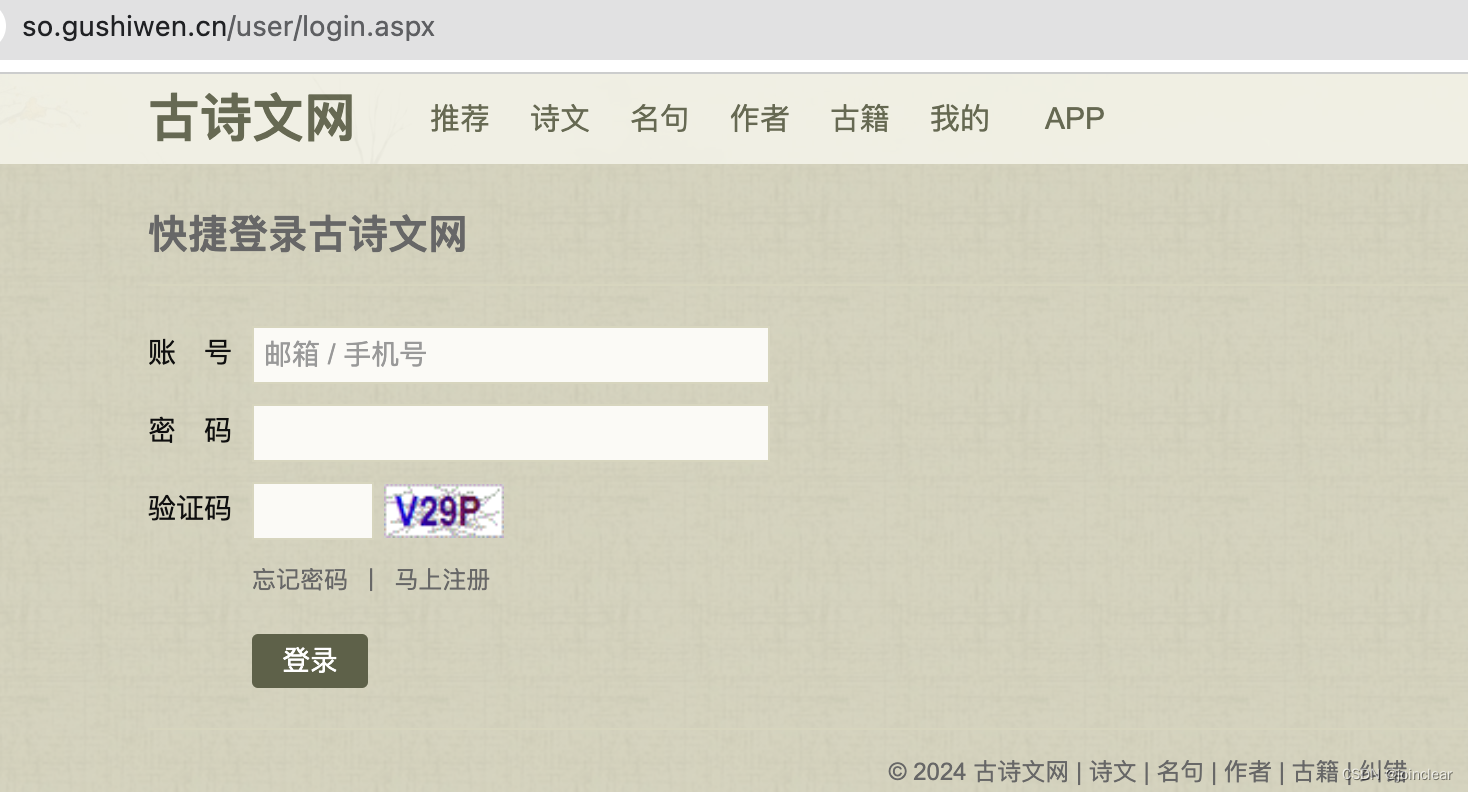
需求:登录古诗文网站,账号+密码+图形验证码
第一:自己注册一个账号+密码哈
第二:图形验证码,需要一个打码平台(充钱,超能力power!)或者tesseract开源包,这两个用于自动识别图形验证码哈~
我用的是超级鹰,充了1块,有1000积分,一次10积分,初学者福音hhhhh
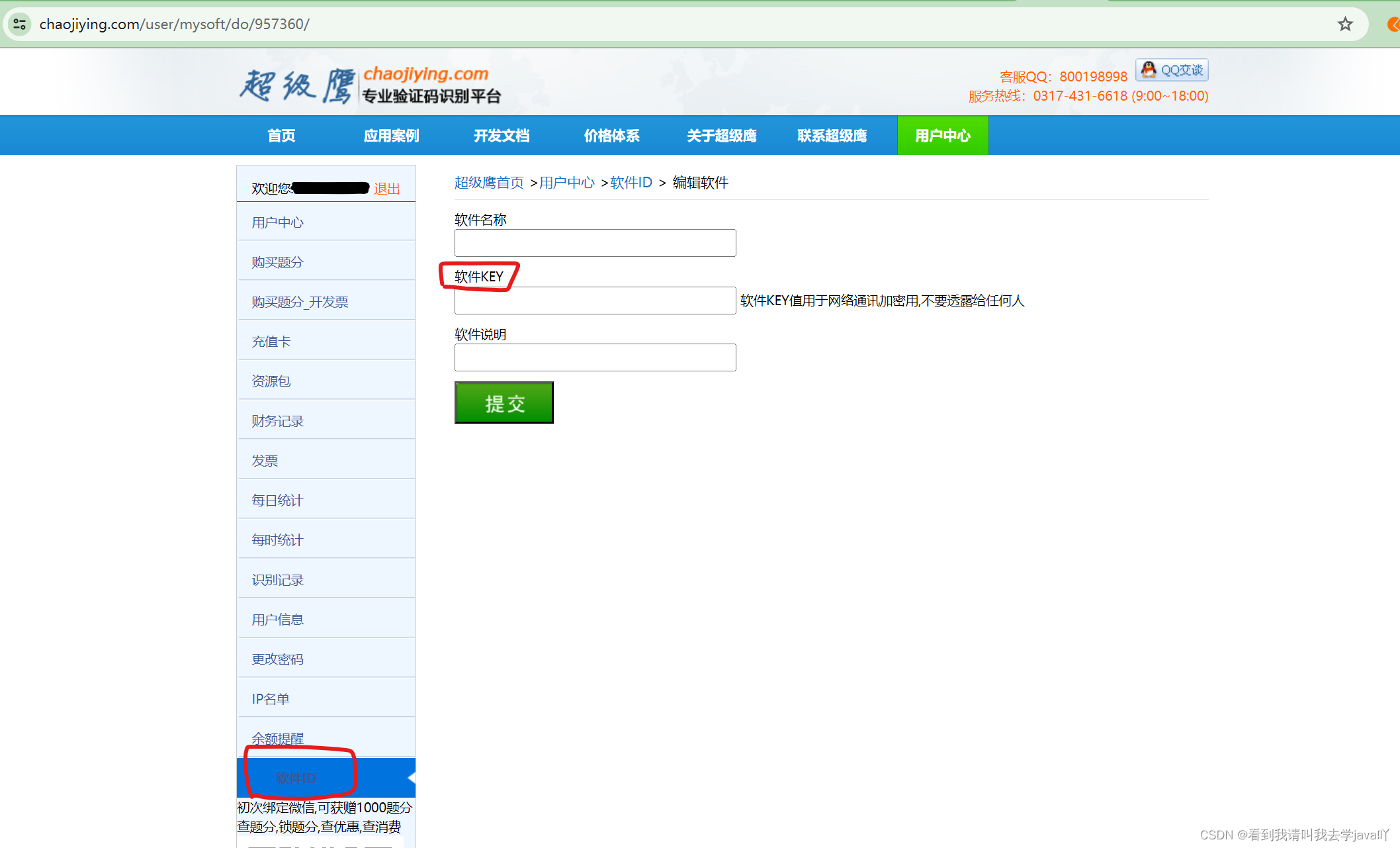
在软件ID随便填一下软件名称和说明,获取软件key
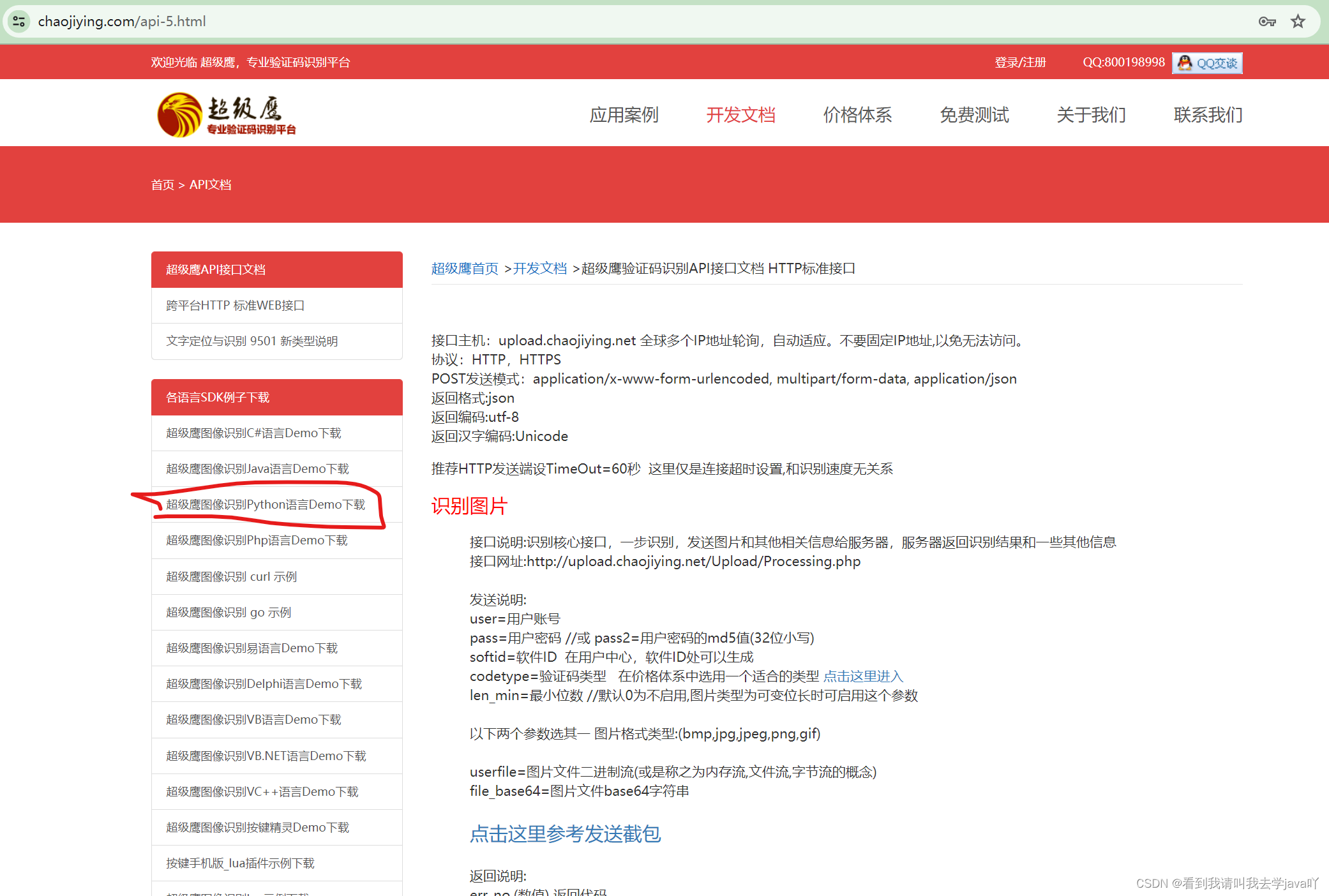
然后点击首页,首页的菜单栏处有个开发文档,来到这个页面,然后找到python的Demo,get一个压缩包~
压缩包里有一个chaojiying.py,把它复制到自己的项目里~
第三:开始码
1. 调用chaojiying.py
把Chaojiying_Client中的三个参数替换成自己的即可,其中filePath是后续保存下来的验证码图片的路径~
2. 获取验证码(还没到登录那一步哈)
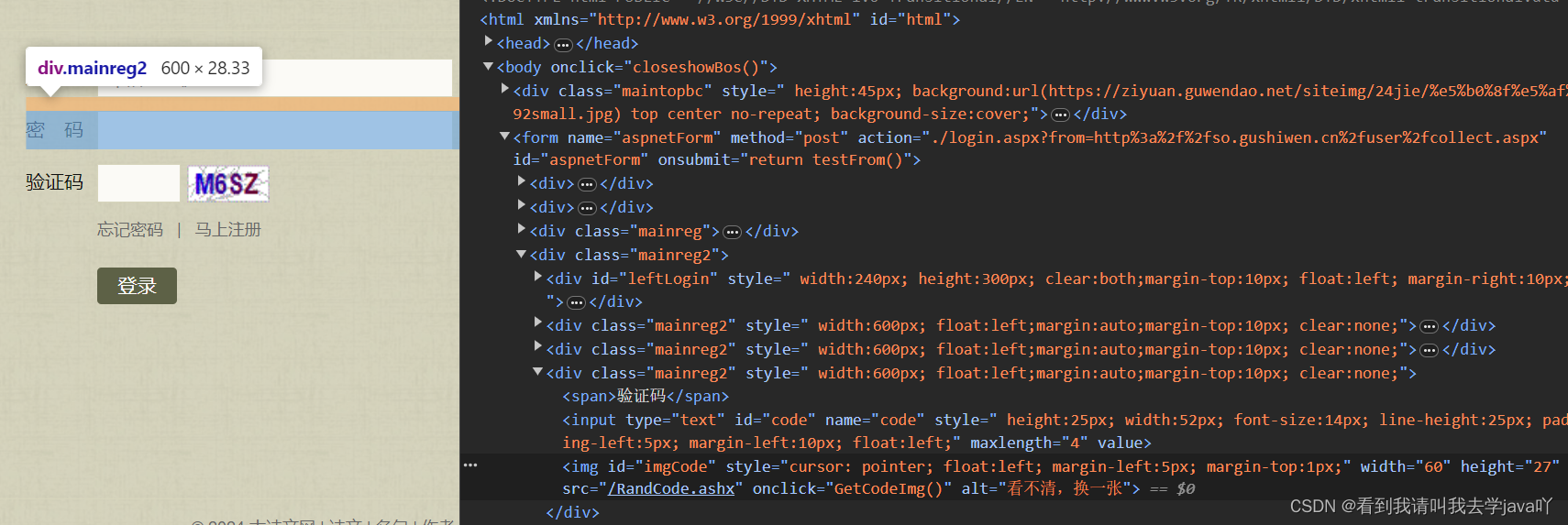
在浏览器按下F12,可以看到页面的源码信息,找到验证码对应的盒子,可以看到其src属性。<img>标签右键,copy->copy xpath即可得到验证码路径,拼接在官网地址后就是代码中的img_src啦
至于xpath是啥,其实还没有学到那里,当当好在学习xpath的时候突然想打通一套登录流程,但大概理解xpath就是可以动态获取某个标签或元素属性的东西叭(超小声)
3. 实战登录
在官网登录之后,打开开发者工具f12,找到如图所示的Payload,这就是访问登陆后的页面时的请求参数,共7个,其中只有__VIEWSTATE、__VIEWSTATEGENERATOR和code是动态变化的(碎碎念,一开始不知道__VIEWSTATE和__VIEWSTATEGENERATOR是啥,导致发送请求,一直提示错误,大哭出声)
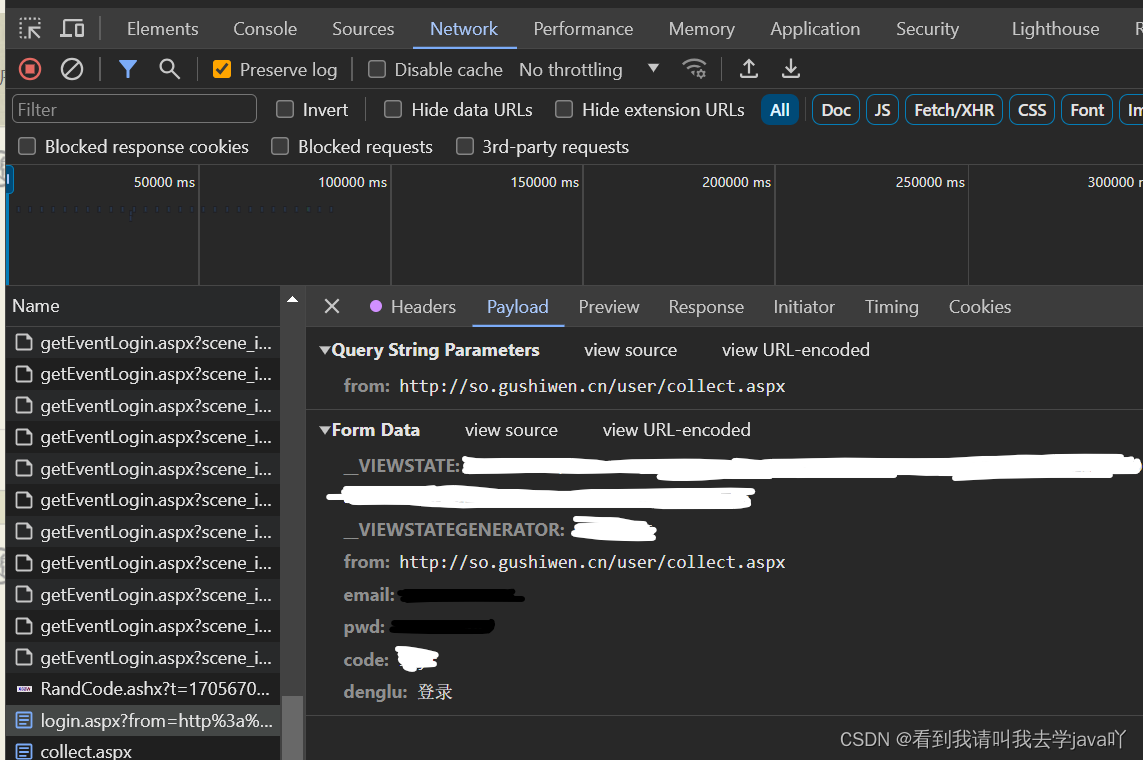
现在code已经有了,那__VIEWSTATE和__VIEWSTATEGENERATOR咋获取嘞
老规矩,获取这两玩应的xpath路径
还是,在源代码中找到这两,然后右键copy->copy xpath
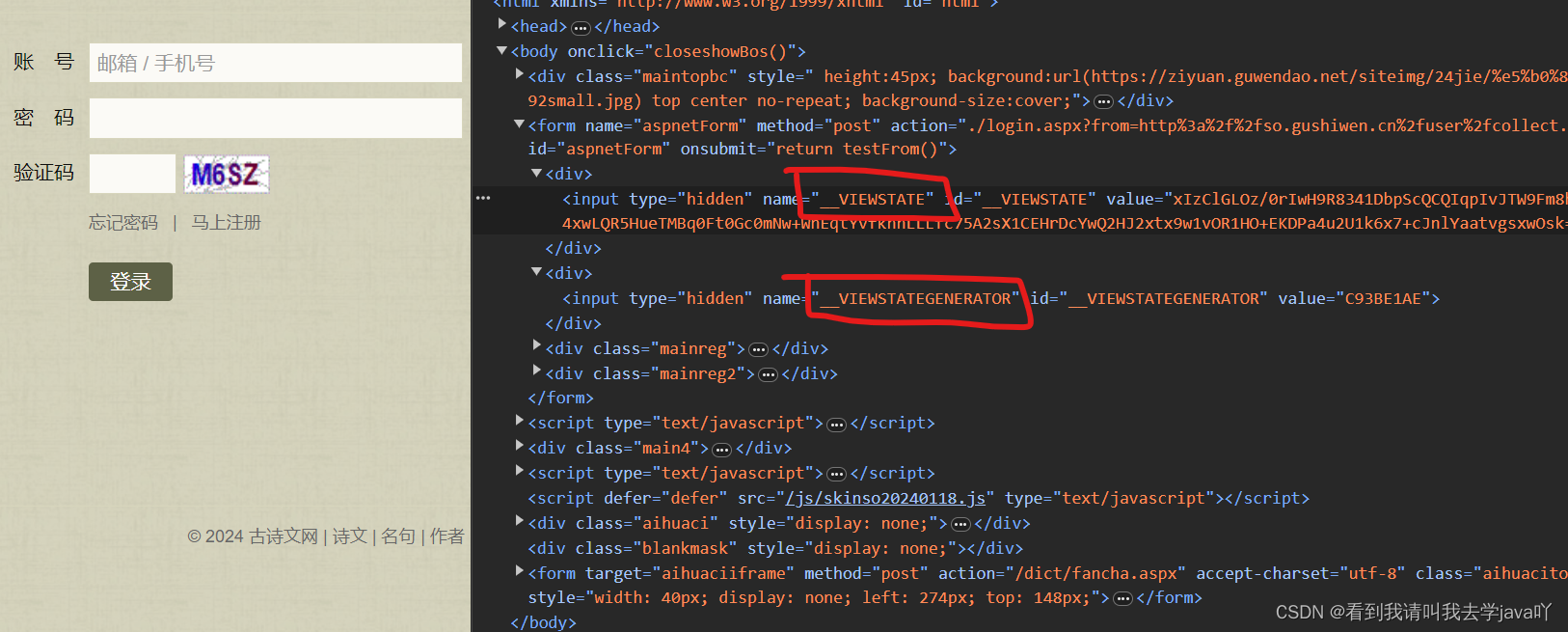
完整代码如下:
总结:生活越来越有判头了nie