一.雪崩问题及解决方案
1.雪崩问题–一个服务阻塞引起其他服务阻塞,造成越来越多的服务阻塞不可用
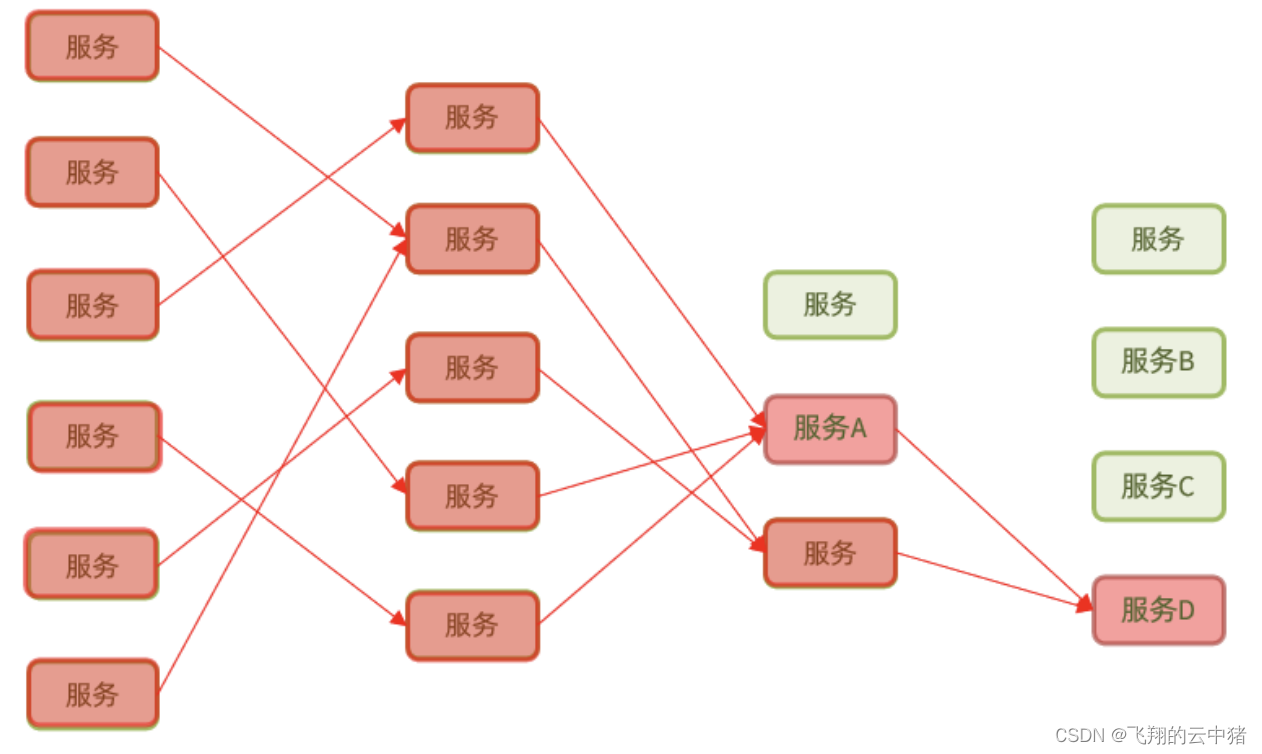
微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。
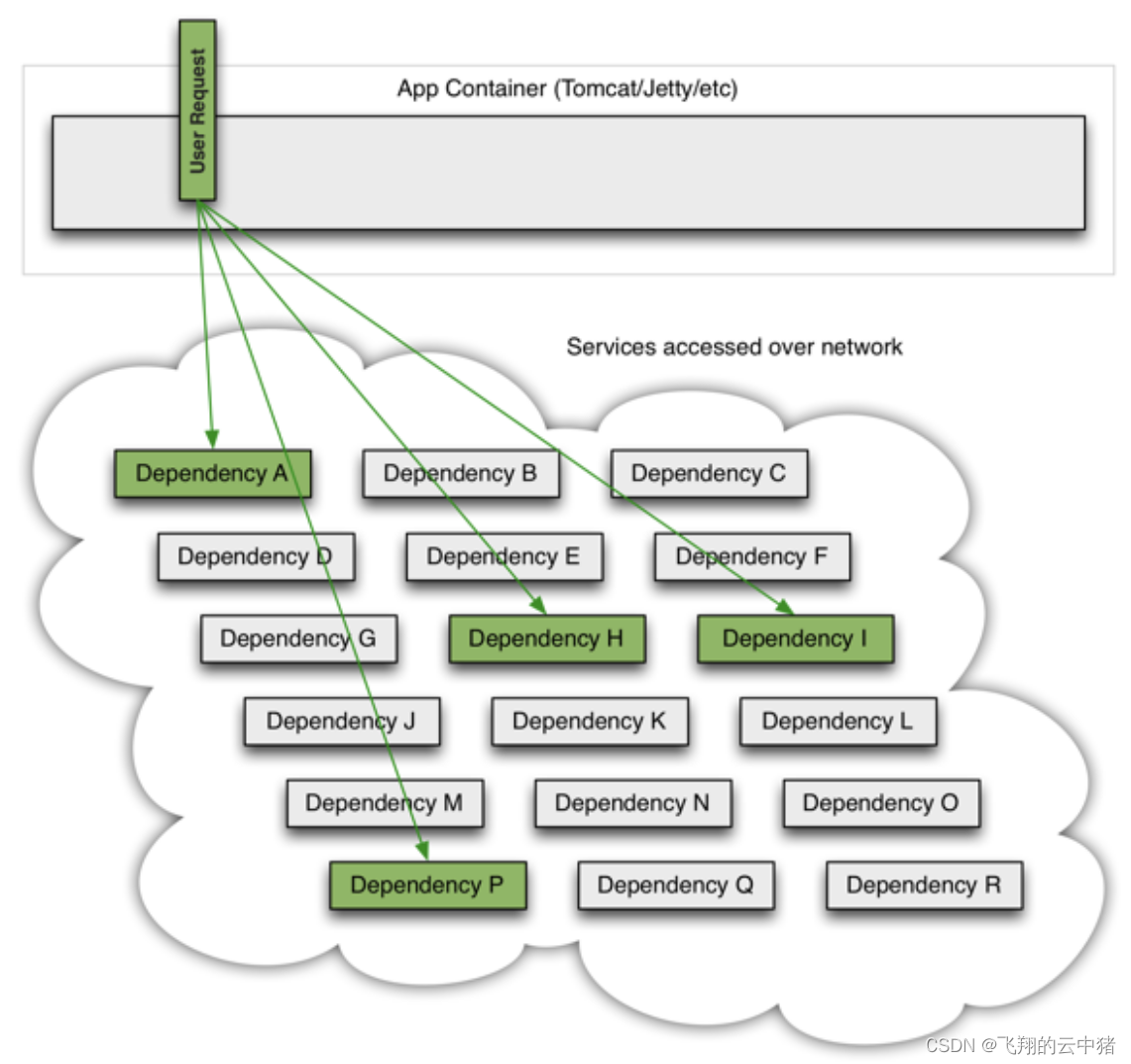
如图,如果服务提供者I发生了故障阻塞,当前的应用的部分业务因为依赖于服务I,因此也会被阻塞。此时,其它不依赖于服务I的业务似乎不受影响。

业务请求发生阻塞的原因有很多:
1.网络延迟:当客户端与服务端之间的网络延迟过高时,会导致请求阻塞。例如,当客户端等待从服务端获取响应时,如果网络延迟很高,则客户端将一直等待,直到超时或收到响应为止。
2.数据库操作:当业务请求需要对数据库进行读写操作时,如果数据库连接池中的连接被占满,就会导致请求阻塞,因为没有可用的连接来执行请求。
3.锁:当多个业务请求需要同时访问同一个资源时,例如同一个文件、同一个缓存或同一个数据库表,可能会出现锁竞争,导致请求阻塞。
4.过度消耗资源:当业务请求需要大量的计算或者消耗大量的内存或CPU资源时,系统可能无法及时响应其他请求,导致请求阻塞。
5.队列溢出:当业务请求的处理速度低于请求的到达速度时,请求队列可能会积累过多的请求,导致队列溢出,从而导致请求阻塞。
6.外部依赖:当业务请求依赖于其他服务或第三方库时,如果这些服务或库出现故障或响应缓慢,就会导致请求阻塞,直到这些服务或库返回响应为止。
但是,依赖服务I的业务请求被阻塞,用户不会得到响应,则tomcat的这个线程不会释放,于是越来越多的用户请求到来,越来越多的线程会阻塞:

服务器支持的线程和并发数有限,请求一直阻塞,会导致服务器资源耗尽,从而导致所有其它服务都不可用,那么当前服务也就不可用了。那么,依赖于当前服务的其它服务随着时间的推移,最终也都会变的不可用,形成级联失败,雪崩就发生了:
2.解决方法
解决雪崩问题的常见方式有四种:
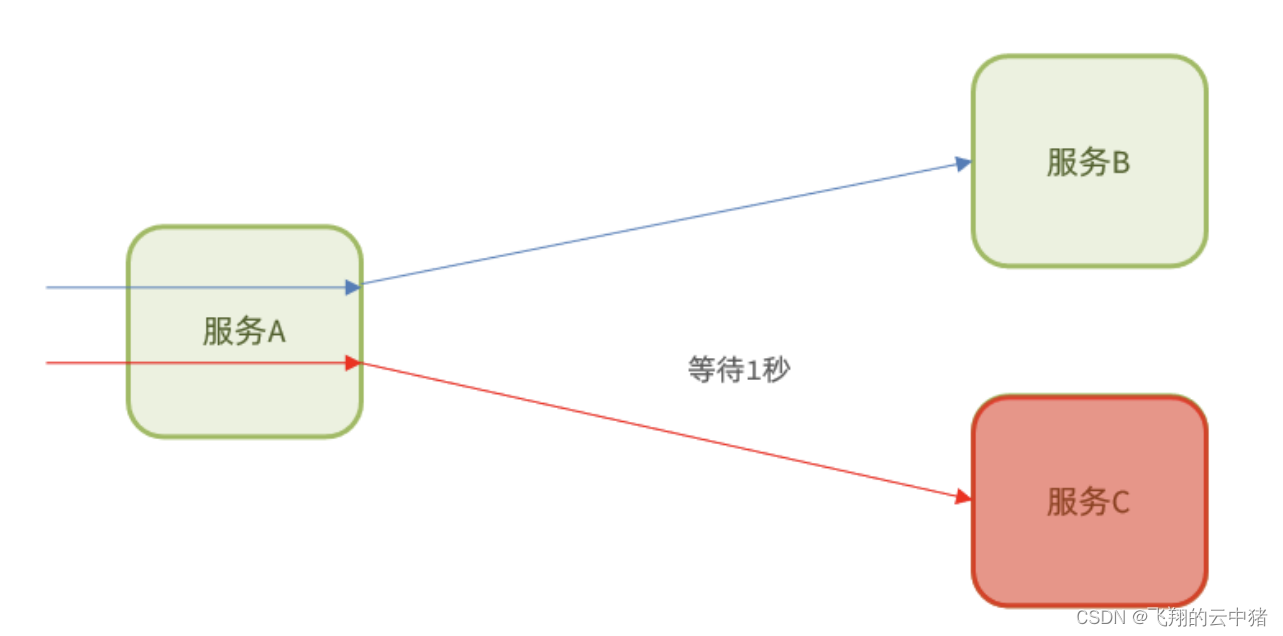
【1】超时处理–超出时间返回错误信息
设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待
【2】线程隔离/仓壁模式–限制服务中每个业务能拥有的线程数
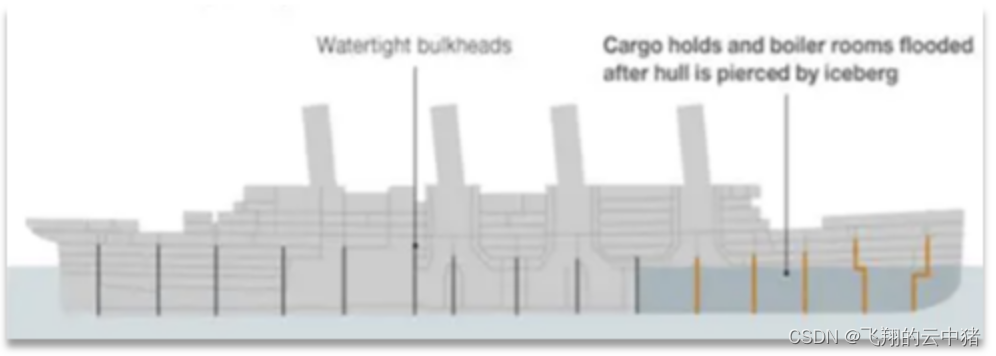
仓壁模式来源于船舱的设计:
船舱都会被隔板分离为多个独立空间,当船体破损时,只会导致部分空间进入,将故障控制在一定范围内,避免整个船体都被淹没。
调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽 ,避免耗尽整个tomcat的资源,因此也叫线程隔离。

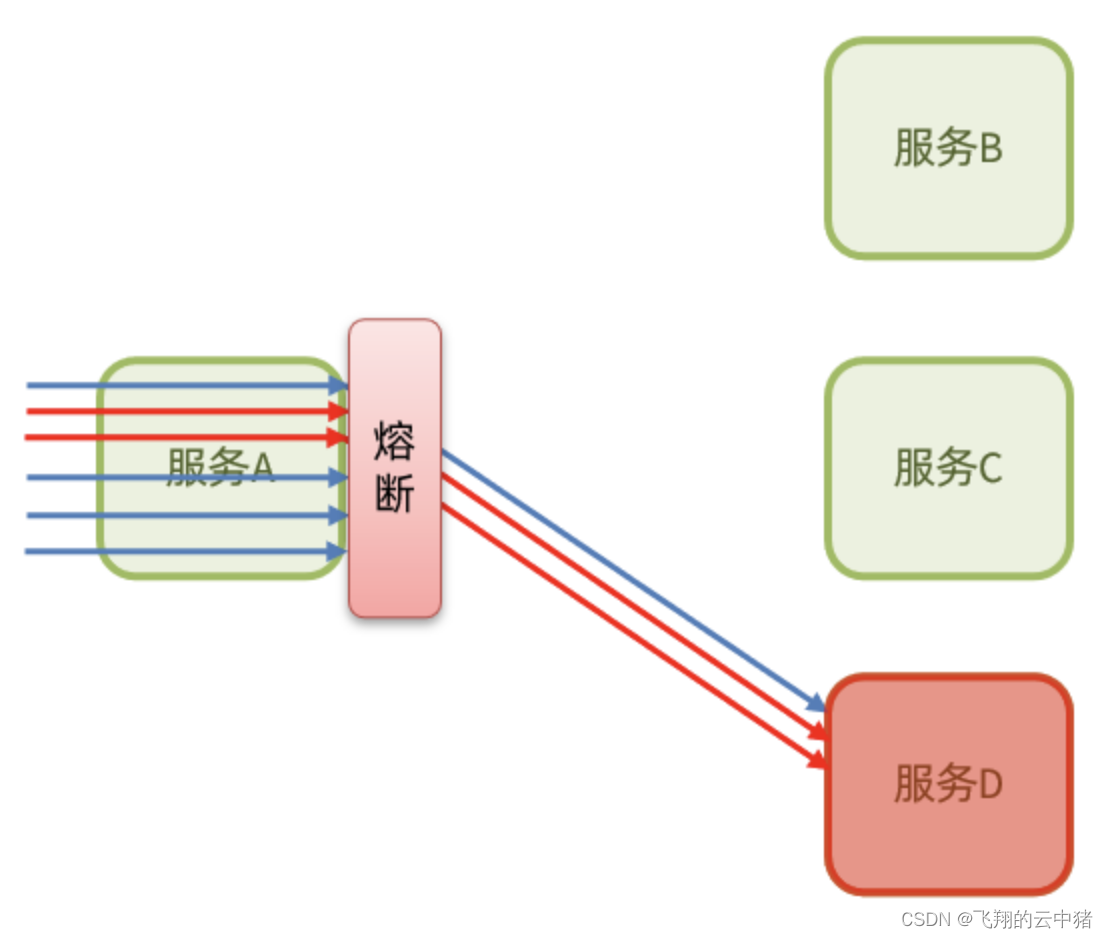
【3】熔断降级 /断路器–请求的数量超过异常的比例过高就熔断该服务【即拦击访问服务D的一切请求,直接报错】
断路器模式:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
断路器会统计访问某个服务的请求数量,当发现访问服务D的请求异常比例过高时,认为服务D有导致雪崩的风险,会拦截访问服务D的一切请求,形成熔断。
统计异常比例:
比例过高:
【4】限流–限制服务访问的每秒访问量
流量控制:限制业务访问的QPS,避免服务因流量的突增而故障。

3.总结
限流是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。是一种预防措施。
超时处理、线程隔离、降级熔断是在部分服务故障时,将故障控制在一定范围,避免雪崩。是一种补救措施。
二.服务保护技术对比
在SpringCloud当中支持多种服务保护技术。早期比较流行的是Hystrix框架,但目前国内实用最广泛的还是阿里巴巴的Sentinel框架,这里我们做下对比:
| Sentinel | Hystrix | |
|---|---|---|
| 隔离策略 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于慢调用比例或异常比例 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持慢启动、匀速排队模式 | 不支持 |
| 系统自适应保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
三.Sentinel的功能
1.簇点链路
当请求进入微服务时,首先会访问DispatcherServlet,然后进入Controller、Service、Mapper,这样的一个调用链就叫做簇点链路。簇点链路中被监控的每一个接口就是一个资源。
默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint,也就是controller中的方法),因此SpringMVC的每一个端点(Endpoint)就是调用链路中的一个资源。
Restful风格的API请求路径一般都相同,这会导致簇点资源名称重复。因此我们要修改配置,把请求方式+请求路径作为簇点资源名称:

流控、熔断等都是针对簇点链路中的资源来设置的,因此我们可以点击对应资源后面的按钮来设置规则: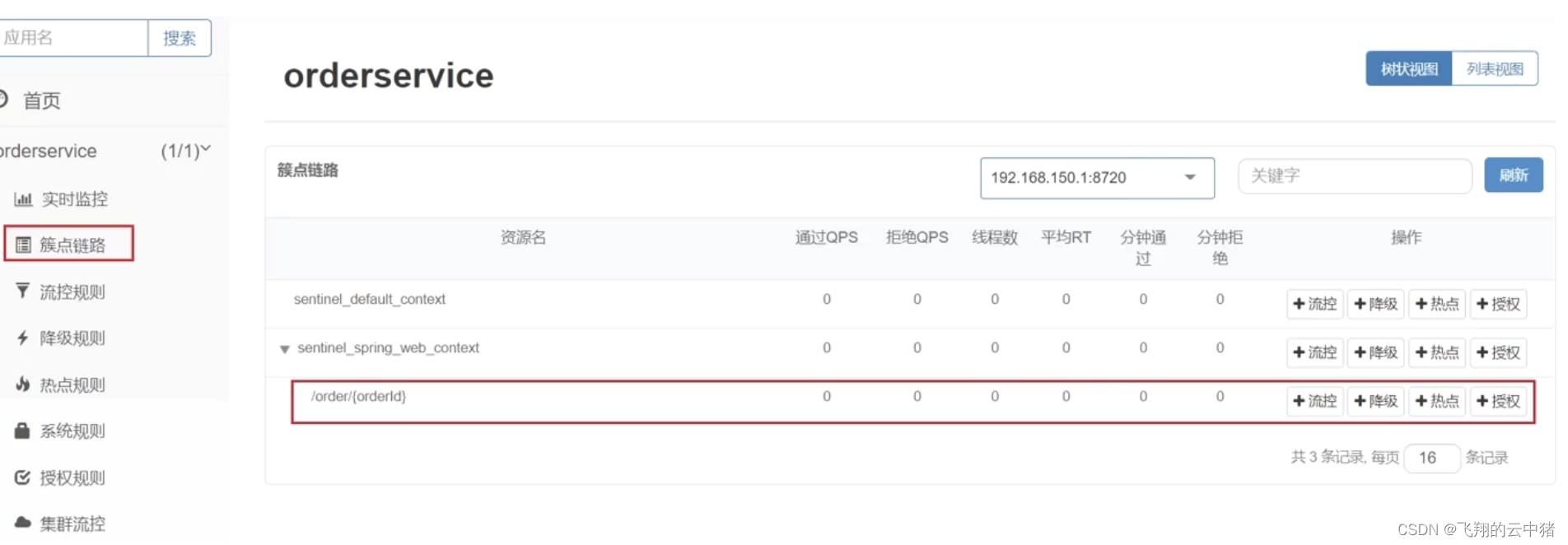
(1)流控:接口流量控制,根据接口控制每秒的访问量;
还可以进行线程隔离,控制每个服务的最大线程数量
(2)降级:降级熔断
(3)热点:热点参数限流,根据接口参数值出现频率控制每秒的访问量
(4)授权:请求的权限控制
2.流控
点击流控,进行设置,介绍一下里面提供的功能。
1.流控模式:在添加限流规则时,点击高级选项,可以选择三种流控模式:
【1】直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
【2】关联:统计与当前资源相关的另一个资源,当另一个资源触发阈值时,对当前资源限流
两个资源又竞争关系,对高优先级资源触发阈值,对低优先级资源限流。
比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是优先支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
【3】链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
2.流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
【1】快速失败:QPS超过阈值时,拒绝新的请求
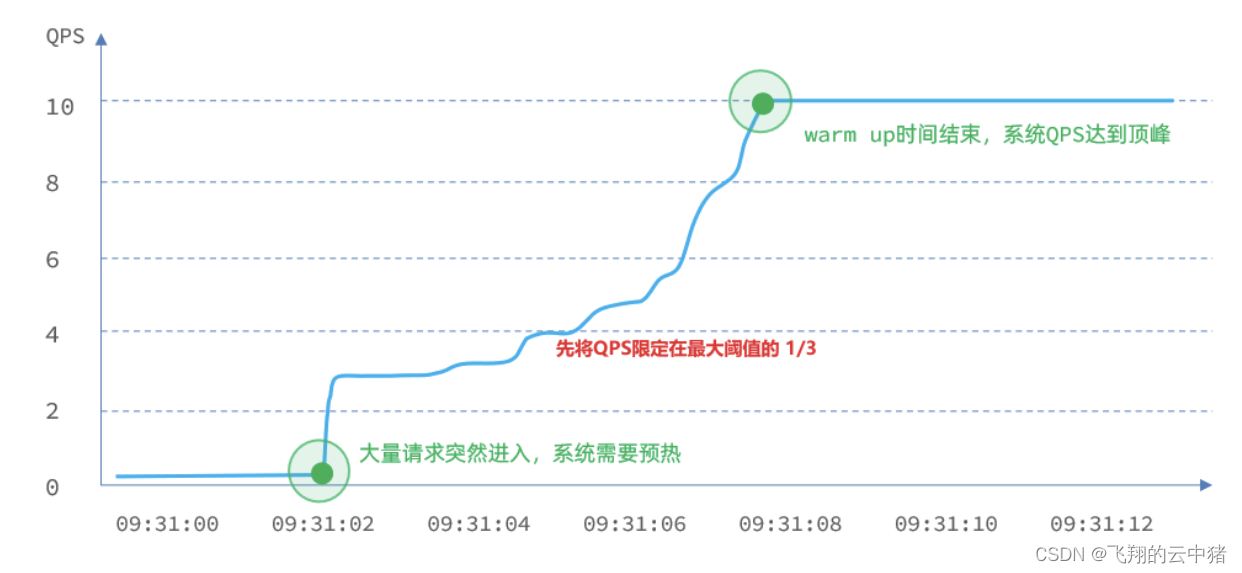
【2】warm up: QPS超过阈值时,拒绝新的请求;QPS阈值是逐渐提升的,可以避免冷启动时高并发导致服务宕机。
阈值一般是一个微服务能承担的最大QPS,但是一个服务刚刚启动时,一切资源尚未初始化(冷启动),如果直接将QPS跑到接近最大阈值,也可能导致服务瞬间宕机。
warm up也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 maxThreshold / coldFactor,持续指定时长后,逐渐提高到maxThreshold值。而coldFactor的默认值是3.
例如,设置QPS的maxThreshold为10,预热时间为5秒,那么初始阈值就是 10 / 3 ,也就是3,然后在5秒后逐渐增长到10.
【3】排队等待:请求会进入队列,按照阈值允许的时间间隔依次执行请求;如果请求预期等待时长大于超时时间,直接拒绝。
例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
那什么叫做预期等待时长呢?
比如现在一下子来了12 个请求,因为每200ms执行一个请求,那么:
第6个请求的预期等待时长 = 200 * (6 – 1) = 1000ms
第12个请求的预期等待时长 = 200 * (12-1) = 2200ms现在,第1秒同时接收到10个请求,但第2秒只有1个请求,此时QPS的曲线这样的:
如果使用队列模式做流控,所有进入的请求都要排队,以固定的200ms的间隔执行,QPS会变的很平滑:
平滑的QPS曲线,对于服务器来说是更友好的。


3.热点参数限流
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。
1.全局参数限流
例如,一个根据id查询商品的接口: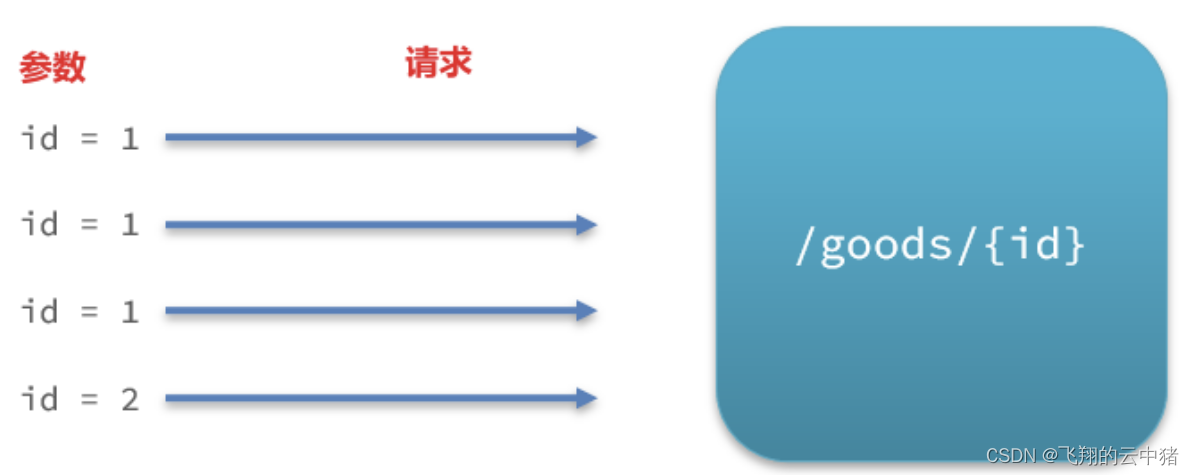
访问/goods/{id}的请求中,id参数值会有变化,热点参数限流会根据参数值分别统计QPS,统计结果:
当id=1的请求触发阈值被限流时,id值不为1的请求不受影响。
配置示例: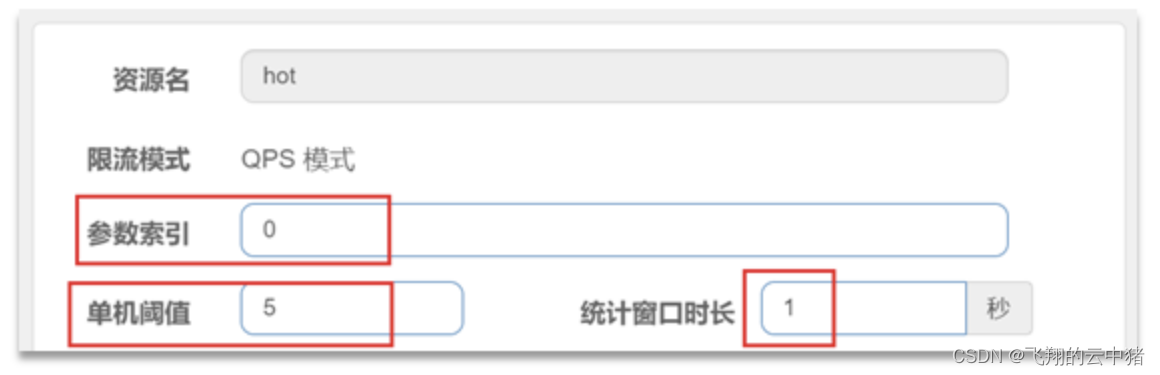
代表的含义是:对hot这个资源的0号参数(第一个参数)做统计,每1秒相同参数值的请求数不能超过5
2.热点参数限流
刚才的配置中,对查询商品这个接口的所有商品一视同仁,QPS都限定为5.
而在实际开发中,可能部分商品是热点商品,例如秒杀商品,我们希望这部分商品的QPS限制与其它商品不一样,高一些。那就需要配置热点参数限流的高级选项了:
结合上一个配置,这里的含义是对0号的long类型参数限流,每1秒相同参数的QPS不能超过5,有两个例外:
如果参数值是100,则每1秒允许的QPS为10
如果参数值是101,则每1秒允许的QPS为15
3.注意事项
热点参数限流对默认的SpringMVC资源无效,需要利用@SentinelResource注解标记资源


再对该资源进行热点参数限流.
4.隔离和降级
限流是一种预防措施,虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。
而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
可以看到,不管是线程隔离还是熔断降级,都是对客户端(调用方)的操作。需要在调用方 发起远程调用时做线程隔离、或者服务熔断。
而我们的微服务远程调用都是基于Feign来完成的,因此我们需要将Feign与Sentinel整合,在Feign里面实现线程隔离和服务熔断。
1.Feign整合Sentinel的步骤
在application.yml中配置:feign.sentienl.enable=true
补充 :Feign异常处理
业务失败后,一般不会直接报错,而是对报错进行处理,返回用户一个友好提示或者默认结果,这个就是失败降级逻辑。
给FeignClient编写失败后的降级逻辑
①方式一:FallbackClass,无法对远程调用的异常做处理
②方式二:FallbackFactory,可以对远程调用的异常做处理
具体讲讲第二种:给FeignClient编写FallbackFactory并注册为Bean
将FallbackFactory配置到FeignClient
2.线程隔离
线程隔离有两种方式实现:
【1】线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
【2】信号量隔离(Sentinel默认采用):不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
信号量隔离的特点是?
基于计数器模式,简单,开销小
线程池隔离的特点是?
基于线程池模式,有额外开销,但隔离控制更强
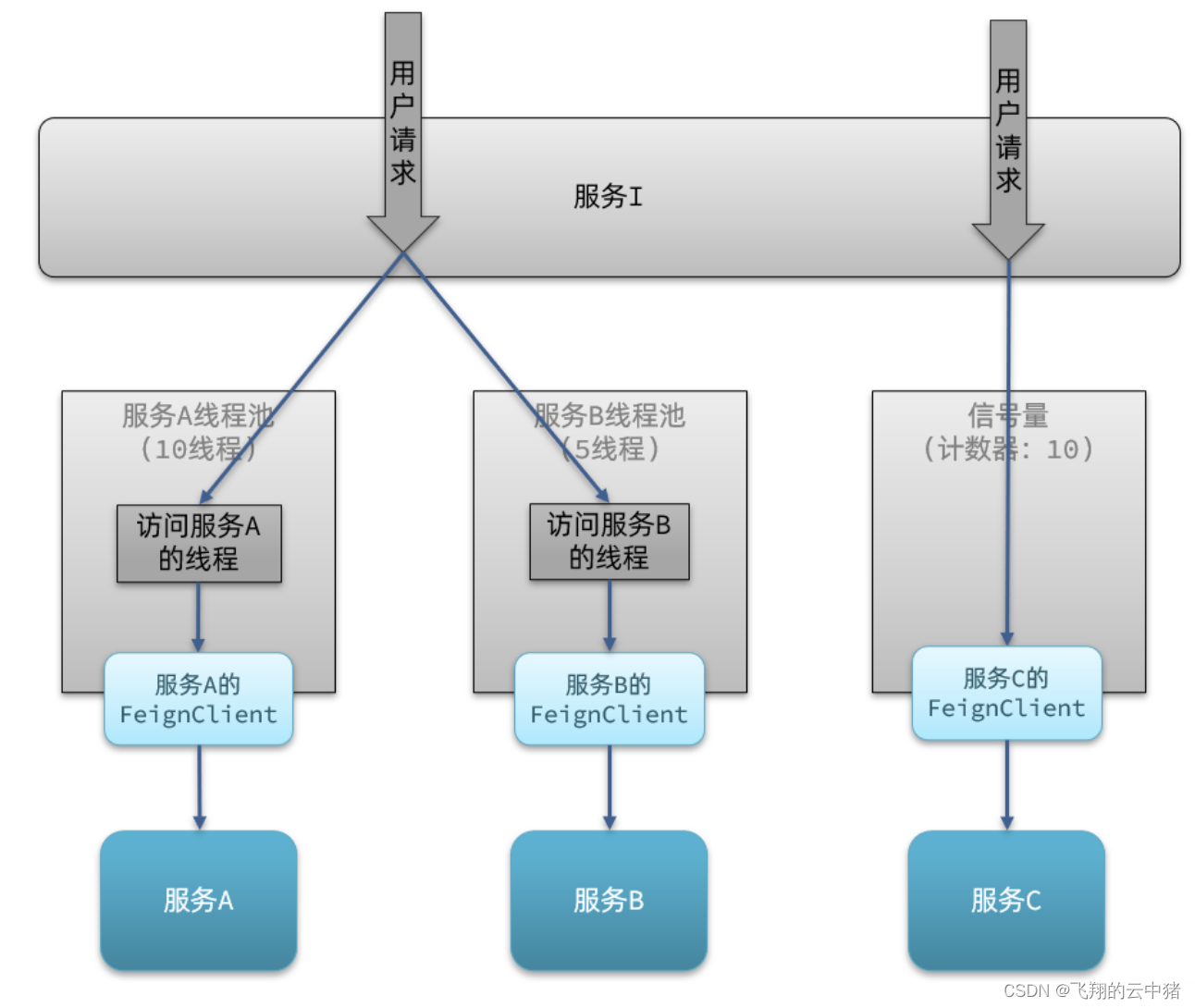
实现方式:在feign接口的资源点击流控,设置线程数。
3.熔断降级
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
1.断路器控制熔断和放行是通过状态机来完成的。
状态机包括三个状态:
【1】closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
【2】open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
【3】half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
如果请求成功,则切换到closed状态。如果请求失败:则切换到open状态
2.断路器熔断策略有三种:慢调用、异常比例、异常数
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
5.授权规则
授权规则可以对请求方来源做判断和控制。
授权规则可以对调用方的来源做控制,有白名单和黑名单两种方式。
白名单:来源(origin)在白名单内的调用者允许访问
黑名单:来源(origin)在黑名单内的调用者不允许访问
点击左侧菜单的授权,可以看到授权规则:
资源名:就是受保护的资源,例如/order/{orderId}
流控应用:是来源者的名单,如果是勾选白名单,则名单中的来源被许可访问;如果是勾选黑名单,则名单中的来源被禁止访问。
比如:

我们允许请求从gateway到order-service,不允许其他请求不通过网关直接访问order-service,那么白名单中就要填写网关的来源名称(origin)。
步骤:在网关中添加过滤器对每个请求添加名为origin,值为gateway的请求头;sentinel获取请求头判断是否值为gateway【重写RequestOriginParser接口】。
四.其他
1.sentinel异常处理
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
String msg = "未知异常";
int status = 429;
if (e instanceof FlowException) {
msg = "请求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "请求被热点参数限流";
} else if (e instanceof DegradeException) {
msg = "请求被降级了";
} else if (e instanceof AuthorityException) {
msg = "没有权限访问";
status = 401;
}
response.setContentType("application/json;charset=utf-8");
response.setStatus(status);
response.getWriter().println("{"msg": " + msg + ", "status": " + status + "}");
}
}2.规则持久化
现在,sentinel的所有规则都是内存存储,重启后所有规则都会丢失。在生产环境下,我们必须确保这些规则的持久化,避免丢失。
规则是否能持久化,取决于规则管理模式,sentinel支持三种规则管理模式:
1.原始模式:Sentinel的默认模式,将规则保存在内存,重启服务会丢失。
2.pull模式:控制台将配置的规则推送到Sentinel客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则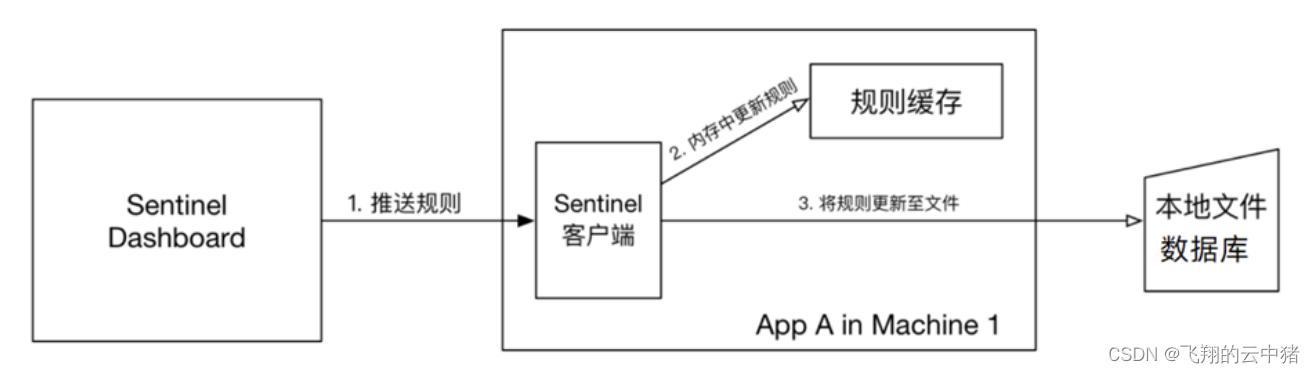
3.push模式:控制台将配置规则推送到远程配置中心,例如Nacos。Sentinel客户端监听Nacos,获取配置变更的推送消息,完成本地配置更新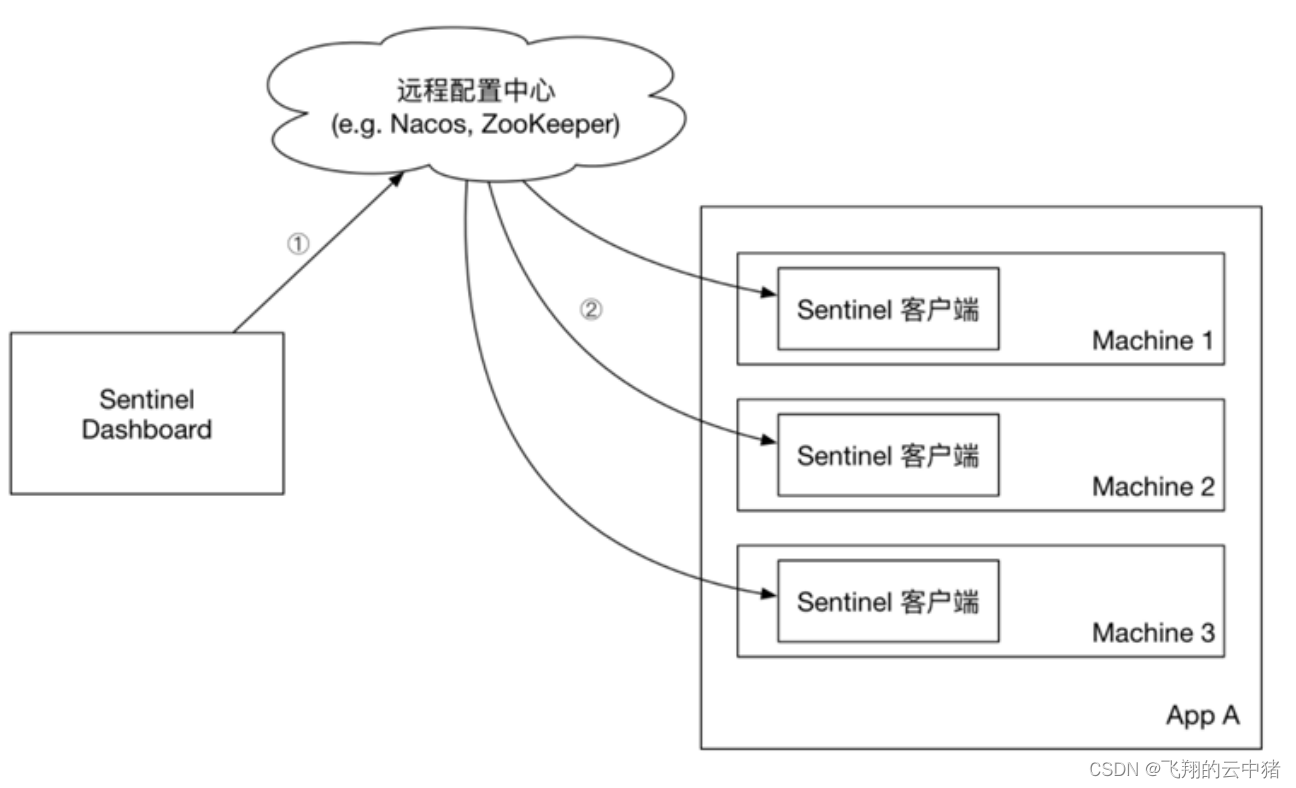
原文地址:https://blog.csdn.net/bjjx123456/article/details/135330808
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_60104.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!