1.背景
为预防大量黑客故意发起非法的时间查询请求,造成缓存击穿,建议采用布隆过滤器的方法解决。布隆过滤器通过一个很长的二进制向量和一系列随机映射函数(哈希函数)来记录与识别某个数据是否在一个集合中。如果数据不在集合中,能被识别出来,不需要到数据库中进行查询,所以能将数据库查询返回值为空的查询过滤掉。
缓存穿透: 缓存穿透是查询一个根本不存在的数据,由于缓存是不命中时需要从数据库查询,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
2.布隆过滤器介绍
1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列的随机映射函数(哈希函数)两部分组成的数据结构。
用途: 用于检索一个元素是否在一个集合中。
优点:
时间复杂度低,增加及查询元素的时间复杂度都是O(k),k为Hash函数的个数;
占用存储空间小,布隆过滤器相对于其他数据结构(如Set、Map)非常节省空间。
缺点:
存在误判,只能证明一个元素一定不存在或者可能存在,返回结果是概率性的,但是可以通过调整参数来降低误判比例;
删除困难,一个元素映射到bit数组上的k个位置为1,删除的时候不能简单的直接置为0,可能会影响到其他元素的判断。
3.原理
当一个元素加入布隆过滤器中的时候,会进行如下操作:
使用布隆过滤器中的哈希函数对元素进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
根据得到的哈希值,在位数组中把对应下标的值置为1。
当我们需要判断一个元素是否位于布隆过滤器的时候,会进行如下操作:
对给定元素再次进行相同的哈希计算;
得到值之后判断位数组中的每个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
举个例子:
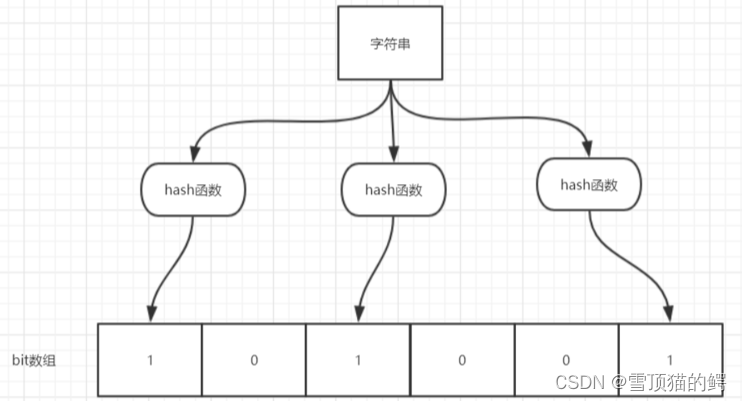
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的某个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不存在,那么这个元素一定不在。