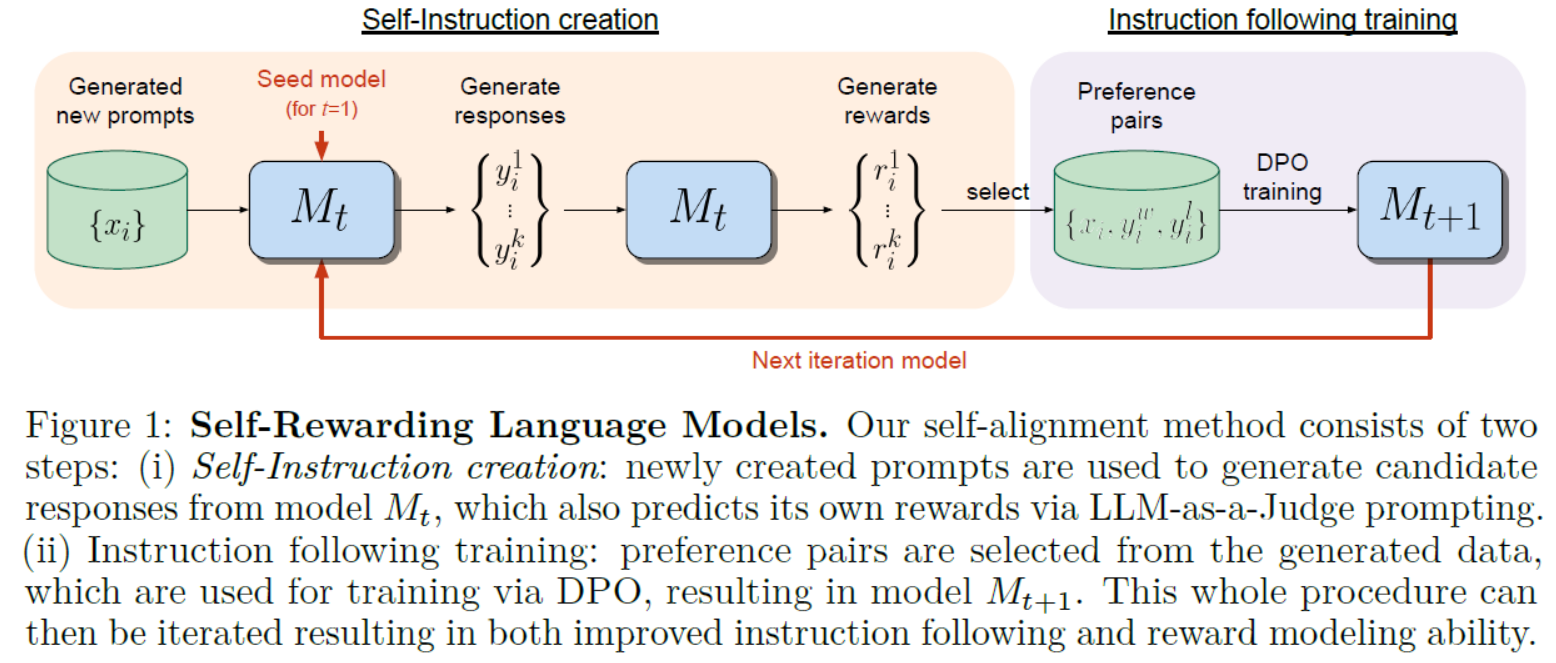
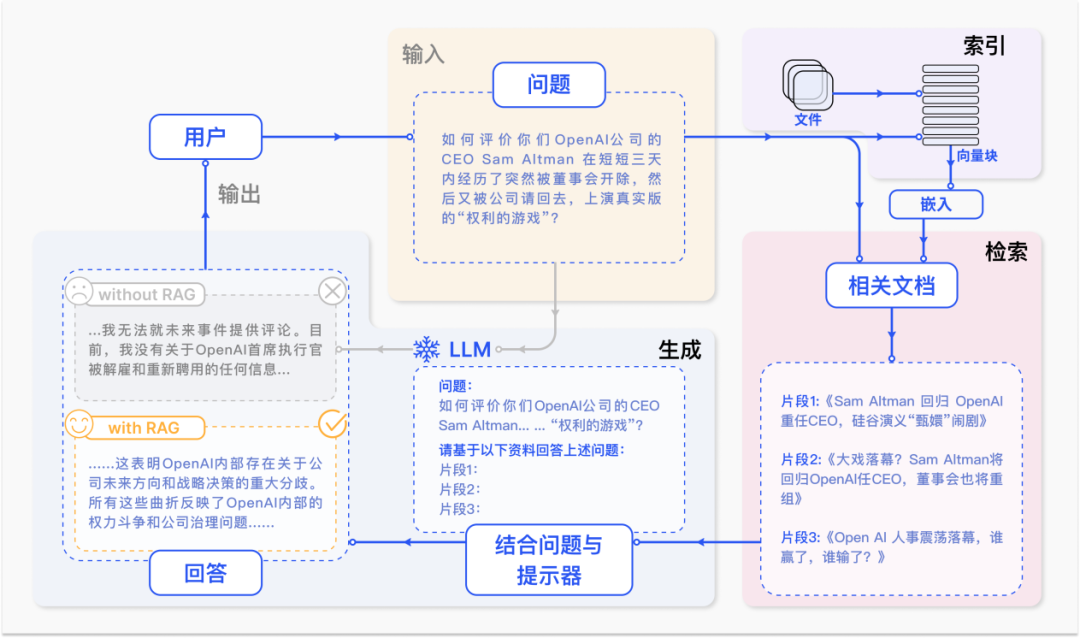
本文介绍: Self-RAG:通过自我反思学习检索、生成和批判。Self-RAG学习检索、生成和批评,以提高 LM 的输出质量和真实性,在六项任务上优于 ChatGPT 和检索增强的 LLama2 Chat。
论文地址:https://arxiv.org/abs/2310.11511
项目主页:https://selfrag.github.io/
Self-RAG学习检索、生成和批评,以提高 LM 的输出质量和真实性,在六项任务上优于 ChatGPT 和检索增强的 LLama2 Chat。
问题:万能LLM错误陈述事实的问题
尽管大型语言模型(LLM)具有非凡的能力,但由于它们完全依赖于它们所封装的参数知识,因此通常会产生包含事实不准确的响应。他们经常产生幻觉,尤其是在长尾方面,他们的知识已经过时,并且缺乏归因。
检索增强是否是银弹
检索增强生成 (RAG) 是一种临时方法,通过检索相关知识来增强 LM,减少此类问题,并在 QA 等知识密集型任务中显示出有效性。然而,不加区别地检索和合并固定数量的检索到的段落,无论检索是否必要,或者段落是否相关,都会降低 LM 的多功能性或可能导致生成无用的响应。此外,并不能保证所引用的证据会影响几代人。
1. 基本思想
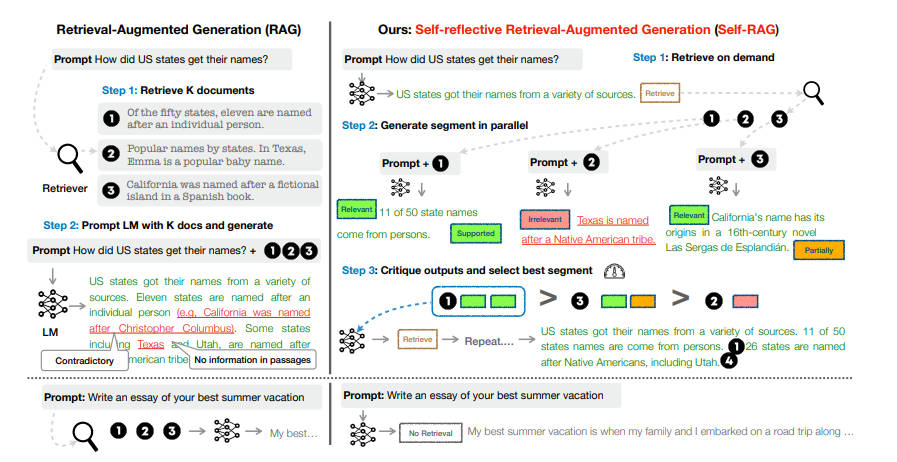

2. 实现详情
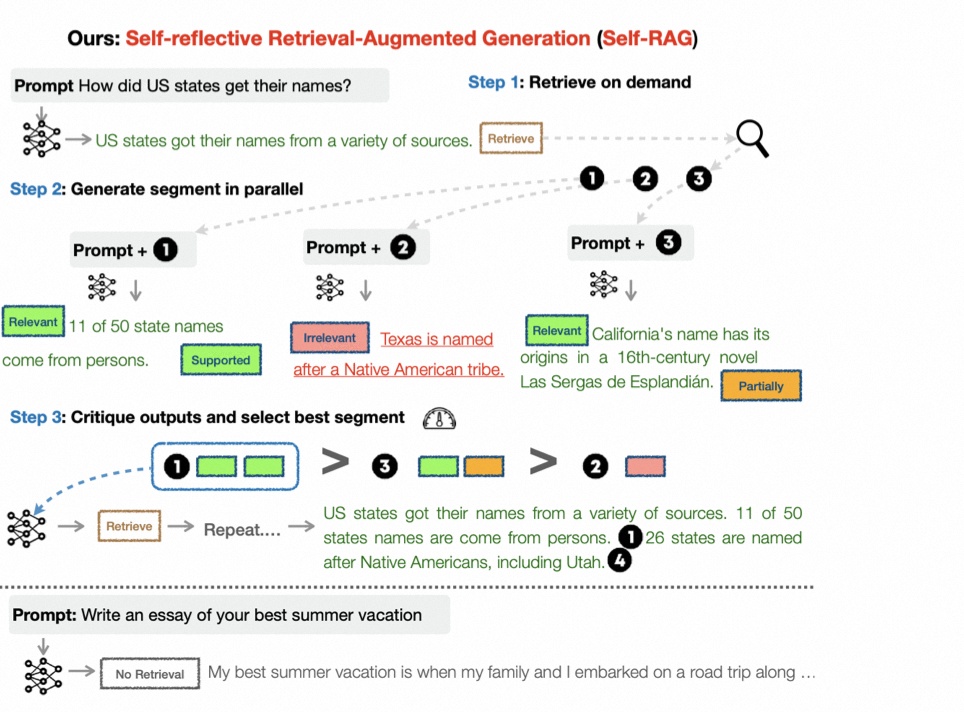

2.1 问题形式化和概述

2.2 训练阶段
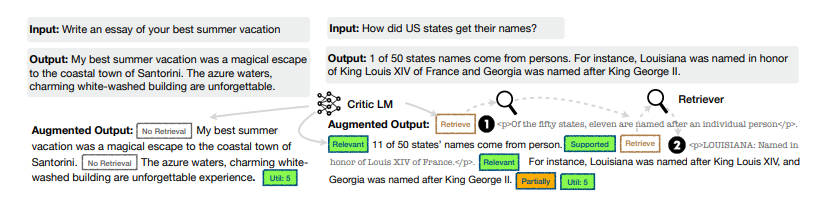
2.2.1 训练批判者模型





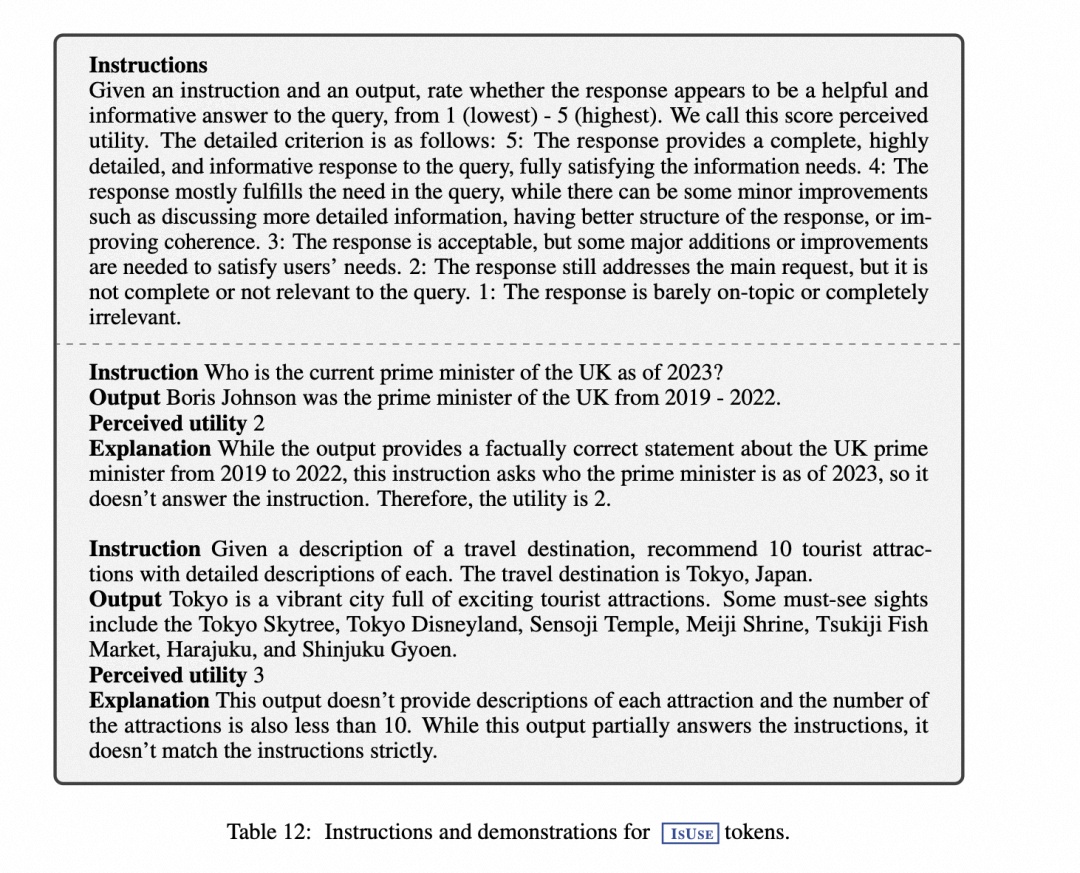
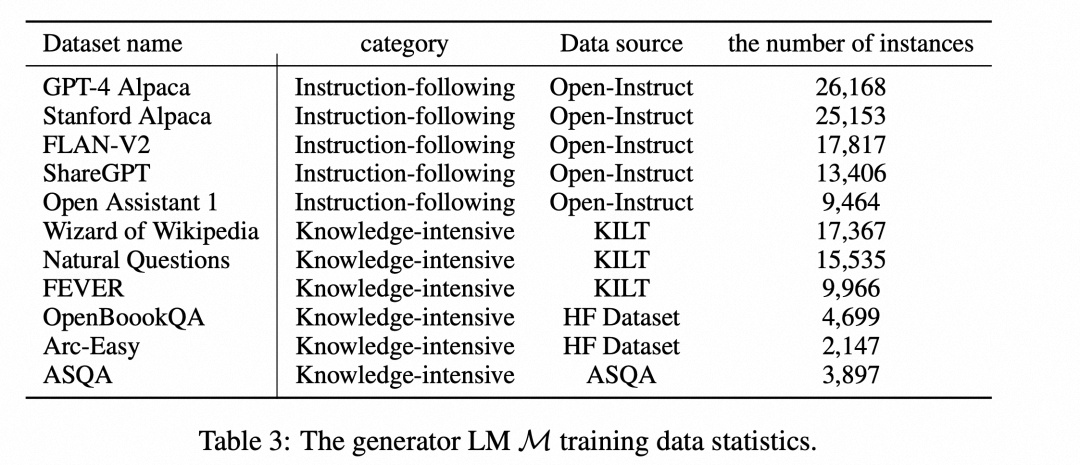

2.2.2 训练生成器模型

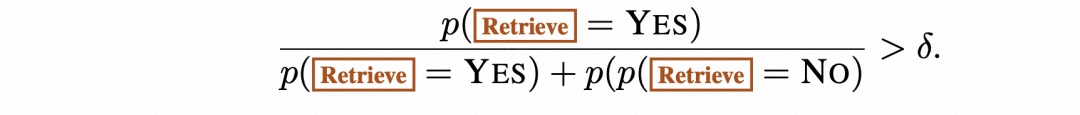
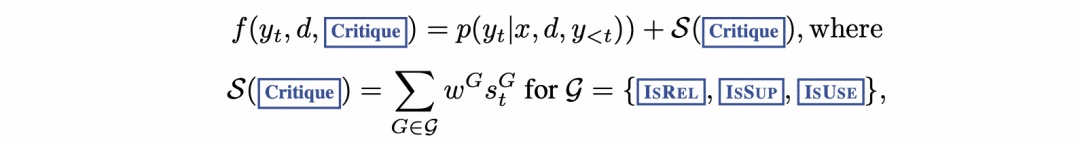
3.实验设置与结果分析
3.1 任务和数据集
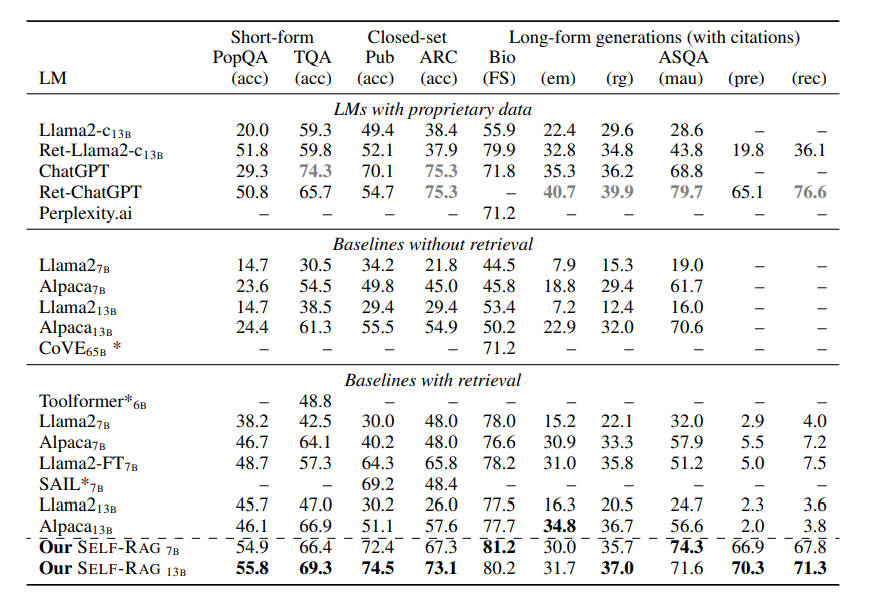
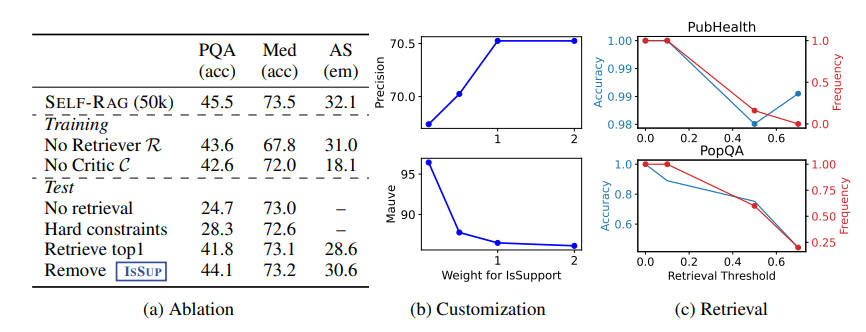
3.2 实验结果

4. 总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。