本文介绍: 某现网ElasticSearch 故障,很长时间unassgined_shards的数量都不减少。
问题描述
某现网ElasticSearch 故障,很长时间unassgined_shards的数量都不减少。

原因分析与解决方案:
先了解整体状态,使用Postman请求,如下几个请求命令:
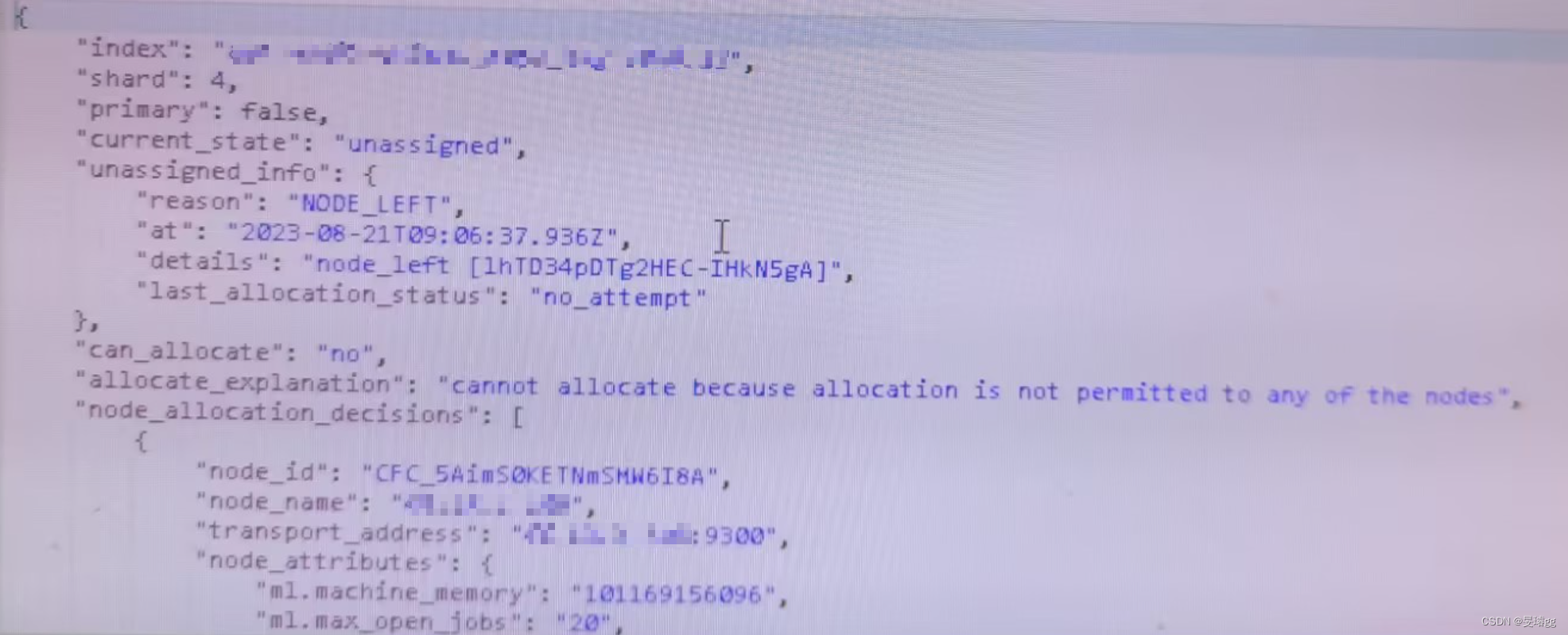
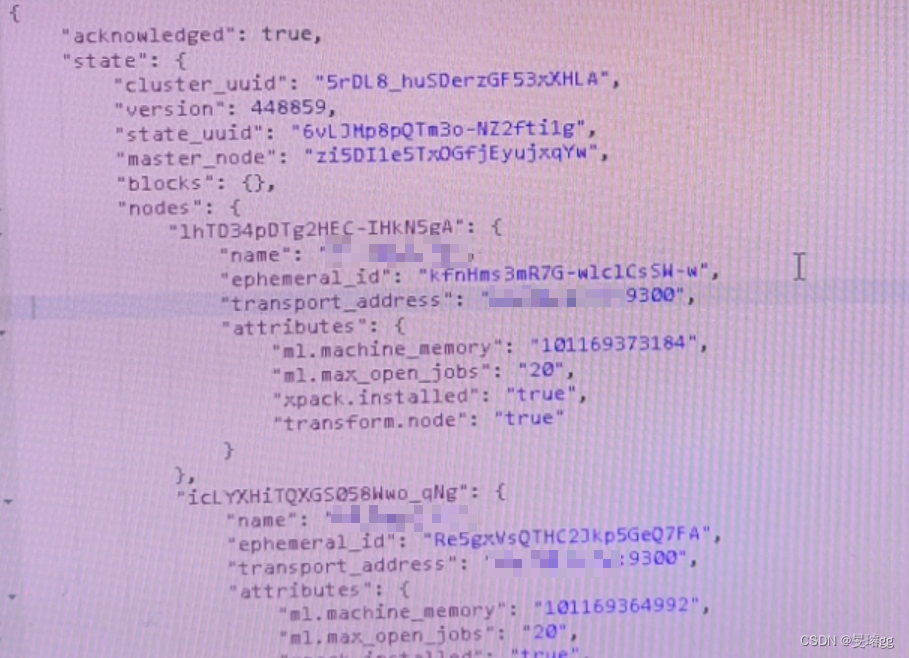
确认了分片无法指向的原因是节点磁盘使用率超过85%,即安排磁盘扩容,然后再重启ES集群解决。具体操作重启步骤:
第一步:PUT /_cluster/settings
Body里的内容:
第二步:
systemctl stop elasticsearch或kill {es的pid},注意不是kill -9
这时候要等,通过ps -ef | grep elasticsearch看进程结束没。
进程结束后,再进入第三步。
第三步:
systemctl start elasticsearch或su - esuser进入elasticsearch的bin目录,执行./elasticsearch -d命令
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。