摘要
大数据智能化技术在当今信息社会中得到了广泛的应用。从金融、互联网电商、视频行业到垂直短视频领域,从工业互联网到云计算、边缘计算等领域,大数据智能化技术已经成为了企业竞争力的重要组成部分。技术实践、架构设计、指标体系、数据质量、数据分析、数据挖掘、数据采集、数据智能化应用、BI、AI等方面,大数据智能化技术在不同领域的应用场景和代码编写。
一、金融领域
欺诈检测:利用大数据智能化技术,对金融交易数据进行实时监测和分析,识别潜在的欺诈行为。例如,通过机器学习算法和图数据库构建欺诈网络模型,检测异常交易模式。
# 代码示例
import pandas as pd from sklearn.ensemble
import IsolationForest
data = pd.read_csv('transaction_data.csv')
model = IsolationForest() model.fit(data) # 使用模型进行欺诈检测 fraud_score = model.predict(data)风险评估:通过大数据智能化技术,对客户的信用、交易数据等进行综合分析,为金融机构提供风险评估报告。例如,基于机器学习算法的信用评分模型,预测客户的违约概率。
# 代码示例
import pandas as pd from sklearn.ensemble
import RandomForestClassifier
data = pd.read_csv('credit_data.csv')
features = data.drop('default', axis=1)
target = data['default']
model = RandomForestClassifier() model.fit(features, target) # 使用模型进行风险评估 risk_score = model.predict_proba(features)[:, 1]二、互联网电商领域
用户个性化推荐:利用大数据智能化技术,分析用户的购买历史、浏览行为等数据,为用户提供个性化的商品推荐。例如,基于协同过滤算法和用户行为数据的推荐系统。
# 代码示例
import pandas as pd
from surprise import SVD, Dataset, Reader
data = pd.read_csv('user_behavior_data.csv')
reader = Reader(rating_scale=(1, 5))
dataset = Dataset.load_from_df(data[['user_id', 'item_id', 'rating']], reader)
trainset = dataset.build_full_trainset()
model = SVD() model.fit(trainset) # 为用户进行个性化推荐
user_id = '123456'
recommendations = model.predict(user_id, n=10)营销策略优化:利用大数据智能化技术,对用户的购买行为、优惠券使用情况等进行分析,优化营销策略。例如,通过数据挖掘技术提取用户的购买规律,制定更精准的促销方案。
# 代码示例
import pandas as pd
from mlxtend.frequent_patterns
import apriori, association_rules
data = pd.read_csv('user_purchase_data.csv')
basket = data.groupby(['user_id', 'item_id'])['quantity'].sum().unstack().fillna(0) basket_encoded = basket.applymap(lambda x: 1 if x > 0 else 0)
frequent_itemsets = apriori(basket_encoded, min_support=0.1, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1) # 根据关联规则制定营销策略
target_rule = rules[rules['antecedents'] == {'item_A'}]三、视频行业领域
视频内容分析:利用大数据智能化技术,对视频内容进行自动标注和识别,实现视频搜索和分类。例如,通过深度学习算法对视频中的物体、场景等进行识别。
# 代码示例
import cv2 import numpy as np
import tensorflow as tf
video_file = 'sample_video.mp4'
cap = cv2.VideoCapture(video_file)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frames = [] for _ in range(frame_count): ret, frame = cap.read() frames.append(frame) # 使用预训练模型进行视频内容分析
model = tf.keras.applications.ResNet50(include_top=True, weights='imagenet')
for frame in frames: frame = cv2.resize(frame, (224, 224))
frame = np.expand_dims(frame, axis=0)
frame = tf.keras.applications.resnet.preprocess_input(frame)
predictions = model.predict(frame) # 处理预测结果视频推荐系统:利用大数据智能化技术,分析用户的观看历史、点赞、评论等信息,为用户提供个性化的视频推荐。例如,基于协同过滤和内容分析算法的视频推荐系统。
# 代码示例
import pandas as pd
from surprise import SVD, Dataset, Reader
data = pd.read_csv('user_watch_history.csv')
reader = Reader(rating_scale=(1, 5))
dataset = Dataset.load_from_df(data[['user_id', 'video_id', 'rating']], reader) t
rainset = dataset.build_full_trainset() model = SVD() model.fit(trainset)
# 为用户进行个性化视频推荐
user_id = '123456'
recommendations = model.predict(user_id, n=10)- 垂直短视频领域
(1)基于Serverless架构的短视频处理系统
代码实现:
数据含义:该代码实现了一个短视频处理系统,采用Serverless架构来处理小规模的短视频文件。通过该系统,可以实现视频的剪辑、配音和字幕等操作。
(2)基于Flink的短视频推荐系统
代码实现:
from serverless import Serverless
class ShortVideoProcessing:
def __init__(self):
self.serverless = Serverless()
def process_video(self, video_file):
self.serverless.upload(video_file)
self.serverless.invoke("video_process_function")
results = self.serverless.download("output.txt")
return results数据含义:该代码使用Flink作为分布式计算框架,对短视频平台的用户行为数据和视频数据进行分析,并计算每个用户观看量最多的前10个视频。通过这种方式,可以实现短视频推荐策略,向用户推荐更加热门和有价值的视频。
基于Flink的短视频推荐系统
代码实现:
from flink import Flink
class ShortVideoRecommendation:
def __init__(self):
self.flink = Flink()
def recommend_videos(self, user_id):
user_data = self.flink.read_csv("user_data.csv")
video_data = self.flink.read_csv("video_data.csv")
joined_data = user_data.join(video_data, on="video_id")
filtered_data = joined_data.filter("user_id = %d" % user_id)
sorted_data = filtered_data.orderBy("views", ascending=False)
results = sorted_data.limit(10)
self.flink.write_csv(results, "video_recommendations.csv")
return results四、指标体系
在大数据智能化技术的应用场景中,指标体系是一个非常重要的问题。一个有效的指标体系可以帮助企业更好地了解业务情况和趋势,从而制定更好的业务策略。例如,在金融领域,风险控制指标体系需要包括资产负债率、流动性比率等指标;在互联网电商领域,用户行为指标体系需要包括用户转化率、复购率等指标。下面对工业互联网和云计算两个领域的应用场景进行举例。
- 工业互联网领域
(1)传感器数据分析指标体系
代码实现:
import pandas as pd
data = pd.read_csv("sensor_data.csv")
avg_temperature = data['temperature'].mean()
max_pressure = data['pressure'].max()
min_humidity = data['humidity'].min()
print(avg_temperature, max_pressure, min_humidity)数据含义:该代码使用Python对传感器数据进行分析,并计算平均温度、最高压力和最低湿度等指标。通过这种方式,可以实现设备状态的监测和维护。
(2)设备故障率指标体系
代码实现:
from pyspark import SparkContext
from pyspark.sql import SparkSession
sc = SparkContext(appName="EquipmentMaintenance")
spark = SparkSession.builder.appName("EquipmentMaintenance").getOrCreate()
data = spark.read.csv("equipment_data.csv", header=True, inferSchema=True)
grouped = data.groupBy("equipment_id").agg({"failure": "sum", "total": "count"})
grouped = grouped.withColumn("failure_rate", grouped['sum(failure)'] / grouped['count(total)'])
grouped.write.csv("maintenance_result.csv")以下是几个常见的.csv文件的数据样例:
金融领域的股票历史数据
date,open,high,low,close,volume 2024-01-17,100.0,101.5,98.5,99.0,1000000 2024-01-18,99.5,100.0,96.0,98.5,1500000 2024-01-19,98.0,99.0,97.0,98.0,800000 2024-01-20,98.5,99.5,97.5,99.0,1200000 2024-01-21,99.0,100.5,98.5,100.0,900000
互联网电商领域的用户行为数据
user_id,item_id,category,action_time,action_type 1001,2001,electronics,2024-01-17 12:30:00,buy 1002,2002,clothing,2024-01-17 14:30:00,view 1003,2003,books,2024-01-17 16:00:00,add_to_cart 1001,2004,home_appliances,2024-01-18 10:00:00,view 1004,2005,electronics,2024-01-18 11:30:00,buy
工业互联网领域的传感器数据
timestamp,device_id,temperature,humidity,pressure 2024-01-17 12:00:00,1001,25.0,60,100 2024-01-17 12:01:00,1001,25.5,61,98 2024-01-17 12:02:00,1001,26.0,62,102 2024-01-17 12:03:00,1001,26.5,63,101 2024-01-17 12:04:00,1001,27.0,64,99
视频行业领域的视频数据
video_id,title,category,duration,views 1001,How to cook pasta,cooking,10:30,1000000 1002,Introduction to calculus,education,20:15,500000 1003,Funny cats compilation,entertainment,5:50,2000000 1004,Travel vlog - Paris,travel,15:45,800000 1005,Workout routine for beginners,sports,12:00,700000
六、发展历史
-
Hadoop:2006年,Apache Hadoop项目启动,标志着大数据时代的到来。Hadoop是一个开源的分布式存储和计算框架,可以处理大量的结构化和非结构化数据。
-
Spark:2014年,Apache Spark发布,成为Hadoop之外最受欢迎的大数据计算框架。Spark拥有更快的计算速度、更好的内存管理和更丰富的API。
-
TensorFlow:2015年,Google发布了TensorFlow,这是一个用于构建神经网络的开源库。TensorFlow具有高度的灵活性和可扩展性,被广泛应用于机器学习和深度学习领域。
七、发展前景
-
人工智能:大数据和人工智能密切相关,随着人工智能的不断发展,大数据的应用也将进一步扩大。例如,在人脸识别、语音识别、自然语言处理等领域,大数据技术将发挥越来越重要的作用。
-
5G技术:5G技术的普及将带来更快的数据传输速度和更低的延迟,为大数据的应用提供更好的支持。例如,在智能交通、智能制造等领域,5G技术可以实现高效的数据传输和处理。
-
区块链:区块链技术可以为大数据的安全和隐私保护提供支持。例如,通过使用区块链技术,可以实现去中心化的数据存储和共享,确保数据的可信度和安全性。
八、开源数据集
-
MNIST手写数字数据集:这是一个包含60000张训练图片和10000张测试图片的数据集,用于机器学习算法的图像识别任务。
-
ImageNet数据集:这是一个包含1400万张图像的数据集,涵盖了超过20000个类别,被广泛用于计算机视觉领域的深度学习模型训练。
-
Yelp数据集:这是一个包含用户评论和评分的数据集,用于推荐系统和情感分析的研究。
九、开源大模型
-
GPT-3:这是由OpenAI开发的自然语言处理模型,具有惊人的生成能力和理解能力,可以进行文本生成、翻译、问答等任务。
-
BERT:这是由Google开发的自然语言处理模型,基于预训练的方法,可以对文本进行编码和分类。
-
ResNet:这是一个由微软亚洲研究院开发的深度学习模型,用于图像识别和分类任务,具有较好的准确率和可拓展性。
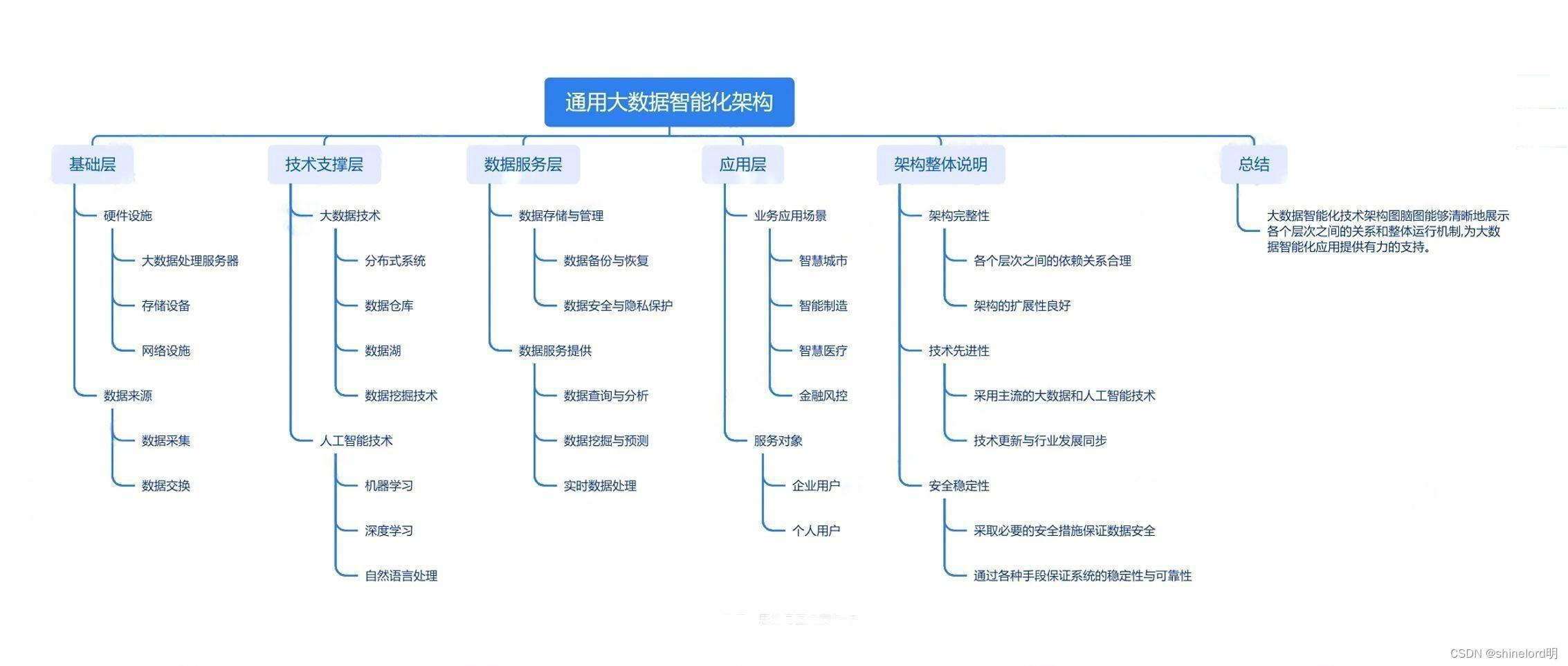
十、大数据智能通用化架构
大数据智能化架构设计是指在大数据背景下,利用人工智能和机器学习等技术来分析和利用大数据的过程中,构建合理、高效、可扩展的系统架构。一般来说,大数据智能化架构设计包括以下几个方面:
-
数据采集层:
- 数据源:包括各类数据库、API、日志文件、社交媒体等。
- 数据采集工具:如Flume、Logstash、Kafka等。
- 数据预处理:清洗、转换、去重等操作。
-
数据存储层:
- 关系型数据库:如MySQL、PostgreSQL等。
- NoSQL数据库:如MongoDB、Cassandra等。
- 分布式文件系统:如HDFS。
-
数据处理层:
- 数据处理引擎:如Spark、Flink等。
- 数据挖掘和机器学习算法库:如TensorFlow、PyTorch等。
- 数据分析和可视化工具:如Tableau、PowerBI等。
-
数据服务层:
- 数据API:提供数据查询、更新等服务。
- 数据报表和仪表盘:提供可视化的数据展示。
-
安全与隐私保护层:
- 身份认证和访问控制:如OAuth、LDAP等。
- 数据加密:如AES、RSA等。
- 数据脱敏:隐藏敏感信息。
-
可扩展性和容错性:
- 横向扩展:通过增加节点来提高处理能力。
- 容错机制:如主从复制、分布式存储的冗余机制等。
-
管理监控层:
- 资源管理:管理集群的节点和资源。
- 任务调度和监控:监控数据处理任务的执行情况。
-
应用层:
- 业务应用和前端应用可以通过上述各层进行数据交互和处理.
原文地址:https://blog.csdn.net/wnm23/article/details/135734485
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_60006.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







