
前言
Redis作为一款高性能的缓存数据库,被广泛应用于各种互联网应用中。然而,在使用过程中,我们可能会遇到一些常见问题,如缓存穿透、缓存击穿、缓存雪崩等。如果忽视这些情况可能会带来灾难性的后果,下面主要对这些缓存异常和常见处理方案进行相应分析与总结。
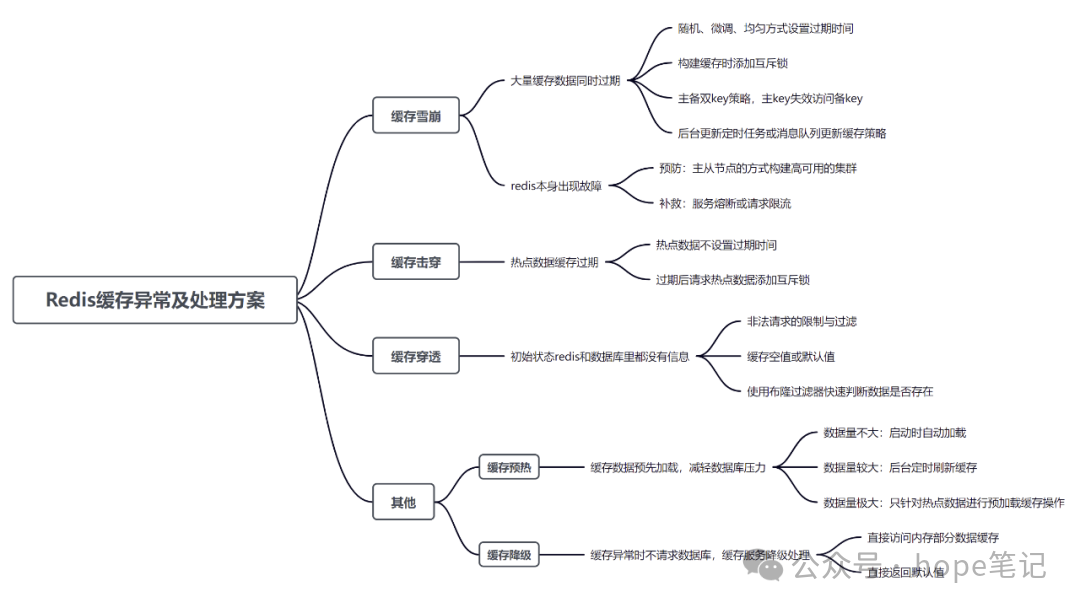
一、缓存击穿
Redis缓存击穿是指当Redis缓存中没有数据,但数据库中存在数据的情况。当多个并发请求都去查询数据库而没有查询到数据,这就使得数据库的压力非常大,从而导致系统性能下降,甚至出现系统崩溃的现象。
缓存击穿通常在热点数据过期和高并发请求的情况下发生。具体如下:
-
热点数据过期:当某个被频繁访问的数据(即热点数据)在缓存中因过期或被手动删除而不再可用时,如果此时有大量的并发请求尝试查询该数据,这些请求会发现缓存中没有所需数据,于是同时去查询后端系统,如数据库,导致数据库压力骤增。
-
高并发请求:在某些事件触发的瞬间,比如电商网站的秒杀活动开始时刻,大量用户会同时请求同一个商品的信息,如果这个商品信息刚好从缓存中失效,就会造成缓存击穿现象。
Redis缓存击穿的解决方案
为了解决Redis缓存击穿问题,我们可以采用以下几种解决方案:
1. 使用互斥锁
在查询数据之前,我们可以使用互斥锁来保证同一时间只有一个请求去查询数据库。当查询请求获取到锁之后,如果Redis中没有数据,则去查询数据库并将查询结果存入Redis中。这样可以避免多个请求同时去查询数据库。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class CachePenetrationSolution {
private Lock lock = new ReentrantLock();
public String getDataFromDBAndCache(String key) {
lock.lock();
try {
// 模拟从数据库查询数据
String data = queryFromDB(key);
// 更新缓存
updateCache(key, data);
return data;
} finally {
lock.unlock();
}
}
private String queryFromDB(String key) {
// 模拟从数据库查询数据的过程
return "data";
}
private void updateCache(String key, String data) {
// 模拟更新缓存的过程
}
}2. 使用分布式锁
当系统规模较大时,可以考虑使用分布式锁。分布式锁可以在多个节点之间进行同步,从而避免数据不一致的问题。在使用分布式锁时,需要考虑到锁的粒度和性能问题。
3. 使用空对象缓存
为了避免Redis缓存击穿问题,可以在Redis中存储一个空对象作为默认值。当查询请求没有查询到数据时,可以先将空对象作为默认值存入Redis中,然后再去查询数据库。这样可以减少对数据库的访问次数,提高系统的性能。
4. 使用读写锁
读写锁是一种特殊的互斥锁,它可以允许多个读请求同时访问共享资源,但只允许一个写请求访问共享资源。使用读写锁可以避免多个读请求同时去查询数据库,从而提高系统的性能。
5. 使用布隆过滤器
布隆过滤器是一种空间效率极高的概率型数据结构,用于判断一个元素是否在一个集合中。通过使用布隆过滤器,我们可以在不损失准确性的情况下过滤掉过期的数据请求。
public boolean isHotDataExist(String key) {
return bloomFilter.mightContain(key);
}二、缓存穿透
缓存穿透是指数据既不在redis中,也不在数据库中,这样就导致每次请求过来的时候,在缓存中找不到对应key之后,每次都还要去数据库再查询一遍,发现数据库也没有,相当于进行了两次无用的查询。这样请求就可以绕过缓存直接查数据库,如果这个时候有人想恶意攻击系统,就可以故意使用空值或者其他不存在的值进行频繁请求,那么就会对数据库造成比较大的压力。
这种现象的原因其实很好理解,业务逻辑里面如果用户对某些信息还没有进行相应的操作或者处理,那对应的存放信息的数据库或者缓存中自然也就没有相应的数据,也就容易出现上述问题。
缓存穿透通常发生在以下几种情况:
-
恶意攻击:攻击者通过构造大量的不存在的key,使得这些key在缓存中不存在,从而绕过缓存直接访问数据库,对数据库造成压力。
-
缓存和数据库数据不一致:由于缓存中的数据和数据库中的数据存在不一致的情况,导致查询时无法命中缓存,进而访问数据库。
Redis缓存穿透解决方案
1. 数据预热
在系统启动或者有热点数据发生改变的时候,直接将这些数据加载到缓存中。这样,当系统运行时,热点数据就能够直接从缓存中获取,避免了对数据库的查询操作。可以使用定时任务或者消息队列等方式实现数据预热。
2. 缓存空对象
当某个缓存数据为空的时候,也需要将其缓存起来,避免因为缓存穿透而导致数据库被频繁查询。具体实现方式可以为:在缓存中设置一个特殊的空对象,当缓存中不存在该数据时,直接返回该空对象。这样,当下次需要查询该数据时,可以直接从缓存中获取到该空对象,而不需要对数据库进行查询。
3. 数据库查询过滤
为了避免缓存穿透对数据库造成影响,可以在查询数据库之前进行过滤操作。例如,使用布隆过滤器(Bloom Filter)对查询参数进行过滤,判断该参数是否可能存在于数据库中。如果判断为可能存在,再对数据库进行查询操作。这样可以减少对数据库的查询次数,提高系统的性能和稳定性。
4. 缓存过期时间策略
为了避免缓存穿透问题,可以为缓存设置合理的过期时间。当一个缓存数据在过期时间内没有被访问到,该缓存数据就会自动失效。这样,当新的请求需要访问该数据时,就需要重新查询数据库并更新缓存。这种方式可以有效地减少对数据库的查询次数,同时避免缓存穿透问题。
5. 使用互斥锁
当多个线程或进程需要访问同一份缓存数据时,可以使用互斥锁来保证同一时间只有一个线程或进程能够访问该数据。这样可以避免多个线程或进程同时对数据库进行查询操作,从而提高系统的性能和稳定性。在使用互斥锁时,需要注意避免死锁和性能问题。
6. 缓存降级
当缓存出现问题或性能下降时,可以采用缓存降级的方式降低系统的压力。具体实现方式可以为:将部分热点数据暂时切换到数据库中查询,降低缓存的负载压力。同时,可以采用异步的方式对切换的数据进行重新加载,保证数据的实时性和一致性。
7. 缓存热点数据
对于一些热点数据,可以采用持久化缓存的方式将其存储在Redis中。这样可以避免因为缓存过期而导致对数据库的频繁查询。同时,可以采用LRU(Least Recently Used)算法等方式对热点数据进行淘汰处理,保证缓存的容量和性能。
8. 关闭慢查询日志
通过修改 Redis 配置文件,关闭慢查询日志功能,可以有效防止攻击者利用慢查询日志消耗服务器资源。但需要注意的是,这样做可能会影响我们对异常情况的监控和排查。
slowlog-log-slower-than = 1000 # 设置慢查询阈值为1000毫秒(1秒)
三、缓存雪崩
一段时间内本应在redis缓存中处理的大量请求,都发送到了数据库进行处理,导致对数据库的压力迅速增大,严重时甚至可能导致数据库崩溃,从而导致整个系统崩溃,就像雪崩一样,引发连锁效应,所以叫缓存雪崩。
缓存雪崩通常发生在以下几种情况:
-
服务器宕机:如果Redis服务器宕机,那么所有的缓存数据都将不可用,这会导致所有请求都会直接打到数据库上。
-
设置了相同的过期时间:如果对缓存数据设置了相同的过期时间,那么在过期时间到达时,这些数据会同时失效,同样会导致大量请求直接访问数据库。
Redis缓存雪崩解决方案
1. 数据持久化
为了避免缓存雪崩问题,可以将缓存数据持久化到磁盘上。这样,即使Redis服务器出现故障,数据也不会丢失。可以使用RDB或AOF持久化方式实现数据持久化。在持久化时,需要设置合理的过期时间,以保证缓存数据的可用性和稳定性。
2. 使用Redis集群
Redis集群可以将数据分散到多个Redis实例中,实现负载均衡和数据高可用性。在集群模式下,每个节点都负责一部分数据,如果某个节点发生故障,其他节点还可以正常提供服务。这样可以避免缓存雪崩问题,提高系统的可用性和稳定性。
3. 设置合理的过期时间
为了避免缓存雪崩问题,可以为缓存设置合理的过期时间。当缓存过期后,数据会被自动删除,如果此时有新的请求需要访问该数据,就需要重新从数据库中查询并更新缓存。这样可以避免大量缓存同时失效而导致缓存雪崩问题。
4. 使用缓存淘汰策略
当缓存空间不足时,可以采用一些淘汰策略来避免缓存雪崩问题。常见的策略有LRU(Least Recently Used)和LFU(Least Frequently Used)等。这些策略可以有效地删除不常用或长时间未使用的数据,保证缓存的空间和可用性。
5. 限流与熔断
为了避免缓存雪崩问题,可以对请求进行限流和熔断操作。限流可以限制对Redis服务器的请求数量,熔断则可以在缓存失效时直接返回空数据或错误信息,避免对Redis服务器造成过大的压力。可以使用一些开源的限流和熔断工具实现这些功能。
6. 备份和灾难恢复
在设计和实施Redis缓存时,应该考虑备份和灾难恢复方案。可以定期备份Redis中的数据,并将备份存储在可靠的存储设备上。当发生故障时,可以从备份中恢复数据,保证服务的可用性和稳定性。同时,也可以采用一些高可用性的方案,如主从复制和故障切换等,提高系统的可用性和稳定性。
7. 代码优化
在代码层面,可以采用一些优化措施来避免缓存雪崩问题。例如,合理地使用缓存和数据库查询的组合方式,避免对同一个数据的重复查询和缓存操作。同时,可以采用异步的方式处理一些请求,减轻对Redis服务器的压力。在编写代码时,应该遵循最佳实践和规范,保证代码的质量和稳定性。
// 限流
public void rateLimiter() {
RateLimiter rateLimiter = RateLimiter.create(1000); // 每秒处理1000个请求
while (true) {
if (rateLimiter.tryAcquire()) {
// 处理请求逻辑
rateLimiter.release(); // 释放令牌
} else {
// 限流逻辑处理失败,可以进行重试或返回错误信息
}
}
}8. 监控和告警
最后,应该对Redis服务器进行监控和告警设置。监控可以实时监测Redis服务器的状态和性能指标,发现异常情况及时报警和处理。同时,可以使用一些可视化的监控工具来帮助分析和解决缓存雪崩问题。
结语
本文针对Redis缓存中的常见问题进行了分析,并提出了相应的优化方案。通过使用布隆过滤器解决缓存穿透问题、使用互斥锁解决缓存击穿问题以及采取多种策略解决缓存雪崩问题,我们可以有效地提高Redis缓存的性能和稳定性。

原文地址:https://blog.csdn.net/weixin_40381772/article/details/135746169
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_60747.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





