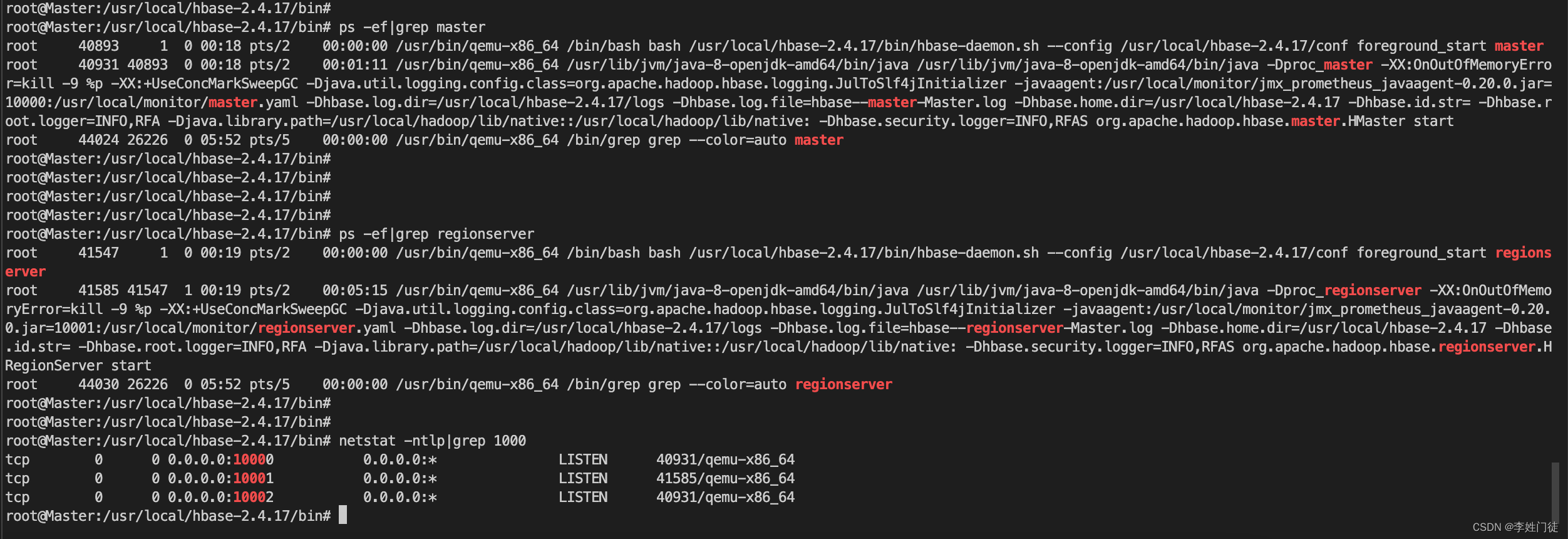
5, 查看相关的指标
# resourcemanager指标
curl localhost:10000/metrics
# nodemanager指标
curl localhost:10001/metrics
配置prometheus等细节,可以参考可以参考HDFS监控方法以及核心指标,本文不再继续赘述。
2. 核心告警指标
2.1 Master核心指标梳理
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| masterStartTime | Master 进程启动时间 | >= 10s | |
| 主备情况 | haState | 1:主,0:备 | 集群必须包含1主1备 |
| numCallsInPriorityQueue | 通用队列 RPC 请求数 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| numCallsInReplicationQueue | 复制队列 RPC 请求数 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| numOpenConnections | 当前打开的连接个数 | <= 1000 | 不宜有太多的链接,涉及性能问题,根据实际情况调整 |
| numDeadRegionServers | 当前Dead的 RegionServer 个数 | <= 0 |
2.2 RegionServer核心指标梳理
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| numCallsInPriorityQueue | 通用队列 RPC 请求数 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| MemHeapUsedM/MemHeapMaxM | Jvmd堆内内存使用率 | <= 60% | |
| AvailableVCores / (AllocatedVCores + AvailableVCores ) | NodeManager 可用的 VCore 占比 | <= 90% | 涉及容量资源,不同环境根据实际情况调整 |
| AvailableGB / (AllocatedGB + AvailableGB ) | NodeManager 可用的 内存 占比 | <= 90% | 涉及容量资源,不同环境根据实际情况调整 |
| BytesWrittenMB | 写入 DN 的字节速率 | 根据机器的网卡带宽调整 | |
| BytesReadMB | 读取 DN 的字节速率 | 根据机器的网卡带宽调整 | |
| VolumeFailures | 磁盘故障次数 | <= 0 | |
| DatanodeNetworkErrors | 网络错误统计 | <= 0 | |
| 磁盘使用率 | <= 70 | ||
| 磁盘await | 磁盘读写的await | <= 1ms |
3. 参考文章
原文地址:https://blog.csdn.net/weixin_43845924/article/details/135672392
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_59908.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。


![[office] excel表格怎么绘制股票的CCI指标- #媒体#学习方法#笔记](https://img-blog.csdnimg.cn/img_convert/605821698ce78ab7688ab84de153cdea.jpeg)