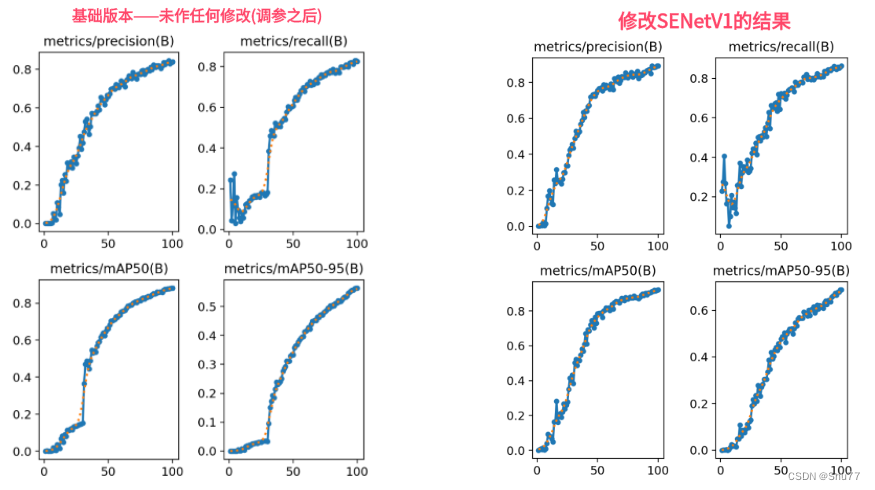
本文介绍: 前文提到的ELMo基于RNN的网络结构使得其特征提取能力弱,训练难且时间长预训练模型(仅用于特征抽取)和实际下游任务模型仍是分开的、非端到端的GPT-1基于上述缺点进行了改进。提示:以下是本篇文章正文内容,下面内容可供参考GPT-1为我们提供了一个基于 Transformer 的可以微调的预训练网络。但是在把 BiLSTM 换成 Transformer 的过程中,有信息丢失。ELMo 的语言模型是双向的,可以融合上下文信息,但GPT-1只能向前看,即只能利用上文信息、不能利用下文信息。
前言
前文提到的ELMo虽然解决了词嵌入多义词的问题,但存在如下缺点:
GPT-1基于上述缺点进行了改进。
提示:以下是本篇文章正文内容,下面内容可供参考
一、GPT-1网络结构和流程
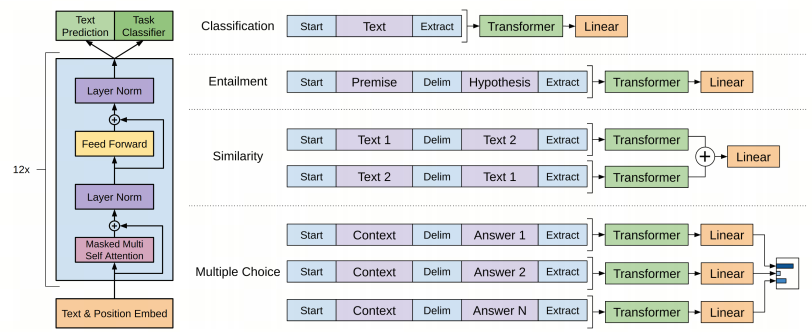
网络结构方面,GPT-1使用Transformer Decoder(不包含Encoder-Decoder Attention)代替了BiLSTM
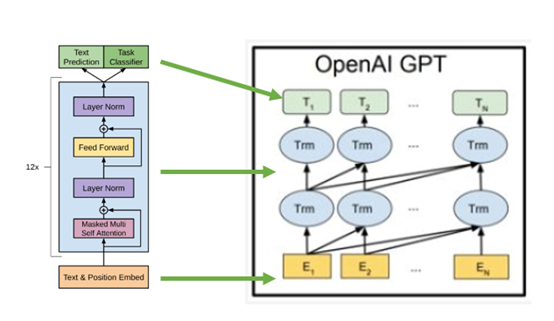
基于GPT-1的NLP任务分为两个阶段:
二、GPT-1的创新点
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。