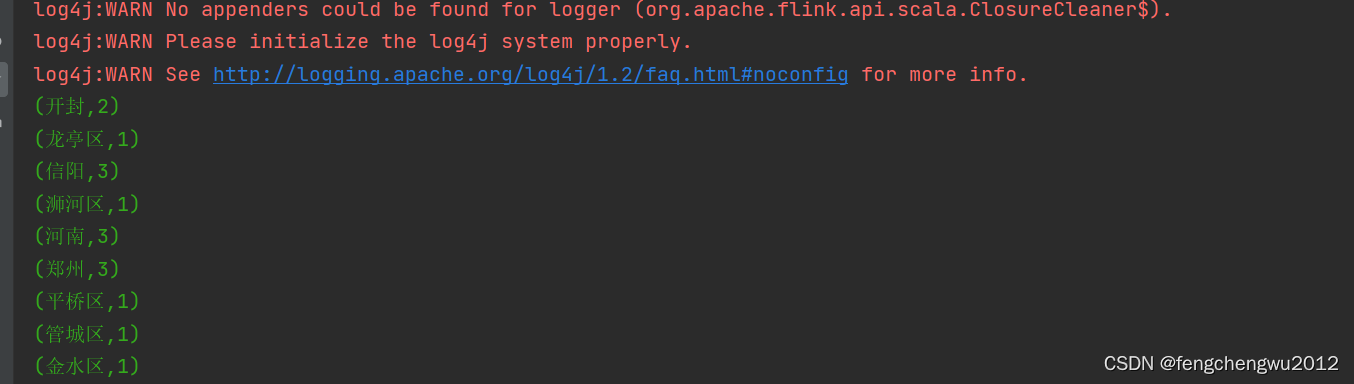
当前位置: 首页互联网正文 本文介绍: 【代码】Flink入门教程。 使用flink时需要提前准备好scala环境 一、创建maven项目 二、添加pom依赖 <properties> <scala.version>2.11.12</scala.version> </properties> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-compiler</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-reflect</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-compress</artifactId> <version>1.21</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>1.14.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.11</artifactId> <version>1.14.0</version> </dependency> 三、编码实现 准备数据源test_flink.txt 河南 郑州 河南 信阳 郑州 金水区 河南 开封 郑州 管城区 信阳 浉河区 信阳 平桥区 开封 龙亭区 编码实现 import org.apache.flink.api.scala._ import org.apache.flink.api.scala.ExecutionEnvironment object FlinkWordCount { def main(args: Array[String]): Unit = { //创建执行环境 val environment = ExecutionEnvironment.getExecutionEnvironment //读取文件 val dataSet = environment.readTextFile("D:/workplace/java-item/res/file/test_flink.txt") //将读取的字符扁平化操作,并且按照空字符分割装入到元祖之中,按照元组的第一个元素分组,分组后按照元组的第二个值求和 val aggregateDataSet = dataSet.flatMap(_.split(" ")).map((_, 1)).groupBy(0).sum(1) ///打印聚合数据 aggregateDataSet.print() } } 原文地址:https://blog.csdn.net/fengchengwu2012/article/details/135729366 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_60124.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。flinkscalaversion 代码007普通 打赏 收藏 海报 链接