大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用33零门槛实现模型在多个GPU的分布式流水线训练的应用技巧,本文将帮助大家零门槛的实现模型在多个GPU的并行训练,如果你手头上没有GPU资源,根据本文的介绍也可实现模型的并行,让大家了解模型的并行是怎么实现的,揭开模型分布式训练的神秘面纱,提升自己的模型训练水平。在大规模语言模型训练领域迈进自己的脚步。

一、 神经网络模型并行的介绍
神经网络模型并行广泛应用于分布式训练技术中,本文展示了如何通过使用模型并行来解决多个GPU训练的问题,与DataParallel不同,模型并行将单个模型分割到不同的GPU上,而不是将整个模型复制到每个GPU上(假设一个模型M包含10层:使用DataParallel时,每个GPU将拥有这10层的副本,而在使用模型并行在两个GPU上时,每个GPU可能托管5层)。
模型并行的思想是将模型的不同子网络放置到不同的设备上,并相应地实现前向方法以跨设备移动中间输出。由于只有模型的某部分在单个设备上运行,因此一组设备可以共同服务于更大的模型。本文的的重点是将模型并行的思路展示给大家。
分布式流水线模型训练
分布式模型训练通常指的是在多个计算节点上并行地训练机器学习模型。这种训练方式可以提高模型训练的速度,尤其是在处理大规模数据集和复杂模型时。分布式训练可以通过不同的并行策略来实现,例如数据并行、模型并行、流水线并行等。以下是这些并行策略的一些基本数学原理:
1.数据并行(Data Parallelism):
数据并行是最常见的并行策略。在这种策略中,训练数据被分成多个部分,每个计算节点(或设备)独立地在自己的数据部分上训练完整的模型,并定期同步参数更新。
假设我们有一个损失函数
L
(
θ
)
L(theta)
L(θ),其中
θ
theta
θ 是模型参数。在数据并行中,每个节点计算损失和梯度:
分布式流水线模型训练
∇
θ
L
k
(
θ
)
=
∂
L
k
(
θ
)
∂
θ
nabla_{theta} L_k(theta) = frac{partial L_k(theta)}{partial theta}
∇θLk(θ)=∂θ∂Lk(θ)
其中
L
k
L_k
Lk 是第
k
k
k 个节点上的损失函数。参数更新可以通过平均所有节点的梯度来实现:
θ
←
θ
−
α
1
N
∑
k
=
1
N
∇
θ
L
k
(
θ
)
theta leftarrow theta – alpha frac{1}{N} sum_{k=1}^{N} nabla_{theta} L_k(theta)
θ←θ−αN1k=1∑N∇θLk(θ)
其中
α
alpha
α 是学习率,
N
N
N 是节点数。
2.模型并行(Model Parallelism):
当模型太大以至于无法放入单个设备的内存时,可以使用模型并行。在这种策略中,模型的不同部分被放置在不同的计算节点上。每个节点只负责模型的一部分,所有节点协同工作以完成整个前向和后向传播。
3.流水线并行(Pipeline Parallelism):
流水线并行将模型分成几个部分,并且每个部分由不同的计算节点处理。这些节点按流水线的方式工作,即一个节点处理一部分输入并将结果传递给下一个节点,以此类推。这种方式可以减少延迟并提高设备利用率。
二、构建两个GPU的环境
很多人可能设备环境都没有GPU,下面我介绍在kaggle平台上实现模型并行,环境选择加速器选择GPU T4*2。
现在从一个包含两个线性层的模型开始,为了在两个GPU设备上运行这个模型,我们只需将每个线性层放置在不同的GPU上,并根据层的设备相应地移动输入和中间输出。
import torch
import torch.nn as nn
import torch.optim as optim
# 检查是否有可用的GPU
if torch.cuda.is_available():
# 输出GPU数量
print(f"Number of GPUs available: {torch.cuda.device_count()}")
# 输出当前GPU的名称
for i in range(torch.cuda.device_count()):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
else:
print("No GPU available.")
class MainModel(nn.Module):
def __init__(self):
super(MainModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
model = MainModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()
运行后,我们看到两台GPU信息
Number of GPUs available: 2
GPU 0: Tesla T4
GPU 1: Tesla T4
三、将模型并行应用于现有模块
这里我们需要将torchvision.models.resnet50()分解到两个GPU上。从现有的ResNet模块继承,并在构造过程中将层分割到两个GPU上。然后,重写前向方法,通过相应地移动中间输出,将两个子网络拼接起来。
from torchvision.models.resnet import ResNet, Bottleneck
import torch.nn as nn
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
单个模型训练与并行模型时间比较
import torchvision.models as models
import matplotlib.pyplot as plt
plt.switch_backend('Agg')
import numpy as np
import timeit
import torch.nn as nn
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def train(model):
model.train(True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size)
.random_(0, num_classes)
.view(batch_size, 1)
for _ in range(num_batches):
# generate random inputs and labels
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes)
.scatter_(1, one_hot_indices, 1)
# run forward pass
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
# run backward pass
labels = labels.to(outputs.device)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
num_repeat = 10
stmt = "train(model)"
setup = "model = ModelParallelResNet50()"
mp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
mp_mean, mp_std = np.mean(mp_run_times), np.std(mp_run_times)
setup = "import torchvision.models as models;" +
"model = models.resnet50(num_classes=num_classes).to('cuda:0')"
rn_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
rn_mean, rn_std = np.mean(rn_run_times), np.std(rn_run_times)
def plot(means, stds, labels, fig_name):
fig, ax = plt.subplots()
ax.bar(np.arange(len(means)), means, yerr=stds,
align='center', alpha=0.5, ecolor='red', capsize=10, width=0.6)
ax.set_ylabel('ResNet50 Execution Time (Second)')
ax.set_xticks(np.arange(len(means)))
ax.set_xticklabels(labels)
ax.yaxis.grid(True)
plt.tight_layout()
plt.savefig(fig_name)
plt.close(fig)
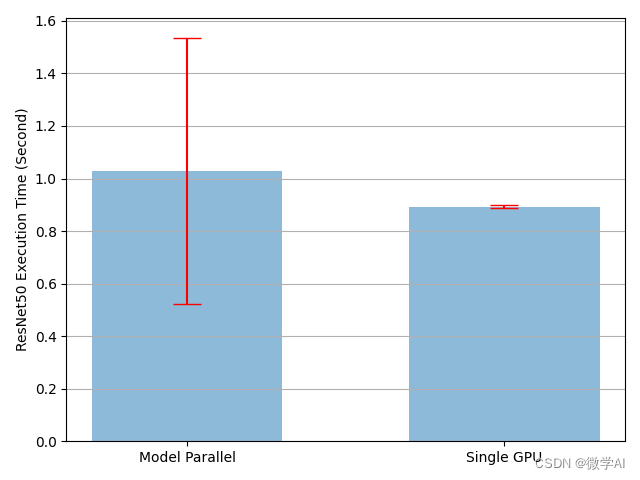
plot([mp_mean, rn_mean],
[mp_std, rn_std],
['Model Parallel', 'Single GPU'],
'mp_and_rn.png')
运行结果如图:
通过流水线输入加速的比较
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. ``s_prev`` runs on ``cuda:1``
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. ``s_next`` runs on ``cuda:0``, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
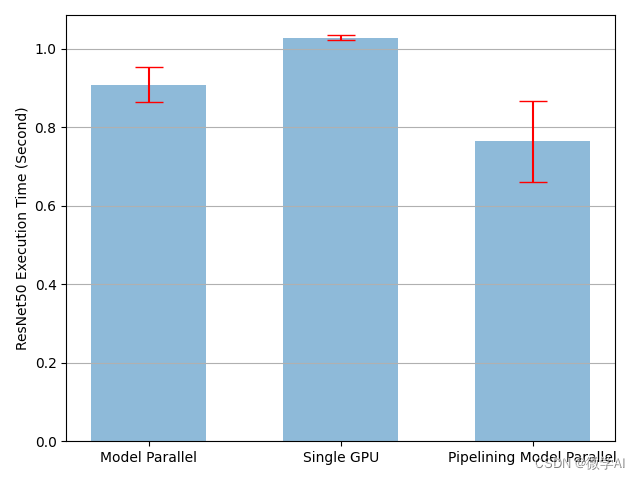
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_and_rn_and_pp.png')
运行结果如图:
我们需要注意的是:设备到设备的张量复制操作会在源设备和目标设备上的当前流上同步。如果您创建了多个流,您必须确保复制操作得到适当的同步。在复制操作完成之前写入源张量或读取/写入目标张量可能会导致未定义的行为。上述实现的只在源设备和目标设备上都使用默认流,因此不需要强制额外的同步。
原文地址:https://blog.csdn.net/weixin_42878111/article/details/135772245
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_60861.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






